In this blog post we will look at the technical underpinnings beneath the Domain Name System (DNS) that provides the address resolution used globally to support the use of memorable host and domain names on the Internet. DNS is the mechanisms, protocols, services, and systems that make the internet address space usable and memorable for humans. We will look at how the DNS system developed, as well as how some of the decisions taken in establishing the protocols used for DNS, leave it vulnerable to certain exploits. Finally, we will cover some of the more esoteric exploits using the protocol that have since been discovered or developed by researchers and hackers, as well as what can be done to ensure that DNS implementations and usages are suitably secured wherever possible.
The Internet as we all know and use on a daily basis relies upon a number of underlying protocols for communication. These operate at different layers of the network “stack”, with data being encoded and passed down from systems operating at one layer to the next, an abstraction that simplifies the development and implementation of individual services since the operation of underlying services that it relies on doesn’t need to be understood in great detail – data can simply be entrusted to lower network layers for transmission and routing. Network stacks are typically modelled conceptually as a 7-layer stack under the widely known “OSI” model, however the Internet operates functionally on something more resembling a 5-layer model, incorporating a protocol stack known as the internet protocol suite. The key concept is that hardware or software systems functioning at a given layer only need to communicate with adjacent (vertical) layers in order to perform their dedicated function or task: software running in a higher layer does not have to know about or perform tasks delegated to lower layer functions and vice versa. The key layer used for host-to-host routing that underpins the operation of the Internet is the Network Layer based upon the Internet Protocol (IP).
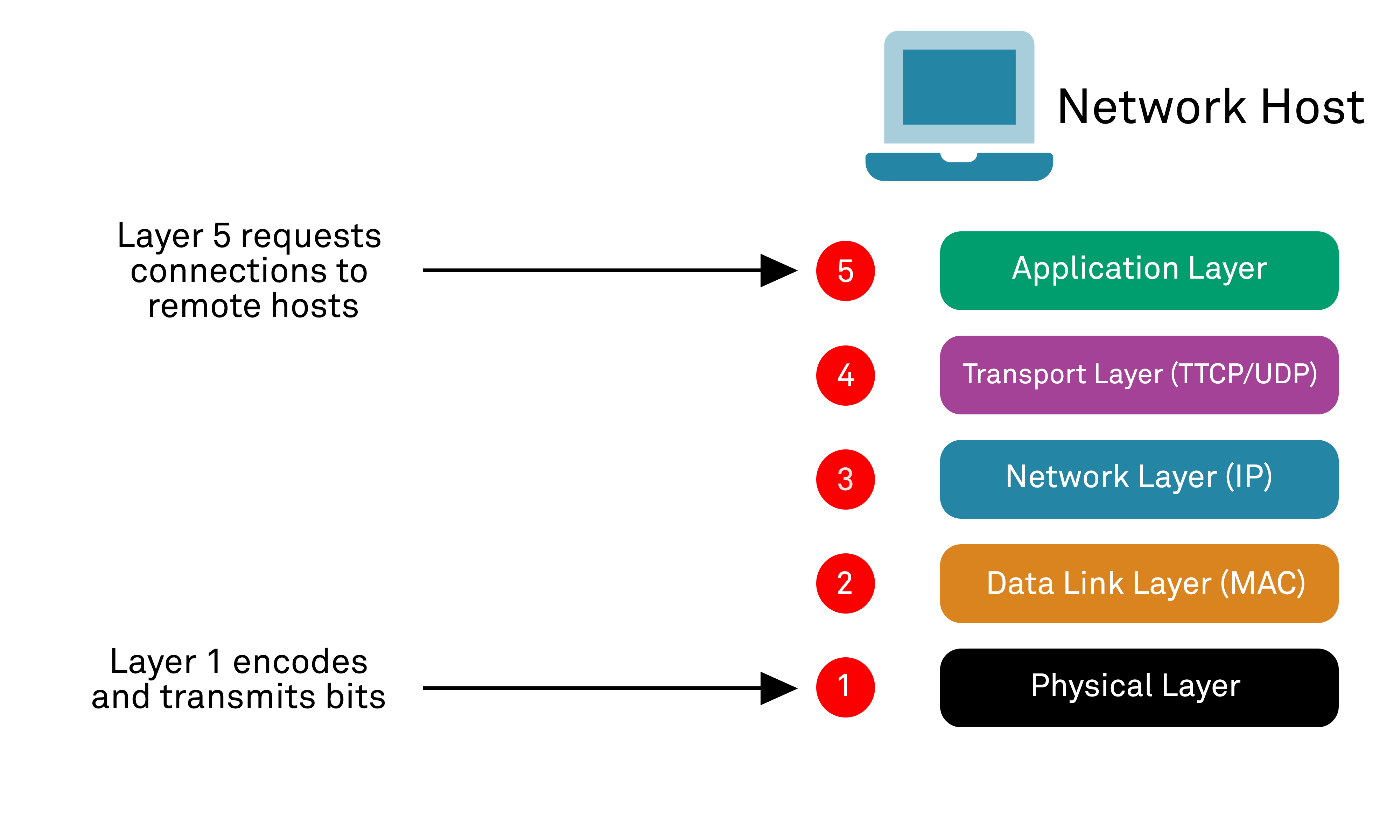
Critically, IP uses a connectionless service to dynamically route and deliver discrete datagram packets between source and destination hosts based on numerical IP addresses. The addresses can be assigned to ranges such that routing tables on any given routing device can be kept relatively short and simple and not need to contain discrete entries for every single IP address that exists (over 4 billion unique addresses under version 4 of the IP protocol) – only for the “next hop” endpoint that is needed on a datagram’s path towards its destination. An analogy might be motorway road sign systems – each road sign doesn’t contain distances and directions to every single town and village in the UK, only the next major “hop” in a given direction as well as a “catch all”: for instance, “Nottingham, The SOUTH”.
Whilst this system is technically solid, the numerical addresses used for Internet routing – consisting of a quartet of dot-separated octets such as “192.27.14.224” under IPv4 (and even longer strings under newer versions of the IP protocol) do not lend themselves readily to human usage and memorisation: they are incredibly hard to remember in any significant number since for humans they are, essentially, lacking in context and meaning.
Humans prefer to work with memorable names, and since the earliest days of the Internet and preceding ARPANET in the 1970s, efforts were therefore made to provide systems to deliver mapping between these memorable names (for humans) and the underlying IP addresses (for computers) to which they relate. Initial efforts at manually maintaining and updating directories of every hostname to IP address mapping centrally swiftly became unmanageable as ARPANET developed into or was succeeded by the internet.
The translation between addresses and domain names is now performed primarily by services based upon the Domain Name System (DNS). This effectively acts as a giant distributed directory of name to IP address mappings. The directory contents are termed the domain name space and exists as a distributed tree data structure in that it is hierarchical and split into cascading series of zones beginning with the root zone – an individual hostname consists of a dot-delimited chain of labels, in the form [hostname].[domain].[domain]….
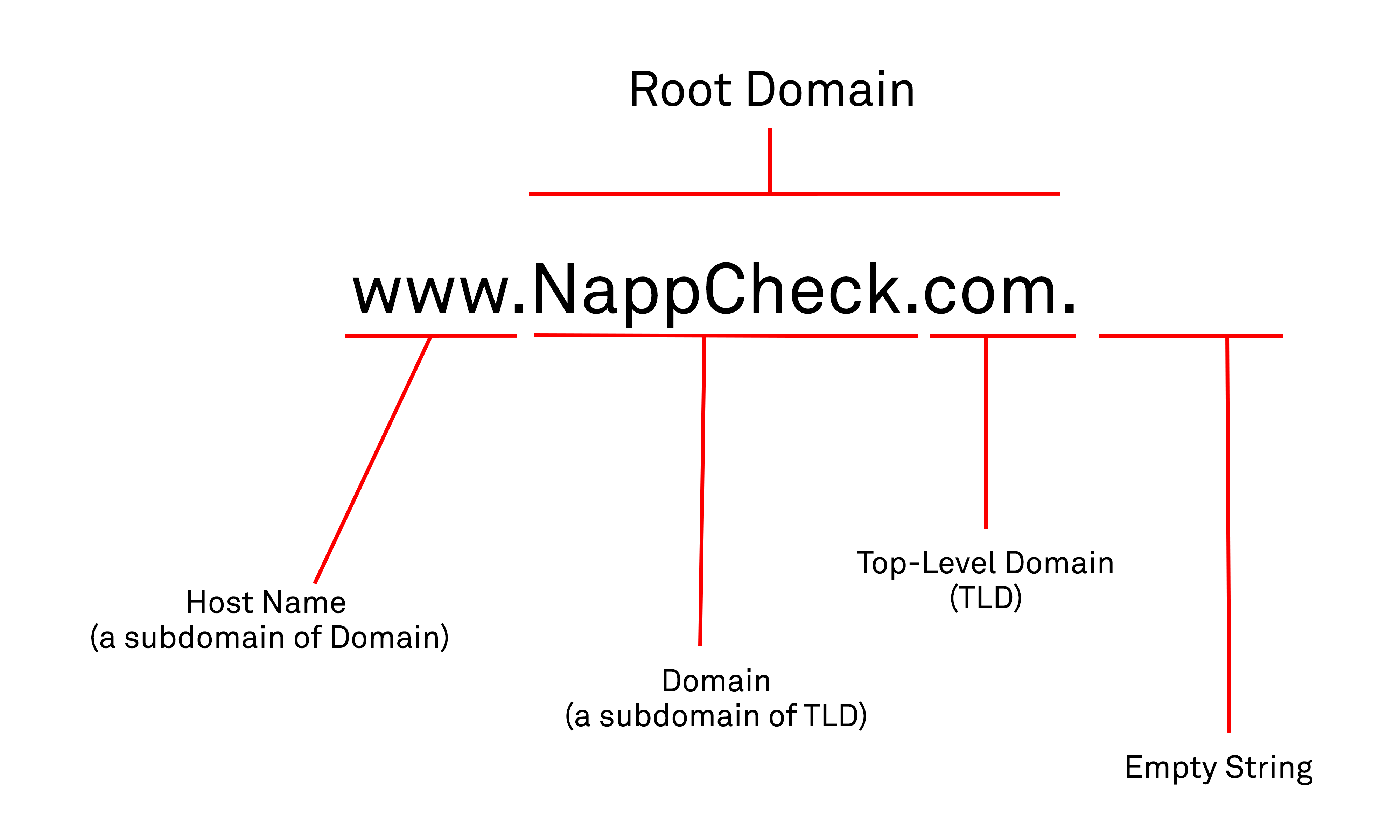
Queries to perform lookups (such as resolving names to IP addresses and vice versa) are performed by clients against name servers that maintain the records for a specific zone. Since administrative responsibility for the maintenance of the “name to address” mappings within a zone are handed over at each level of the tree to a discrete party responsible for that zone, the system is distributed and no one central party is burdened with maintaining an unmanageable number of records. Each domain has at least one authoritative DNS server that publishes information about that domain and the name servers of any domains subordinate to it, and which can be queried by clients in order to perform directory lookups such as resolving a given name into an IP address. The top of the hierarchy is served by root name servers, the servers to query when looking up (resolving) a Top Level Domain (TLD).
The original DNS specifications date right back to the mid-1980s and despite revisions and updates since, many of the core design decisions date back some thirty years or more. Many of the issues with DNS security stem from this historical context, and the operating environment at the time when the networks over which it was used were only accessible by a few trusted parties such as universities and research centres rather than being open for participation by the general public – decisions that would be unlikely if implementing a new protocol in the modern era.
For example, DNS has primarily operated over the User Data Protocol (UDP) as its transport protocol – inherently DNS communicates without transport-layer encryption (i.e. sent in clear text) and without a mechanism for authentication, or delivery guarantee, or an implementation cap on message length.
In this original form, DNS queries and nameserver responses are therefore susceptible to man in the middle attacks based upon network packet sniffing, such DNS hijacking, DNS cache poisoning, which we will look at below. It is worth noting that several extensions to DNS exist to address various shortcomings, such as Domain Name Security Extensions (DNSSEC), DNSCrypt, DNS-over-TLS and others, but these are not universally implemented or supported.
We’ll take a look below at some of the more common exploits that are seen against the Domain Name System, its clients, servers and the data transmitted between the two. It is worth noting however that this blog post can only skim the surface in the space available and it is not possible to list every variant of each exploit or detailed analysis of its execution, only to provide some basic awareness and context around the primary concerns. There is also a broad mix of issues listed below: some are general weaknesses in DNS design that can be exploited in numerous ways; others are very specific exploit cases that are worth including because they are very commonly seen or exploited and hence are worth explicit mention:
Some of the simplest exploits against DNS are various forms of packet interception based on the so called “main-in-the-middle” attacks, in which an attacker is able to leverage the lack of encryption within the basic UDP-based form of DNS transport in order to eavesdrop on requests to a DNS server and/or spoof responses back to the resolver. In either of these scenarios, the attacker can insert malicious responses to clients. The Domain Name System Security Extensions (DNSSEC) extension to the DNS system adds support for cryptographically signed responses to overcome this but is not universally adopted and required both client and server support to operate.
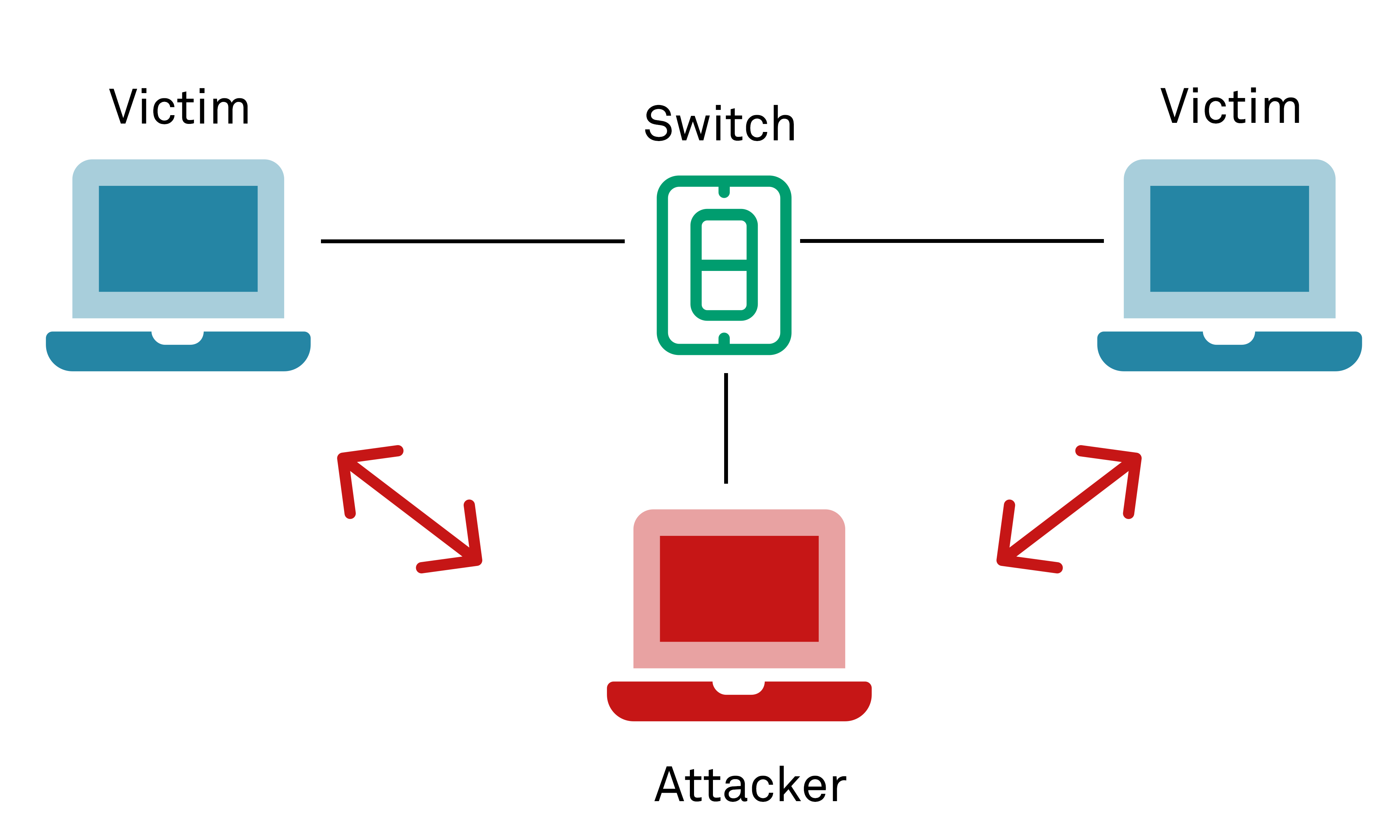
Homograph attacks are a category of attack that subvert user expectations in order to direct them via DNS resolution to a different destination (IP address) than that which they intended to access or visit. Although there are a number of ways in which this can be achieved, one common form in recent years is the exploitation of homoglphys (similar looking characters) within the ASCII or other character sets to perform an internationalized domain name (IDN) homograph attack. This relies on the fact that users may be unable to distinguish two similar characters from within a character set in a graphical user interface depending on the user’s chosen typeface. In a theoretical example, the domain name paypaI.com could be registered using a character string such that the Latin character “a” is replaced with the Cyrillic character “а”. When combined with a phishing email, a user could click through to what they believed was the “real” PayPal site but instead resolved to a server hosted on an IP owned by an attacker, who could then harvest their (real) PayPal credentials for example.
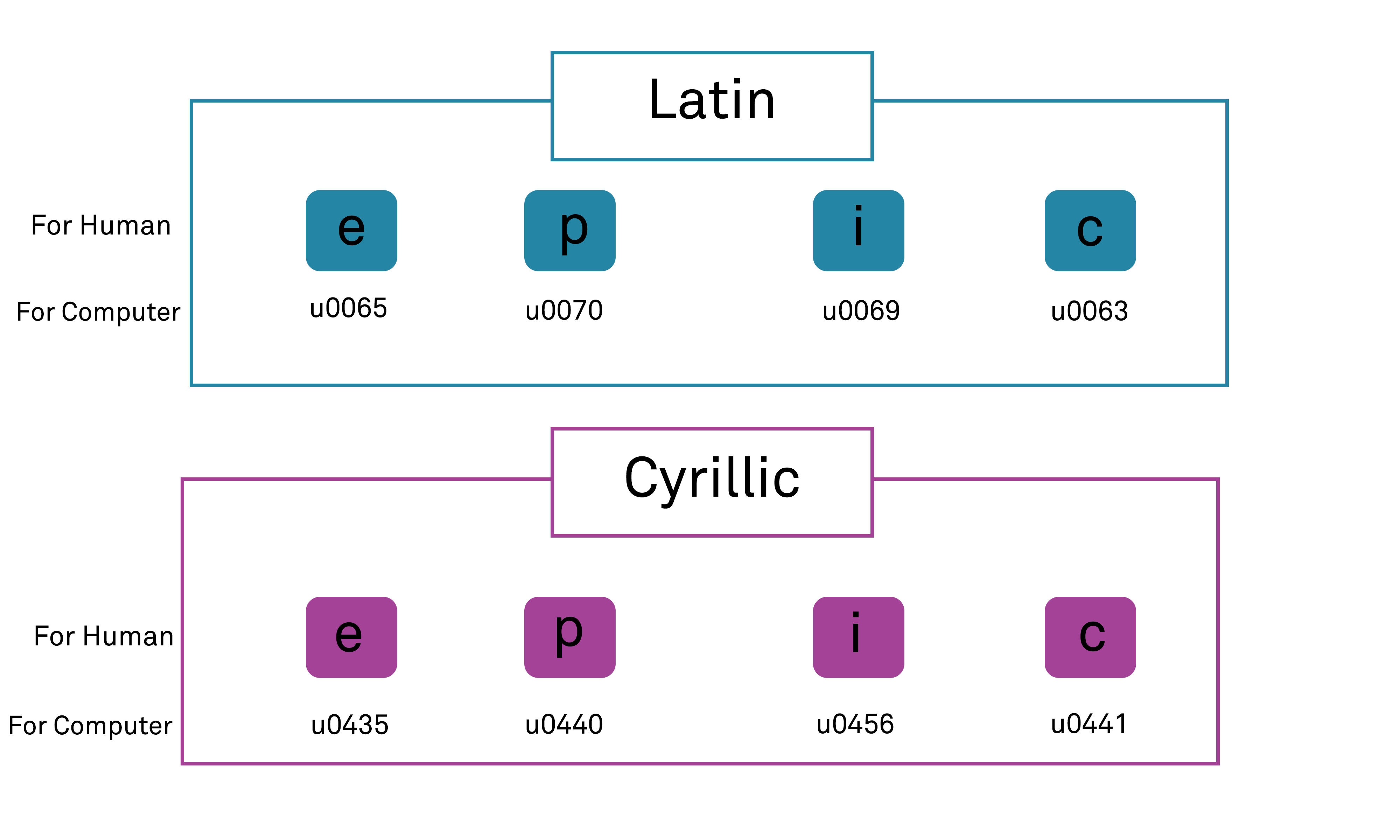
Domain Name Server (DNS) hijacking, also named DNS redirection, is a type of DNS attack in which DNS queries are incorrectly resolved in order to unexpectedly redirect users to malicious sites. This is similar to homograph attacks conceptually in terms of undermining user expectations/belief as to which site they are visiting but operates on a very different basis at the technical level, typically involving subversion of one or more devices in order to subvert their DNS responses. There are various forms, but varieties include local DNS hijacking (installing malware on a client user’s computer to direct DNS queries to attacker-controlled DNS servers), and DNS server subversion (in which attackers are able to hack a legitimate DNS server and update its records to point to malicious sites rather than genuine ones).
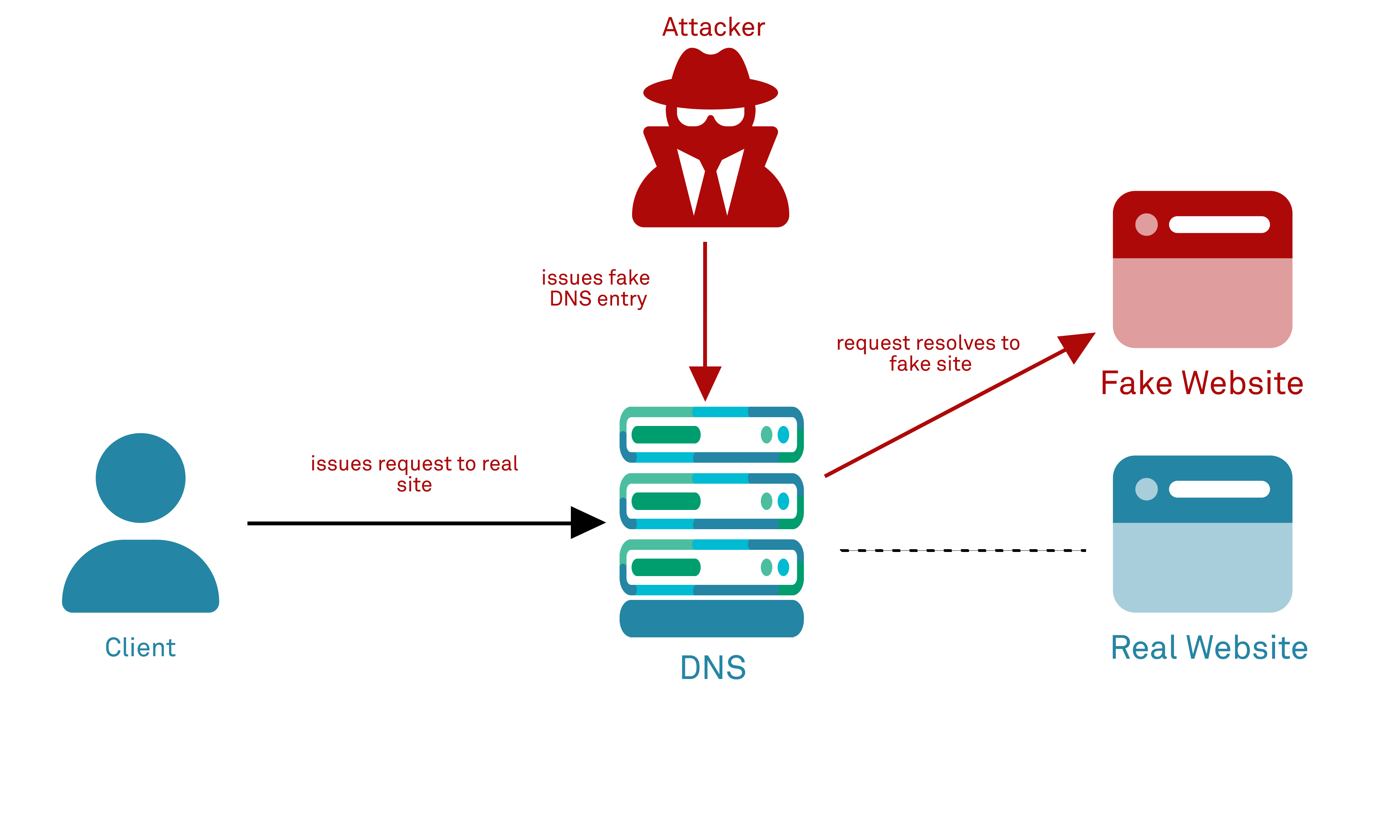
Cache poisoning attacks are similar to domain hijacking in that an attacker leverages tampered DNS records to redirect requestors to a malicious destination that closely resembles the genuine site, however the exploit relies not on the compromise of a DNS server itself but on being able to “poison” intermediate caches of DNS entries (on routers, CDNs, ISP equipment or other caching devices) by inserting forged DNS entries.
This attack leverages the fact that DNS resolvers downstream of the authoritative server will save (cache) responses to IP address lookups for a certain amount of time – typically under the time to live (TTL) expires – in order to reduce network load and respond to future queries much more quickly, bypassing the need to communicate with the many DNS servers involved in a typical DNS resolution process every single time a lookup is performed. Attackers are sometimes able to poison DNS caches by impersonating DNS nameservers, making requests to DNS resolver that operate using the UDP protocol (rather than TLS with DNSSEC), and then forging the reply when the DNS resolver queries a nameserver.
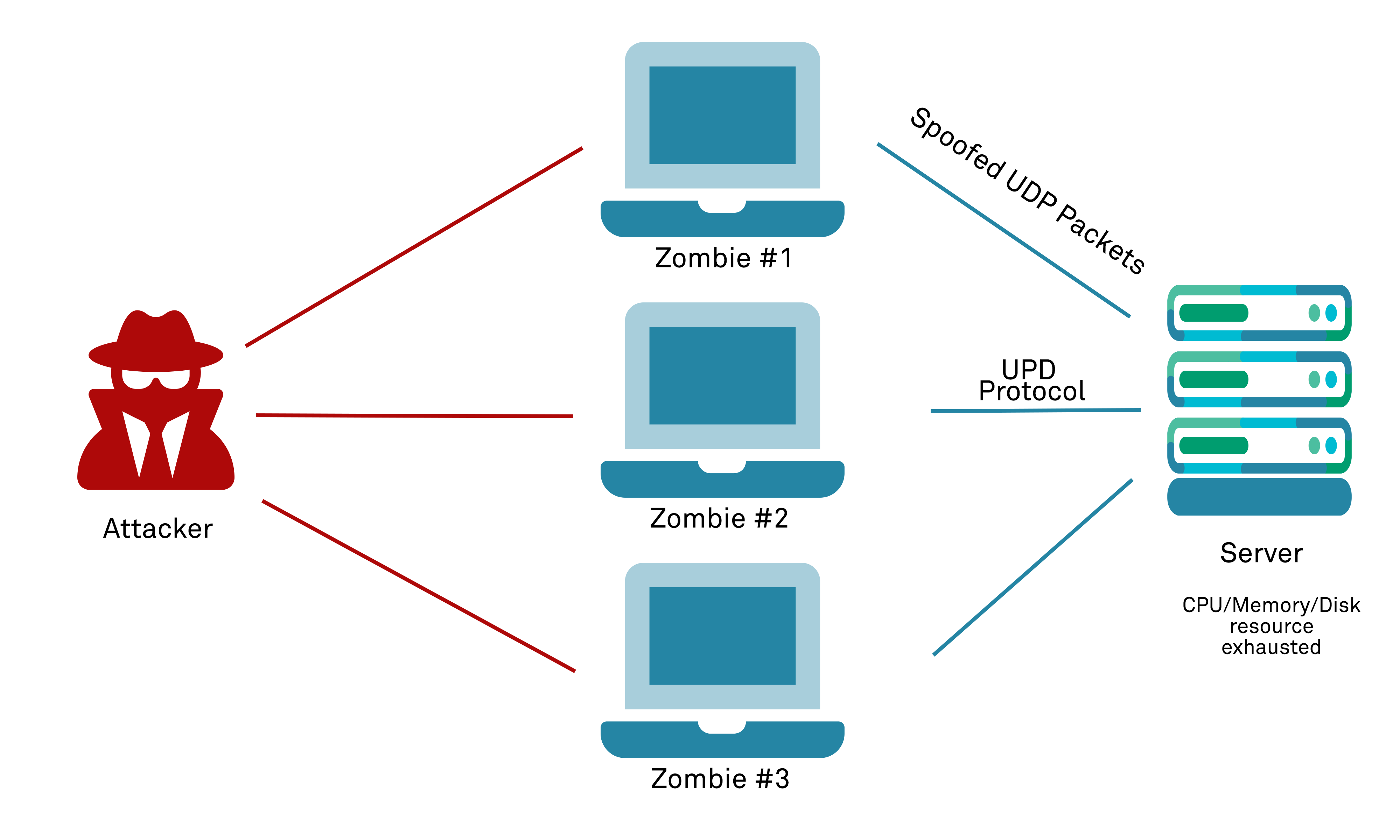
Like any other server, DNS servers are prone to all network-based attacks, but the use of the UDP protocol makes them particularly susceptible to attacks such as UDP datagram floods. Whilst not highly sophisticated, these do require specific architectural decisions and (typically) cloud or hardware solution deployments of relevant mitigation services or equipment in order to be able to be effectively defended against if performed at any scale.
Whilst not an “attack” type as such, DNS servers can unwittingly provide useful information to attackers performing reconnaissance and intelligence gathering ahead of and to inform a planned later attack. DNS data by design is supposed to be for public consumption, making this the ideal first step for an attacker trying to learn more about a target environment.
This can take a number of different forms:
Like any other server software, DNS servers also require regular patching and maintenance. Attackers can also leverage any unpatched or unaddressed vulnerabilities in DNS server software or underlying host operating systems to perform any number of exploit types, including bypass access control measures to create rogue entries in DNS zone files, or cause the DNS server to crash in order to deny service to legitimate users and potentially make websites and other services within a domain unreachable – the services themselves may be fully operational, but without the ability for requesting clients to resolve their host/domain names into IP addresses they cannot be reached since their address is not known.
Normally DNS records are entered locally on a DNS nameserver by manual or programmatic update of the zone file by ad administrator. Dynamic DNS (DDNS) is a method of automatically updating a name serve’s zone file with the active DDNS configuration of hostnames, addresses or other information. Although implementing security measures such as Transaction Signatures (TSIG), potential misconfigurations or poor cryptographic key hygiene/transfer processes as well as protocol weaknesses (such as the use of HMAC-MD5 digest) can lead to the ability for malicious attackers to insert rogue records at will via this mechanism.
Domain names are obtained commercially through a registrar company and can be subject to fraud if an attacker is able to compromise a user’s account with the registrar. This can happen if the registrar uses passwords for authentication for example without implementing multifactor authentication, since an attacker can potentially guess or bruteforce a valid credential set. They can then login to the registrar’s client administration portal and either completely change ownership of the domain, or update specific records to ultimately resolve client queries to malicious (attacker controlled) IPs.
The final two examples we will list is not a direct exploit of the Domain Name System itself in terms of compromise of the system itself, but rather illustrates creative and relatively new examples of how the DNS system can be used maliciously as part of a broader attack even where it is free of exploits or vulnerabilities itself – it demonstrates how the threat landscape is always changing, and how it is difficult to envisage in advance how an attacker can potentially leverage a seemingly harmless protocol for their advantage.
DNS Tunnelling describes how an attacker can use other protocols to tunnel through DNS queries and responses. If an attacker is able to compromise a single host on a network they may seek to establish a reverse shell for ongoing access or to conduct pivot attacks. In a well secured environment, it may be impossible for an attacker to directly establish an outbound SSH connection due to firewall restrictions between network segments and particularly at the network periphery. However, using DNS tunnelling an attacker can (albeit at a low baud rate) encode and package or wrap SSH commands (for example) within DNS queries (which are more likely to be permitted through a firewall), to a DNS server, where they can subsequently be decoded and a suitable reply in turn encoded and sent as a response.
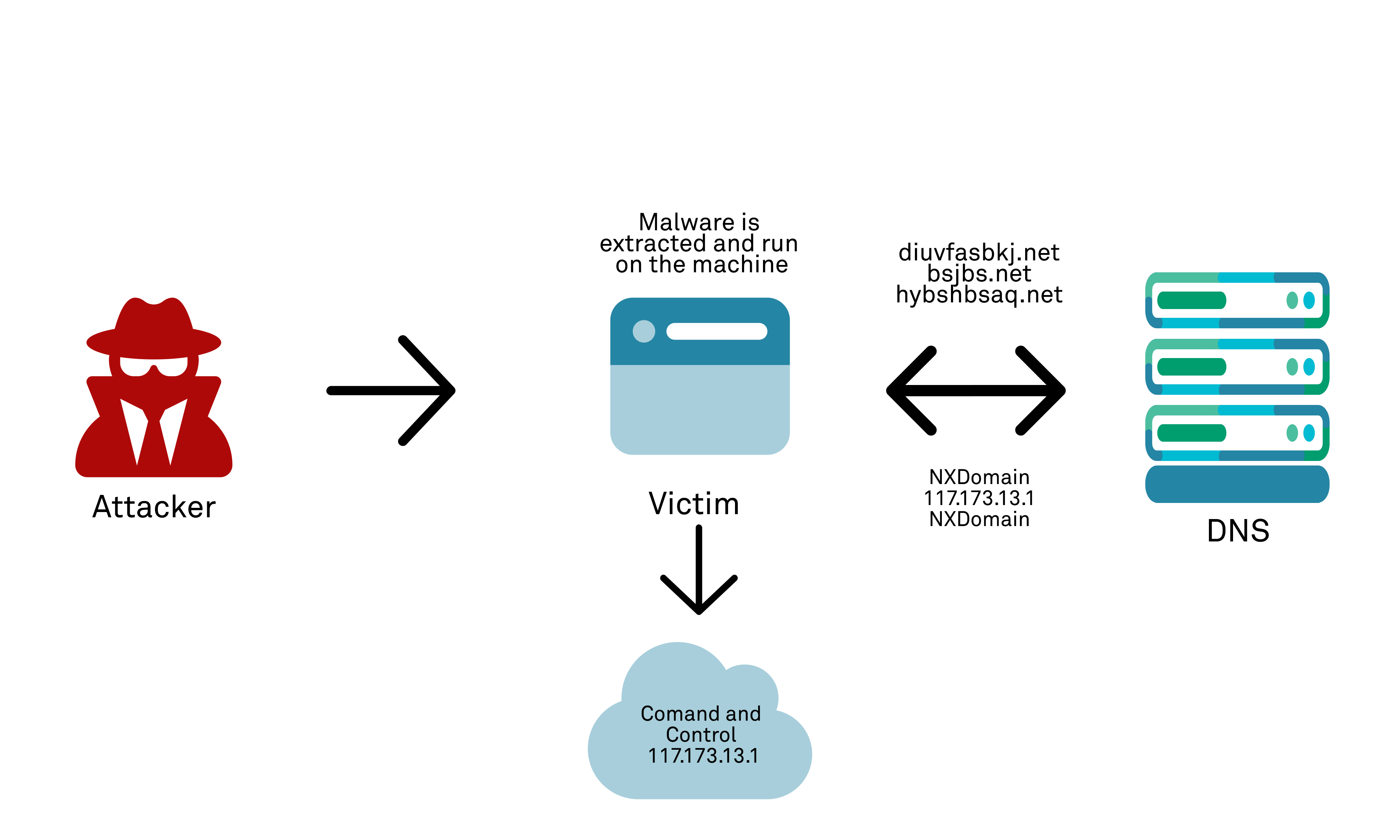
Earlier families of malware used a static list of IP/domains hardcoded into the malware as the Command and Control (C&C) endpoints for enslaved “zombie” victim computers to contact for instructions, however since these are static they could be blocked by security teams within ISPs and organisations.
Domain generation algorithms (DGA) are a technique seen in newer families of malware that are used to periodically generate a large number of domain names in DNS records. These DNS records can be used to provide a list of command-and-control servers that controlled zombie hosts in a botnet can use to communicate with for instructions. In the event that one C&C server on a given IP is blocked or taken down, an attacker can simply bring up another or switch to a secondary and change the DNS record to point to that host. Additional resilience is provided by creating a huge number (tens of thousands) of DNS records, of which only a handful are legitimate C&C servers: the “true” C&C server can be determined by botnet slaves using hashing from a pre-seeded value or similar, but a defender cannot identify which of the thousands of DNS entries is the one that is actually valid/being used by the attacker. The sheer number of potential C&C server endpoints with DNS records, and the ability to constantly add new ones makes it difficult for those trying to tackle the botnets to effectively shut them down.
AppCheck help you with providing assurance in your entire organisation’s security footprint. AppCheck performs comprehensive checks for a massive range of web application vulnerabilities – including DNS security weaknesses – from first principle to detect vulnerabilities in in-house application code.
The AppCheck Vulnerability Analysis Engine provides detailed rationale behind each finding including a custom narrative to explain the detection methodology, verbose technical detail, and proof of concept evidence through safe exploitation.
AppCheck is a software security vendor based in the UK, offering a leading security scanning platform that automates the discovery of security flaws within organisations websites, applications, network, and cloud infrastructure. AppCheck are authorized by the Common Vulnerabilities and Exposures (CVE) Program as a CVE Numbering Authority (CNA).
As always, if you require any more information on this topic or want to see what unexpected vulnerabilities AppCheck can pick up in your website and applications then please get in contact with us: info@localhost