
In this article we’ll take a look at how the origin of resources loaded by your web application – such as third party JavaScript – can impact the security of your organisational and customer data. We’ll investigate the anti-patterns that introduce significant risk, how these can be prevented, and what can be done to detect and mitigate these vulnerabilities. We’ll also see how vulnerability scanners such as AppCheck can provide essential coverage to detect instances where something has gone wrong and your web applications may be vulnerable to exploit via insecure inclusion of content outside your organisation’s control.
HTTP communication is stateless in that it does not require the server to retain session information or status about each user connection across the duration of multiple requests. Each request therefore stands alone in its own right. It is not practical for a server to require that a user re-authenticates each request with a username and password however – this would get incredibly frustrating for users. The most common solution to this is therefore for websites to issue a secure session token to a browser that uniquely identifies an authenticated user. It is stored server side and also provided back to the user within a “cookie” that can be stored within the local browser and submitted automatically on future requests to preserve state across multiple requests:

One of the basic features of the web is that of interconnections and (relatively) open access to resources. This means that a web application served to a client from one origin or domain (e.g www.example-organisation.com) may return a HTML response containing a <script> tag instructing a client’s browser to load a resource from another domain, such as www.example-thirdparty.com, a domain that may be unrelated and owned and operated by another individual.
This functionality is important in that it enables many of the common functionalities we see on modern websites and that the web depends up on, for example:
This concept is basic to the web and is sometimes referred to as a “web mashup”.
These modern, dynamic web applications offer rich functionality in which resources such as JavaScript are permitted to both access and potentially modify client-side data stored within the browser, via a hierarchical and addressable series of properties known as the Document Object Model or DOM, which are then addressable via the DOM. This includes access to authentication tokens that are stored within cookies. If this data were accessed via malicious JavaScript loaded from a third-party domain, then sensitive data could be accessed. In order for websites to safely instruct user’s browsers to load dynamic resources such as JavaScript therefore, a protection measure is needed to restrict the ability of such resources from differing domains and zones of trusts to access data stored on the client’s browser relating to the current webpage.
The concept of the “Same-Origin Policy (SOP)” was introduced by Netscape within their “Navigator 2.02” browser product way back in 1995 as a security concept to address the dangers outlined above, and is used within all major browsers today. It ensures segregation of data relating to different web applications by placing a series of restrictions on the interaction between resources loaded from different origins or domains. It was added largely in response to the introduction of JavaScript in Netscape 2.0, which enabled dynamic interaction with the DOM. Under the Same Origin Policy, a web browser restricts access to resources relating to one origin to being permitted only via other resources from that origin. This prevents a malicious script loaded from one origin from obtaining access to sensitive data on a page loaded from a different origin via that page’s Document Object Model.
The origin doesn’t entirely coincide with the domain alone – web resources (or more accurately the URLs that they load from) are determined to have the same origin if the protocol (e.g HTTP or HTTPS), port (e.g 80 or 443), and host (e.g www.example.com) are all the same for both resources.
The way that the SOP is delivered means that cross-origin reads via scripts are disallowed by default. A web page may freely embed cross-origin images, stylesheets, scripts, iframes, and videos, but certain “cross-domain” requests, notably Ajax requests via JavaScript, are forbidden by default by the same-origin security policy.
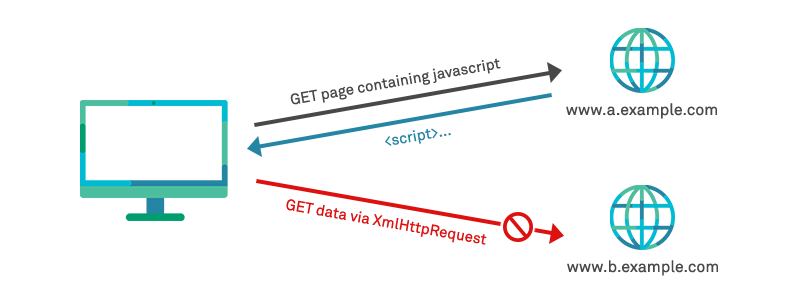
This means that sites can still embed content from external sources – such as iframes to deliver adverts or YouTube videos mentioned in our examples above – but in such a way that they do not grant the serving site for the loaded material the ability to use scripts to read the DOM it is loaded within, or to view user interaction fired as actions within that DOM. For example, a malicious web page loaded at https://evil.com can make HTTP requests (e.g using XMLHttpRequest) and read the response within its own origin, but cannot read responses from another origin such as https://example.com. Put simply, the SOP ensures that browsers restrict cross-origin HTTP requests initiated from scripts.
The Same Origin Policy therefore effectively prevents malicious scripts from accessing data from another domain (origin). Whilst the Same Origin Policy is an important and well tested security concept, many modern applications described as “mashups” above require the ability to communicate across and load resources between multiple trusted origins in order to deliver rich functionality. That is, they require permitting user’s browsers to execute a cross-origin HTTP request by requesting a resource that has a different origin (domain, protocol, or port) from its own, and trusting that resource with access to elements within the DOM relating to the serving origin/domain.
A mechanism known as Cross-Origin Resource Sharing (CORS) was therefore proposed in May 2006 under a W3C Working Draft in order to provide a method of white-listing origins that are permitted to communicate with a resource as if they reside within the same origin. CORS defines a way in which a browser and server can interact to determine whether it is safe to allow the cross-origin request. It allows for more freedom and functionality for script execution than purely same-origin alone (the situation after SOP was introduced), but is more secure than simply allowing all cross-origin requests (default position prior to SOP).
The use of SOP & CORS together therefore ensures that web mashups can continue to be used, but in such a way that helps to prevent potentially malicious changes by restricting the trust relationship to specific white-listed origins only. Effectively, SOP changes the behaviour of script execution by third-party domains to “default deny” (universal blacklist) and then CORS can be used to deliver a list of specific white-listed exceptions on top of this.
The list of trusted endpoints for a domain is maintained by the servers serving content for that domain. Under the CORS mechanism this white-list is delivered to clients via a server-specified directive that is transmitted within HTTP response headers to clients. It includes two important headers; Access-control-allow-origin to define which origins are permitted access to restricted information within the DOM relating to the serving domain/origin, and Access-control-allow-credentials that determines if requests authenticated using cookies are permitted.
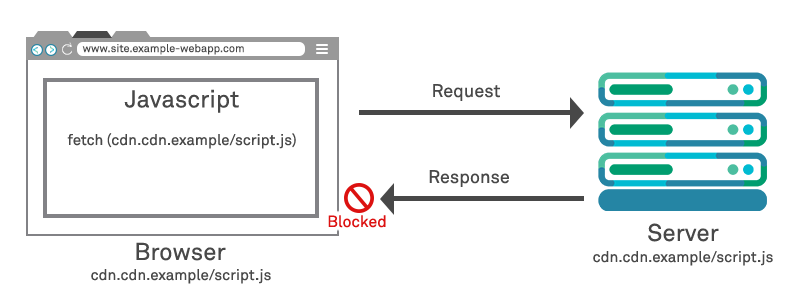
As an example of a cross-origin request, we can consider an example in which the front-end JavaScript code that a website hosted from https://www.example-webapp.com requests to be loaded via XMLHttpRequest may reside on https://cdn.example-cdn.com
Using CORS, this access can be permitted:
(Request to CDN / third party domain:)
GET /resources/public-data/ HTTP/1.1
Host: cdn.example-cdn.com
Origin: https://example-webapp.com
(Response:)
HTTP/1.1 200 OK
Access-Control-Allow-Origin: https://example-webapp.com
Content-Type: application/xml
[…Data…]
You may have noticed that in the CORS architecture, the trust is in some ways “back to front”. That is, the trust relationship is governed by the third party providing the resource dictating which origins can load it. That is, the Access-Control-Allow-Origin header is being set by the external web service (https://cdn.example-cdn.com ), and advising the client whether the original web application server (www.example-webapp.com) should trust the content. This arrangement works fine where both the third-party domain from which the JavaScript is being loaded, and the webapp, are operated by the third party. However it does nothing to provide the web application itself with the ability to control which third party domains are permitted to execute content on its DOM.
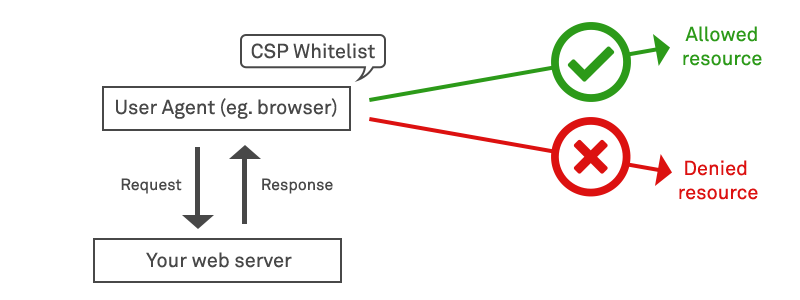
First proposed in around 2004, an alternative mechanism known as Content Security Policy (CSP) was introduced to permit control of resources in the opposite direction – that is, to allow web applications to control which external domains may execute scripts within their trusted web page context. CSP provides a standard method for website owners to declare approved origins of content that browsers should be allowed to load on that website. It achieves this by restricting the sources of content loaded by the user agent to those only allowed by the site operator, via a HTTP Response Header:
(Request to the hosting web application:)
GET / HTTP/1.1
Host: example-webapp.com
(Response:)
HTTP/1.1 200 OK
Content-Security-Policy:
default-src ‘self’;
script-src ‘self’ https://cdn.example–cdn.com;
The final piece in the puzzle to consider is the question of whether trust extended to content provided by a domain is blind/absolute, or can be subject to further constraints. For example, we can imagine a scenario whereby an organisation ensures that all its code is subject to careful code review by a senior engineer before it is deployed under a CI pipeline, in order to check for the introduction of malicious code. Third-party code loaded from a domain, even where we’ve trusted the domain itself using a secure Content-Security Policy, is not subject to such review. A malicious party within the third-party could serve malicious code to our users under the trust agreement that we’ve established and permitted, and we would be none the wiser.
A pattern that is frequently used is the contracted usage of Content Delivery Networks (CDNs) to host files such as JavaScript that are shared among multiple sites can improve site performance and conserve bandwidth. However, using CDNs also comes with a risk, in that if an attacker gains control of a CDN, the attacker can inject arbitrary malicious content into files on the CDN (or replace the files completely) and thus can also potentially attack all sites that fetch files from that CDN.
Thankfully, there is a fourth mechanism known as subresource-integrity verification or SRI. This permits a web application owner to specify to a client that where a resource is to be retrieved from a third party (that is, from an origin other than that matching the origin of document in which it’s embedded) it should check that the contents of the resource that have been delivered are as per a reviewed version without a third-party having injected any additional content into those files, and without any other changes of any kind at all having been made to those files.
This is done by essentially providing a hash or checksum calculated from a known-good and reviewed version of the resource. The web application owner reviews the third-party JavaScript and, once satisfied that it contains no malicious code, calculates a base64-encoded cryptographic hash of the resource, and them embeds or includes this value within their pages wherever the resource is called. The value is inserted into an integrity attribute of any <script> or <link> element. For example:
<script src=”https://cdn.example-cdn.com/example-framework.js”
integrity=”sha384-oqVuAfXRKap7fdgcCY5uykM6+R9GqQ8K/uxy9rx7HNQlGYl1kPzQho1wx4JwY8wC”
</script>
When a browser encounters a <script> or <link> element with an integrity attribute, before executing the script it must first calculate a hash for the version of the script that it has retrieved and compare this to the expected hash given in the integrity value. If the script hash doesn’t match its associated integrity value, the browser must refuse to execute the script, and must instead return a network error indicating that fetching of that script failed.
These are relatively complex mechanisms and if various headers are omitted or mis-specified, then the protection offered can vanish, leaving a web application vulnerable to a range of security risks including Cross-Site Scripting (XSS).
Careful code review by experienced senior developers, may uncover several issues, however dynamic testing is the only way to ensure that your application is secure in practice on your live platform instance, as well as uncover vulnerabilities introduced by applications, libraries and resources outside your code review process. A DAST vulnerability scanner such as AppCheck is essential for ensuring that your CORS, CSP and SRI configurations are correctly configured and robust.
AppCheck helps you with providing assurance in your entire organisation’s security footprint. AppCheck performs comprehensive checks for a massive range of web application vulnerabilities – including CSP, SRI and CORS misconfigurations and violations – from first principle to detecting vulnerabilities in in-house application code. AppCheck also draws on checks for known infrastructure vulnerabilities in vendor devices and code from a large database of known and published CVEs. The AppCheck Vulnerability Analysis Engine provides detailed rationale behind each finding including a custom narrative to explain the detection methodology, verbose technical detail and proof of concept evidence through safe exploitation.
As always, if you require any more information on this topic or want to see what unexpected vulnerabilities AppCheck can pick up in your website and applications then please get in contact with us: info@localhost