Information security is above all concerned with the protection of electronic resources, and the trifecta of threats or concerns known as the “CIA Triad” – the Confidentiality (who can read), Integrity (who can write or alter) and Availability (who can access) those resources, based upon need and intended usage.

Very few electronic resources are simply a “free for all” that are open to being read, written, or modified by anybody at all – and even where that is the case, the availability of the resource is still typically of concern if the resource is to be in any way useful and reliable.
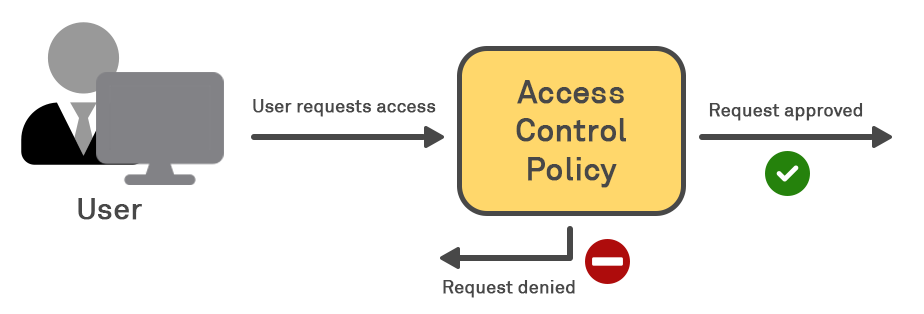
Access control is the practice of applying selective restrictions upon the access to these electronic resources in such a way as to deliver upon the desired confidentiality, integrity and/or availability of the resource – whether that is a system or service as a whole, or specific granular resources (such as individual files or records) within that system. The process of defining, implementing, and managing access control within a system or service is known as access management.
The act of accessing an electronic resource may mean consuming, entering, or using that resource in a way that threatens its desired state under the CIA triad – for example, if you were to delete a resource, you then impact the availability of that resource to others. Likewise, if you modify a resource, then you impact the integrity of that resource against the state or content that was initially set for it by the system’s owners.
In any access-control model, the primary concern is therefore placing defined restrictions upon resources and the entities (typically accessing parties or users) that make use of the system. In access control terminology, the entities (typically users) that can perform actions on the system, service or resource are called subjects, and the entities representing resources to which access may need to be controlled are known as objects.
Access Control, and the effective implementation of access management systems to deliver upon it, helps to deliver or guarantee the intended state of a resource therefore in all three “legs” of the CIA triad.
In computer security, access control is generally implemented by defining and implementing an access management system that collectively provides accountability or assurance with regards to appropriate access of objects by requesting subjects. Conceptually, an access control system is said to manage subject authentication (verifying that an accessing subject is who they claim to be), authorisation (checking that a subject is accessing a resource to which they have been granted access) and audit (recording that access in case of future need to review access attempts).
The exact manner in which access control is implemented can vary from one system to another, and can be based on any number of access control models at various levels of granularity from Identity-Based Access Control (IBAC) in which access is based on individual needs (such as the ability of specific users to access only their own banking records on an online banking platform) to Role Based Access Control (RBAC) in which users are “grouped” into one or more privilege levels such as “normal users” and “administrators”, with only the latter able to access certain functionality, for example.
In a web application, both forms of access control (and many others) may be simultaneously present, with IBAC being used to provide protection of discrete accounts or records, and RBAC being used to govern access to certain routes or views that provide access to administrative functionality.
There are many different scenarios in which access control may be broken (which we look into in more detail below) but in general an access control failure is any misconfiguration or flaw within the application such that records or resources are not properly protected as designed in terms of their CIA requirements. Most commonly, we would think of confidentiality-impacting flaws, such that information may inadvertently be exposed to or able to be accessed by unauthorized parties – but more broadly access control failure covers integrity and availability failures too, under any scenario in which users are able to act outside of the permissions intended for them by the system’s owners.
In web application security, there is a community-developed list known as the CWE list (or “Common Weakness Enumeration list) that attempts to defined and categorise the many ways in which software and hardware can exhibit weaknesses that undermine its ability to guarantee effective information security. The CWE list define access control failures as any failure where the software does not restrict or incorrectly restricts access to a resource from an unauthorized actor.
The actual causes can vary broadly, but in general can be said to, at root, be caused by either:
In web applications, certain types of failures in access control are common enough in broad pattern (even though the code flaw that causes them may be entirely independent in each case) that they have been documented as a commonly recognised failure pattern by the CWE project.
Below is a list of some of the more common types of access control failures that are typically seen in web applications:
In this type of failure, a system’s authorisation functionality does not prevent one user from gaining access to another user’s data or record by modifying the key value identifying the data. Retrieval of a user record occurs in the system based on some key value that is under user control. The key would typically identify a user-related record stored in the system and would be used to lookup that record for presentation to the user. However, the authorisation process would not properly check the data access operation to ensure that the authenticated user performing the operation has sufficient entitlements to perform the requested data access, hence bypassing any other authorisation checks present in the system.
For example, a system may use a login screen to authorise a user, before forwarding them to their account record using a “key” in the URL such as:
https://www.example.com/accounts/user/1274
which is the user record for user number 1274.
A common pattern seen is that the system might govern access to the system by performing two access control checks:
And if the answer to both is “yes”, then access to the record is granted. However, the flaw here is that both those conditions are true if the accessing user is actually user number 883 – because they have a valid account on the system then they pass authentication, and the record 1274 does exist (it just isn’t the requesting user’s records). So the system would erroneously grant access to user 1274’s record to requesting user 883.
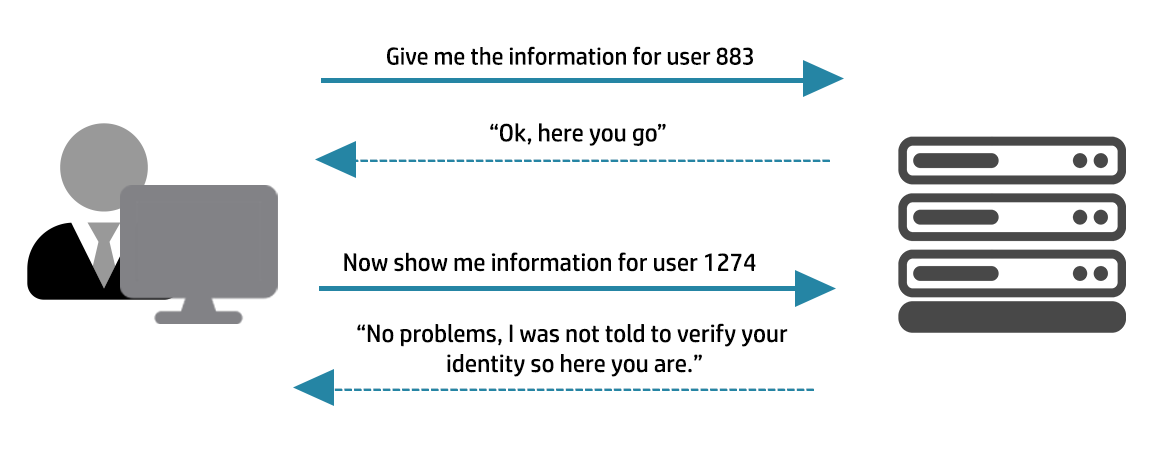
What the access management system should have done is to check not just authentication but authorisation – that is, not just “is user 883 logged in” but “is user 883 permitted to access record 1274”. It may seem obvious, but this is an extremely common type of access control weakness.
This type of failure is sometimes referred to as “IDOR” (or “Insecure Direct Object Reference”) even in the OWASP Top 10, but IDOR is in fact a much broader type of weakness that also covers weaknesses including “path traversal”, which we will look at next:
In a “path traversal” weakness, the web application code uses external input to construct a path that is intended to identify a file or directory that is located underneath a restricted parent directory but does not properly neutralize special elements within the path that can cause the path to resolve to a location that is outside of the restricted directory.
Many file operations are intended to take place within a restricted directory – for example fetching images from a specific “/images” directory on disk. However, by inserting elements into the requested filename such as “..” and “/” separators that have special meaning within the executing interpreter or operating system as means of navigating directory structures, attackers can escape outside of the restricted location to access files or directories that are elsewhere on the system.
One of the most common special elements is the “../” sequence, which in most modern operating systems is interpreted as the parent directory of the current location. This is referred to as relative path traversal. Path traversal also covers the use of absolute paths such as “/usr/local/bin”, which may also be useful in accessing unexpected files. This is referred to as absolute path traversal.
Using this technique, resources that are not intended to be accessed by a given user – and often not intended to be retrievable via web request by *any* user whatsoever – may be served up and returned in web application responses to malicious attackers.
Improper authentication is a relatively simple type of access control weakness in which the access management system simply fails to robustly ensure that the requesting subject’s claim to identity is legitimate. In an access control system that is single-factor and reliant on passwords to prove identity, then a form of improper authentication would simply be the presence of weak password requirements for users, or the absence of any password strength requirements whatsoever. If the access control system permits users to set their password to “password”, and especially if this is paired with the presence of a resource where it is possible to list or enumerate all users, or where login attempts are both unlimited in number and ungoverned by any kind of rate control, auditing or account locking, then it is relatively trivial for an attacker to access a large number of accounts belonging to other users by simply “brute forcing” guesses as to their passwords.
AppCheck help you with providing assurance in your entire organisation’s security footprint. AppCheck performs comprehensive checks for a massive range of web application vulnerabilities – including access control misconfigurations and violations – from first principle to detect vulnerabilities in in-house application code.
AppCheck can detect IDOR in your application using advanced vulnerability scanning techniques. AppCheck will look for common PII data in returned server responses and determine if the returned data changes when cycling input numeric parameters.
Insecure or superficial access control systems that simply hide components but do not properly secure them are also identified.
AppCheck also draws on checks for known infrastructure vulnerabilities in vendor devices and code from a large database of known and published CVEs.
The AppCheck Vulnerability Analysis Engine provides detailed rationale behind each finding including a custom narrative to explain the detection methodology, verbose technical detail and proof of concept evidence through safe exploitation.
AppCheck is a software security vendor based in the UK, offering a leading security scanning platform that automates the discovery of security flaws within organisations websites, applications, network, and cloud infrastructure. AppCheck are authorized by the Common Vulnerabilities and Exposures (CVE) Program as a CVE Numbering Authority (CNA).
As always, if you require any more information on this topic or want to see what unexpected vulnerabilities AppCheck can pick up in your website and applications then please get in contact with us: info@localhost