The web is built upon a basic request-response model over HTTP in which clients (users) make requests for resources using a web browser.

Underneath the hood, the browser interprets GUI actions such as clicking on links or submitting forms into actions using one or more HTTP verbs or methods – some examples of available methods in a hypothetical photo storage website are listed below:
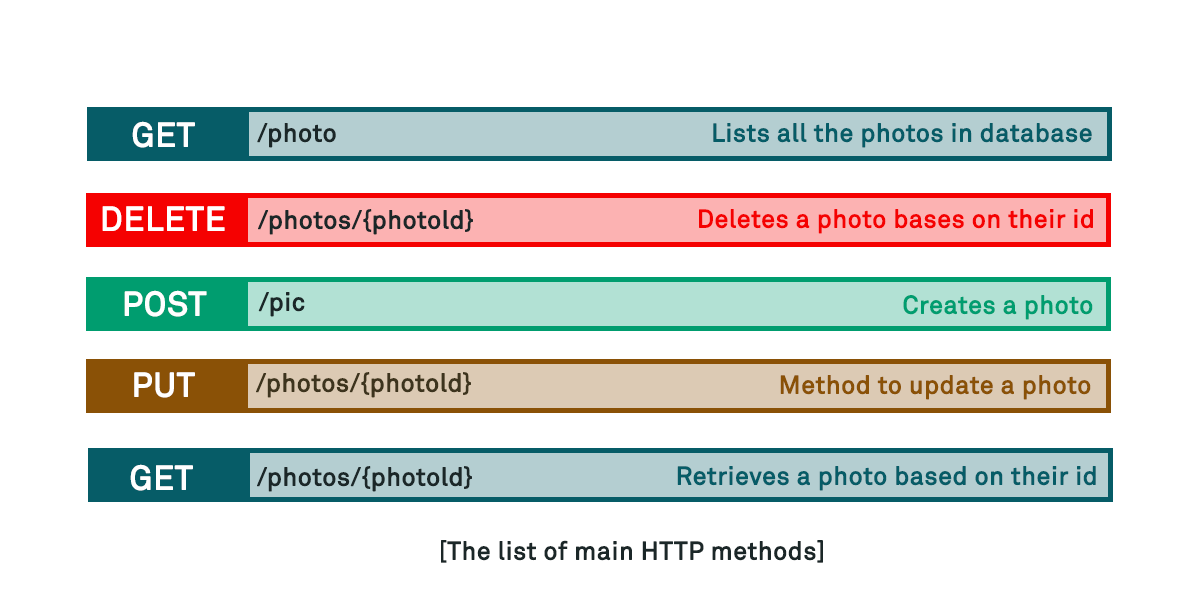
As can hopefully be seen, whilst many actions such as “GET” are read-only on the server side, others, such as “DELETE”, “POST, or “PUT” can make potential changes on the target server. It is therefore important within the context of many websites that changes made on the server are in some way restricted to those intended by the service designer. For example, a photo hosting website does want to allow the removal of existing photos via the DELETE method, but likely only by the user that uploaded it in the first please. Likewise, it may want to allow the retrieval and display of a photo via the GET method, but only by the user that originally uploaded it. The photo hosting website therefore needs to ensure that requests to perform actions are only able to be performed by the appropriate combination of requester (known as an access control “subject”) and the resource being requested (known as the access control “object”). Additionally, it has to manage this relationship in the context of requests made over HTTP which is described as a stateless protocol in that each request the webserver receives cannot natively (within the HTTP protocol) be tied to any previous request received.
Authentication is the method that is used to prove a HTTP request is being issued by a specifically-identified user. In contrast with identification (the act of uniquely identifying a user), authentication is the process of verifying the the user that sent the request is actually the user they claim to be.
The ways in which someone may be authenticated fall into three categories, based on what are known as the factors of authentication: something the user knows, something the user has, and something the user is. The most simple form of authentication is single factor authentication (that relying on one factor only , rather than checking multiple factors before accepting an identity has been proven), and the most common single factor used is the knowledge factor, typically implemented as a shared secret between the user and webserver in the form of a password that is known only by that user and no other.
In computer security, access control is generally implemented by defining and implementing an access management system that collectively provides accountability or assurance with regards to appropriate access of objects by requesting subjects. Conceptually, an access control system is said to manage subject authentication (verifying that an accessing subject is who they claim to be), authorization (checking that a subject is accessing a resource to which they have been granted access) and audit (recording that access in case of future need to review access attempts).

Within web applications, the problem of web requests being stateless at the HTTP protocol level (you don’t want to have to submit your password every single time you click on a link on a website) is resolved by implementing a form of Continuous Authentication using stateful authentication
This is typically implemented using HTTP cookies – after the initial login the user is returned a token by the server containing a unique character string representing their session, and their browser simply returns this back to the server on each subsequent request made such that, although the request itself is stateless, the server can “tie” it into previous requests submitted using that cookie and recognise the request as a part of an ongoing transaction or conversation it is having with an authenticated user.
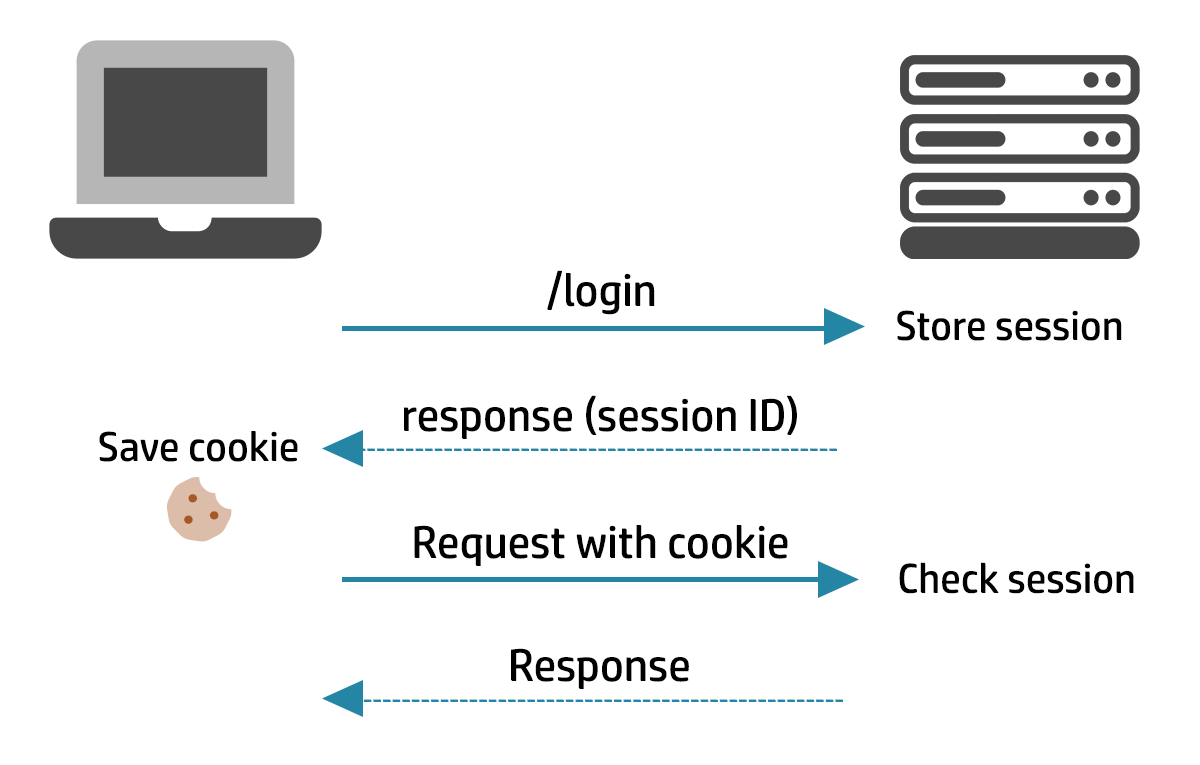
When we say that authentication is “broken”, we mean that it is not possible to be certain that requests being made by a user with a certain claimed identity are in fact being made by the user with that identity. This could technically take one of several different forms including:
In many cases, broken authentication may in fact lead to both outcomes simultaneously, however it is the former type (false positives) that are generally most concerning from a security standpoint since they impact all three of the “CIA triad” of confidentiality, integrity and availability of the user’s data to its owner whereas the latter typically only impacts its availability.
The actual causes of broken authentication are extremely numerous – the attempt by MITRE to categorise common weaknesses in the security of software and hardware in a taxonomical system has hundreds of different weakness types listed under the “improper authentication” category for example. However, in general authentication failures occur as a result of one of four broad failure types:
In web applications, certain types of failures in authentication are common enough in broad pattern (even though the code flaw that causes them may be entirely independent in each case) that they have been documented as a commonly recognised failure pattern by the CWE project. The below is a list of some of the more common types of authentication failures that are typically seen in web applications:
In perhaps the most simple form of broken authentication, the website simply does not perform any authentication for functionality that requires a provable user identity or consumes a significant amount of resources and simply “trusts” any identity claim made. Whilst this may seem unlikely to occur, it is often found in a form known as incomplete mediation – although this can apply more broadly as a term to a wider category of issue, in regard to authentication it simply means that a website may only check authentication once within a given flow – say on accessing an account summary page – but then fail to re-check authentication on requests for individual requested records listed on the summary page.
Authentication mechanisms often rely on a memorized secret (also known as a password) to provide an assertion of identity for a user of a system. It is therefore important that this password is of sufficient complexity and impractical for an adversary to guess. The specific requirements around how complex a password needs to be depends on the type of system being protected. Selecting the correct password requirements and enforcing them through implementation are critical to the overall success of the authentication mechanism.
The website may not implement sufficient measures to prevent multiple failed authentication attempts within in a short time frame, making it more susceptible to brute force attacks even if passwords are reasonably strong (to counter the above failure type).
Websites will often contain a mechanism for users to recover or change their passwords without knowing the original password, but sometimes this mechanism can be implemented with weaknesses or flaws. It is common for an application to have a mechanism that provides a means for a user to gain access to their account in the event they forget their password. Very often the password recovery mechanism is weak, which has the effect of making it more likely for a person other than the legitimate system user to gain access to that user’s account. Weak password recovery schemes completely undermine a strong password authentication scheme.
A typical flow may look like the below:
So what can go wrong? This weakness may be that the security question is too easy to guess or find an answer to (e.g. because the question is too common, or the answers can be found using social media). Or there might be an implementation weakness in the password recovery mechanism code that may for instance trick the system into e-mailing the new password to an e-mail account other than that of the user.
When setting a new password for a user, the product does not require knowledge of the original password, or using another form of authentication. This could be used by an attacker to change passwords for another user, thus gaining the privileges associated with that user.
Password management issues occur when a password is stored in plaintext in an application’s properties, configuration file or database. If a method such as path traversal or SQL injection can be used to access files or database records then an attacker may be able to recover passwords for every user, gaining access to any and all user accounts.
The use of weak, reused, and common passwords is rampant on the internet. Without the added protection of multiple authentication schemes, a single mistake can result in the compromise of an account. For this reason, if multiple-factor schemes are possible and also easy to use, they should generally be implemented and required in order to protect user accounts.
In this weakness type, a default administration account may be created at time of software install, and a simple password is hard-coded into the product and associated with that account. This hard-coded password is the same for each installation of the product, and it usually cannot be changed or disabled by system administrators without manually modifying the program, or otherwise patching the software. If the password is ever discovered or published (a common occurrence on the Internet), then anybody with knowledge of this password can access the product. Finally, since all installations of the software will have the same password, even across different organizations, this enables massive attacks such as worms to take place.
The act of logging into to an application usually amounts to the application verifying your credentials, then issuing you with a session token (e.g. a cookie or API token) which your browsers sends in each subsequent request. This mechanism relies on the fact that the session token should not be discoverable by guessing it, so it should be a long randomly generated value.
Sometimes a flawed implementation focuses on the uniqueness rather than randomness of tokens, so creating a token like: username-[login_timestamp] (e.g. fred-1632844706). Or even a sequential number: 54356666, 54356667, 54356668 An attacker can easily spot these patterns by observing how their own session tokens change under repeated logins – Then they can write a quick script, say to hijack recently created sessions of other users.
In this type of authentication weakness, a website transmits credentials using an insecure method that is susceptible to unauthorized interception and/or retrieval. The purpose of SSL/TLS (i.e. https://… connections) is to make it practically impossible for any data between your browser and an application to be intercepted in any useful way, but is not universally used still by all websites.
AppCheck help you with providing assurance in your entire organisation’s security footprint. AppCheck performs comprehensive checks for a massive range of web application vulnerabilities – including authentication failures, misconfigurations and violations – from first principle to detect vulnerabilities in in-house application code.
While crawling an application AppCheck analyses the session for the possibility of enumeration by activating many sessions and examining the tokens. It will also look out for weakly implemented authentication, for example long response 302 redirects, which usually happens when the application serves up the content of a restricted view in the response of the page but then sends a redirect in the header.
AppCheck specific checks for known default or hard-coded vendor passwords on equipment and services, the use of session IDs in the URL, plaintext passwords emailed to users during registration, vulnerabilities in forgot-password processes, and authentication bypass. AppCheck also includes configurable password guessing modules to identify weak account credentials with systems such as:
The AppCheck Vulnerability Analysis Engine provides detailed rationale behind each finding including a custom narrative to explain the detection methodology, verbose technical detail and proof of concept evidence through safe exploitation.
As always, if you require any more information on this topic or want to see what unexpected vulnerabilities AppCheck can pick up in your website and applications then please get in contact with us: info@localhost