HTTP Cookies are a near-universal mechanism in the modern web that underpins the preservation of state in customer sessions on websites. However, due to both inherent weaknesses in the HTTP cookie specification itself, as well as weaknesses commonly introduced at time of implementation by developers, cookies can often introduce vulnerabilities to websites and web applications which can then be exploited by attackers – both in opportunistic infractions as well as pre-planned and coordinated attacks, and via several vectors.
For historical reasons, the specification for HTTP cookies itself contains several inherent security weaknesses. Many of these weaknesses are well known and even in fact explicitly acknowledged and cautioned against within the RFC document that defines the HTTP Cookie standard: for example, a server can indicate that a given cookie is intended for secure connections, but the “Secure” attribute being set on a cookie does not actually provide integrity against exploits conducted by attackers suitably positioned on the network. In addition to these “inherent” weaknesses in their specification, cookies are also subject in their usage to a number of implementation complexities that can lead to the inadvertent introduction of further vulnerabilities: for example, the declared scope for each cookie, indicating the maximum amount of time in which the user agent should return the cookie, the servers to which the user agent should return the cookie, and the URI schemes for which the cookie is applicable are all seemingly innocuous settings which, if not set to appropriate values, can introduce additional weaknesses.
In this blog post we will review what cookies are, why cookies are needed at all, how cookies work, the weaknesses that cookies can be prone to both inherently as well as if implemented incorrectly, and how both website operators and general web users can help to ensure their secure implementation and usage.
An HTTP cookie is a small piece of data, typically alphanumeric, that is issued by and therefore associated with or attributed to a specific website (technically a specific domain), and which is stored on the user’s computer by the user’s web browser. Cookies exist as what is known as attribute-value pairs in the format “[attribute]=[value]”, and encoded for transfer between client and server as below:
SAPISID=jcDvOW0u…
These are then stored in the browser (client) and server alike as these name/value pairs (screenshot from Google Chrome web browser below):
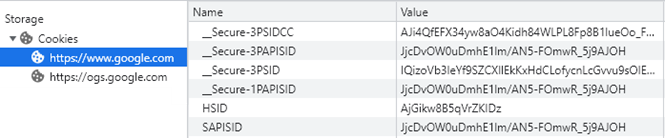
There is no hard technical limit defined in the RFC for the maximum size of an individual cookie, although it is recommended that clients and servers support cookies up to a minimum of at least 4096 bytes per cookie (as measured by the sum of the length of the cookie’s name, value, and attributes).
Cookies have existed since between around 1994 to 1998, when they were established by a young engineer at Netscape Communications Corporation – on various dates – via a patent application, a formal cookie specification (which has been updated and replaced with newer versions several times since), and as a feature added to the then-new “Netscape” browser.
Cookies may be either “session” cookies that are stored only transiently in the browser’s memory for the duration of a single browser session, or “persistent” cookies, which persist for a given duration across multiple sessions and so are stored on the browser’s hard drive – they are therefore able to track visitors between visits to a website, remember their preferences and are stored in the browser for longer.
The data stored in cookies can be leveraged for a variety of purposes including saving information entered into form fields, recording user activity, and for authentication purposes. To understand why this mechanism is needed, we need to look at the situation that would exist in the absence of HTTP cookies. The first usage of cookies was as a session identifier on the Netscape website, and it is still common to see cookies used to store this kind information – It is this which makes them high-value targets for attackers and also which explains the primary reason why cookies are needed at all over and above the basic HTTP mechanism/protocol itself.
The web operates on a request-response pattern between clients (or customers) of a website and the servers that host and operate that website – that is the client issues a request to the server, which the server fulfils, processes, and sends back some response to. The action performed can vary, generally in line with the HTTP verb used in the request (such as “GET”, “PUT”, “DELETE” etc.) and may involve the read, write, edit, or delete of data on the server. The HTTP protocol itself however is an application-layer protocol that is described as being stateless in that a given request from a user cannot intrinsically be tied to any previous ongoing conversation or session containing previous requests. As an analogy it is like talking to someone who has no ability to maintain short-term memories – each sentence you speak to them they are unaware who you are even if you have been talking just seconds previously. Each and every interaction with the server that relies on any kind of user identity can only result in the user having to introduce yourself again, and again, and again with each request made, if relying solely on the base HTTP protocol.
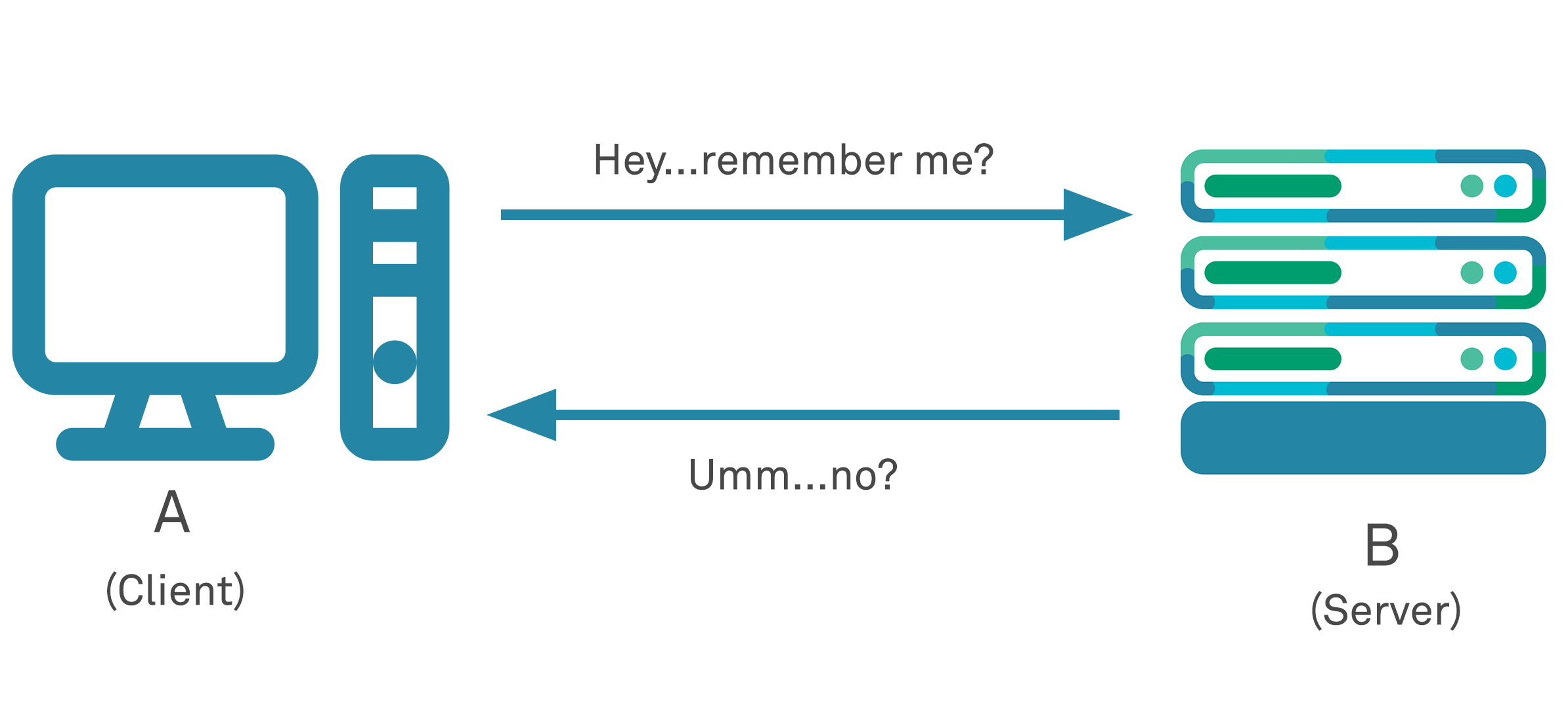
Although this may seem absurd and impractical, it operated this way because HTTP was initially designed to be fast and efficient, and part of its design was to support its initially envisaged usage for users to connect to a website, retrieve a document and then disconnect – there was simply no strong use case for preservation of state and the expense in terms of computational and storage cost that its implementation would involve at the time.
By default, then, a host operating an HTTP server has to treat every new page request from a user as a completely fresh session, free of any prior context. This is obviously problematic for the vast majority of modern websites that rely on the need to understand “who” a user is. For example, clicking “add product to cart” on an online shopping site is only a meaningful request if the server is able to understand which user is making the request, and hence which cart to add the product to. Although it is possible to send all such information along with every single request, it would then also be necessary to provide authentication details with every single request also, in order for the server to establish that a given request is legitimate and authenticated. Since this is not practically feasible, cookies provide a mechanism whereby state can be preserved across multiple requests when running on top of the statement HTTP Protocol. The RFC for HTTP cookies therefore is formally titled “HTTP State Management Mechanism”.
In the case of the need to preserve a user session, a common pattern is to authenticate once and then issue a cookie containing a session token that is uniquely assigned to that customer for the duration of their session, removing the necessity for them to re-authenticate on every single page request. Instead, the customer’s browser simply provides the server with the session token that it (the server) generated for the user. The server can then look up in its own storage all details of the session for that session token, such as the user’s username, authentication status, shopping cart contents (in this example) and other details.
The name of the engineer at Netscape Corporation who was responsible for the original formal specification and patent on HTTP cookies was Lou Montulli, and he has documented how he re-used the name “cookie” from an existing computing concept of a “magic cookie”, which is more common parlance at the time on Unix systems in particular for any token or short packet of data passed between communicating programs. The term “magic cookie” in that context itself is known to derive originally from the concept of s-called “fortune cookies”, a cookie with an embedded message in that, and that itself most likely originated from Japanese omikuji or tsujiura senbei sometime in the 19th or early 20th century.

As an analogy, this is reasonably accurate in understanding the basic purpose and usage of cookies, and one will continue with analogy below in understanding how cookies are used and the vulnerabilities that they can be subject to – as a basic model it helps to think of the cookie as a message baked into a cookie in a commercial restaurant kitchen (the server) which then exists in a state that cannot be read (since it is baked into the cookie) and is transported or carried through a public/open area (the restaurant) by a waiter, where it is delivered to a waiting customer (the client).

Let’s say you type http://www.example.com into your browser. When you hit the Enter key, your browser sends a request to the server for its homepage. Just before the browser sends this request, it will perform various operations to prepare contextual metadata to package with the actual data in the request. As part of this process, the browser will look on your computer to see if there are any cookies previously received from and therefore associated with the server (domain) that the request is to be sent to. If it finds a cookie for the site in question, then the browser sends that cookie (or cookies) to the server, along with the rest of the request data and metadata.
A website may issue one or more cookies to a given client (the specification recommends support for up to at least 50 be implemented by both clients and servers), each identified by a name that acts as its ID. The origin server uses each cookie to send state information to the user agent of the visiting client, and for the user agent to return the state information to the origin server. This technique allows clients and servers that wish to exchange state information to place HTTP requests and responses within a larger context, an ongoing or continuous series of linked transactions that is called a “session“. This context might be used to create, as in our example above, a “shopping cart”, but there are many other potential uses.
Technically therefore, a cookie is described as creating a stateful session within a sequence of HTTP requests and responses. It makes use of two HTTP headers (part of the metadata that a browser automatically attaches to each request sent to the server and vice versa):
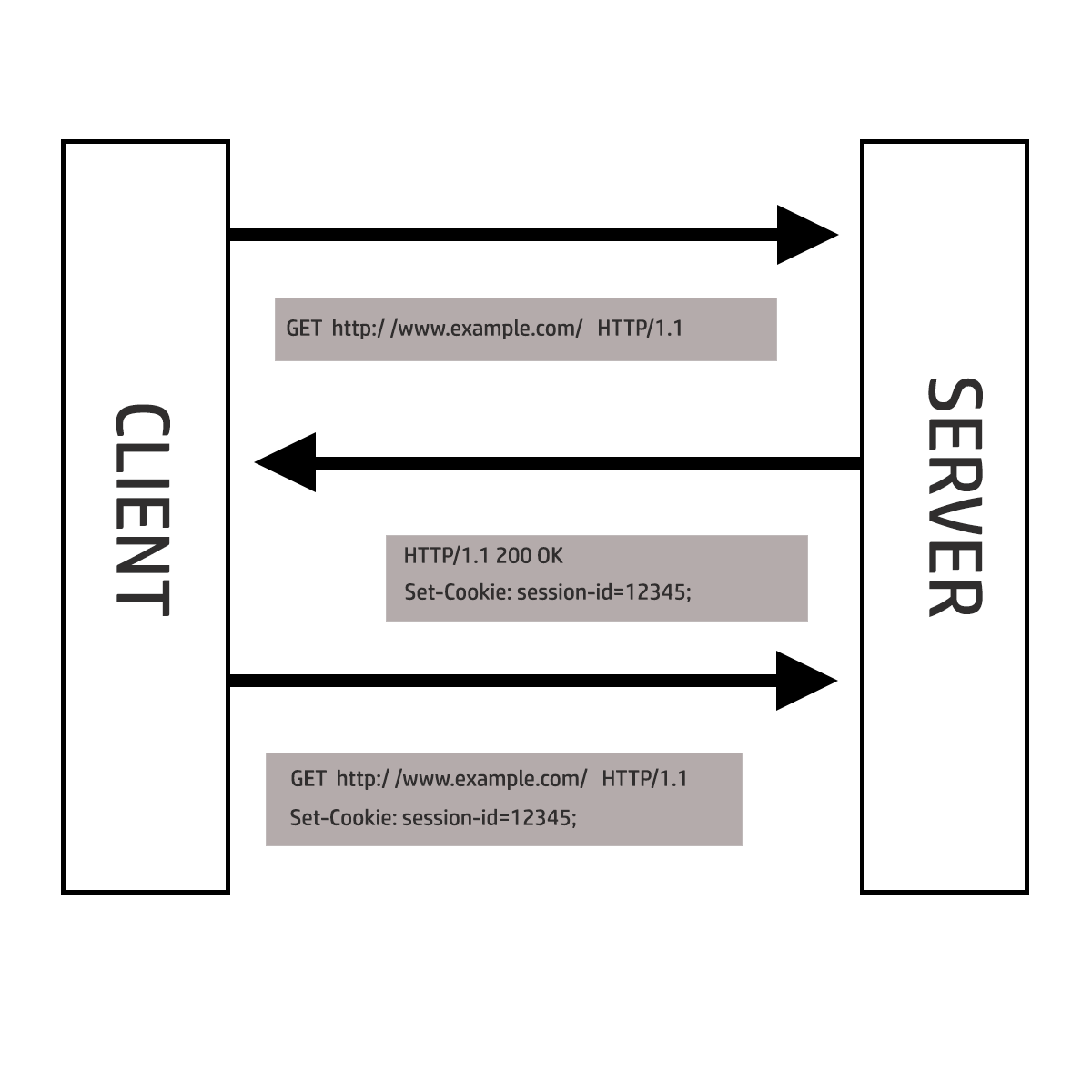
Using the Set-Cookie header, a server will send the client browser a short string in an HTTP response that the client browser will then automatically return in all future HTTP requests (that are within the scope of the cookie), bundled along with the actual request data.
As a common example, once a user has authenticated and proven their identity to the server, a server can send the client browser a “session identifier” named session-id with the value 12345. The client browser then returns the session identifier in subsequent requests as a stand-in for conducting a full re-authentication from scratch and hence maintaining an ongoing stateful connection.
Cookies themselves are relatively harmless. They can’t contain malware or viruses and are not executed so cannot practically contain executable code – they are nothing more than relatively short text strings.
However, cookie handling mechanisms at both the server and client side can introduce vulnerabilities to the operating web application and leave it, or client data, susceptible to exploit.
We introduced the analogy of a restaurant above, with the three components involved in the handling of cookies being the commercial kitchen at the rear of the restaurant (the server); the transmission of the cookie through the public/open restaurant area by the waiter (the internet); and the cookie’s delivery, handling and storage by the customer at their table (the client browser). We will extend this analogy by looking at what can go wrong in each of these three areas below.
Failing to set the “HTTPOnly” flag
When the cookies are being prepared by the server then – as with our chef baking cookies in the restaurant kitchen – they have options or recipes as to how to form the packaging cookie, as well as control over the message to place inside it. HTTP cookies therefore have a number of attributes or flags that can be set on them in addition to the core communicable content that they are designed to transmit (the attribute-value pair that we described above). These flags act as metadata that advises the receiving client browser on various properties of the cookie that determine how the cookie and the data within it should be treated. The HttpOnly flag is one of these attributes that directs receiving browsers to prevent client-side script (such as JavaScript) from accessing the cookie data. Without this flag cookies are treated the same as any other addressable data within the Document Object Model (DOM) in being accessible by executing JavaScript on the client side.
The HttpOnly flag is important because it is one of a number of measures that can partially mitigate the risks from Cross-Site Scripting (XSS) attacks against the client [https://appcheck-ng.com/cross-site-scripting] As a brief refresher, in an XSS attack, an attacker is able to inject their own malicious script code to execute on a user’s computer – if this script is able to read the contents of a cookie then it can exfiltrate (steal) any data or information it contains, such as a user’s session ID or personal information. When the HTTPOnly flag is set, conversely, then browsers that support the flag will not reveal the contents of the cookie to a third party via client-side script executed via XSS.
Storing sensitive data directly in a cookie
The most secure pattern for a server to operate is to retain all sensitive information within the server in a secure store, and then to only issue to the client browser a “token” within the cookie, which is simply an access token that maps to this sensitive information and permits it to be looked up. One potential antipattern from a security perspective is to instead transmit the sensitive data itself directly within the cookie value, leaving it exposed to interception and modification both during transit and on the browser (client side).
For example, a cookie could contain “Name=JohnSmith; DOB=1991-03-12”, but if intercepted then this information is leaked. It is far better that the server creates a record in its local database similar to the below:
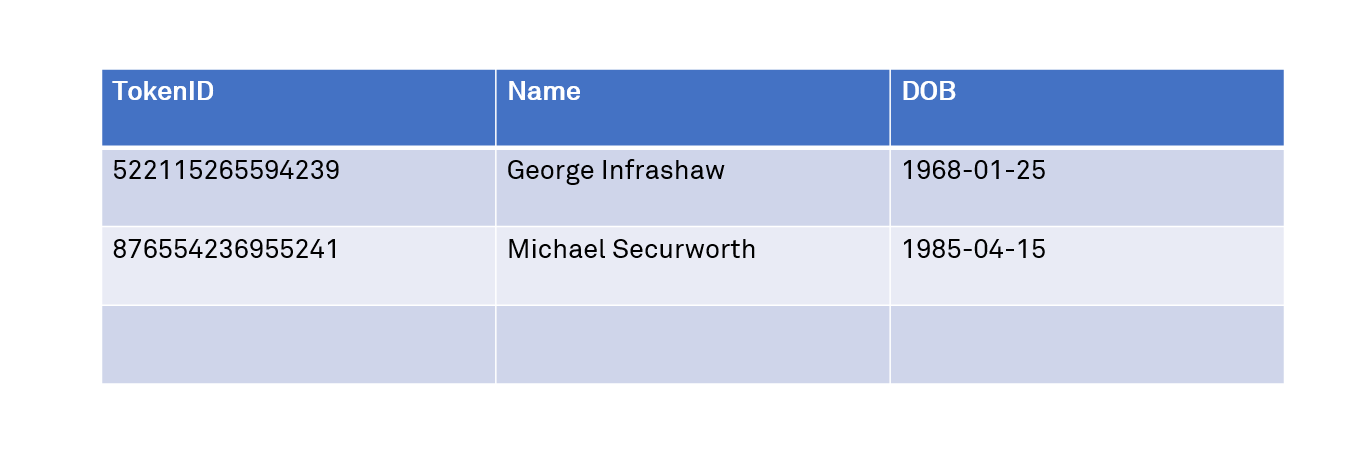
Then the cookie needs only contain the token value “TokenID=12378324987334267”. Even if leaked, this is itself meaningless to an attacker – an attacker gaining access to the token can still potentially authenticate with it if it is being used for such a purpose, but if not, then the user confidentiality is not compromised.
Storing sensitive information in a cookie without setting ‘Secure’ attribute
The “Secure” attribute for cookies ensures that a receiving browser is instructed to only return that cookie back to the origin server in subsequent requests if a secure (HTTPS) channel is being used, and not over a plaintext (unencrypted) HTTP connection.
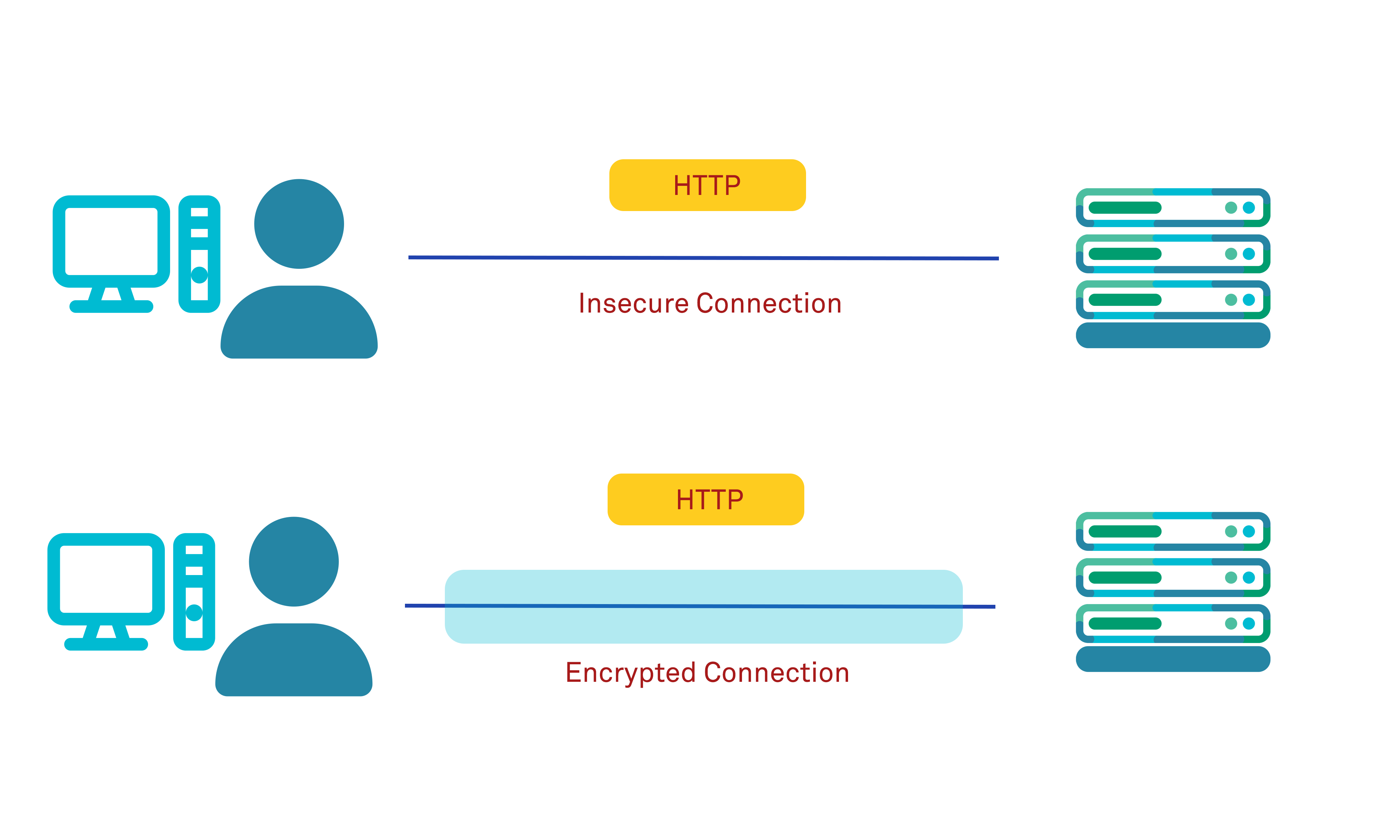
If this flag is not set, then a sensitive cookie could be transmitted back to the server across an insecure channel, leaving its contents subject to interception or hijacking, a form of a man-in-the-middle (MITM) attack in which a suitably positioned attacker on the network between the client and server is able to eavesdrop on the communication between the client and server and read the cookie content that is being transmitted.
Failure to set reasonable Session Expiration period for cookie
Cookies by default are session cookies meaning that they exist only in a browser’s memory and are discarded and lost once the user ends their session with the website. However, a web application developer who wishes to persist the storage of variables at the client side in order to allow a persistent state across a longer period of time is able to create a persistent cookie by setting either the expires or max-age attributes when setting a cookie. The former indicates the date that the cookie should be stored until, and the latter indicates the number of seconds until the cookie expires.
Whilst having some data preserved across a greater period of time than a single session can be great for website usability and user tracking, failure to set a reasonably short session expiration deadline can aid attackers by expanding the effective attack window for certain attack types. For example, an attacker may manage to intercept or otherwise obtain a valid session ID – this doesn’t have to be a highly technical “hack”, it may simply be another user accessing a web site from a shared computer that the valid user has used and then left (such as at a library, Internet cafe, or open work environment): the attack window during which an attacker is able to then compromise the user session by submitting the session token as their own and “hijacking” the session via replaying of the session ID is directly equal to the period of time that the cookie is accepted as valid.
Setting a sensitive cookie with an improper “SameSite” attribute
One of the basic features of the web is that of interconnections and (relatively) open access to resources. This means that a web application served to a client from one origin or domain (e.g., www.example-organisation.com) may return a HTML response containing a <script> tag instructing a client’s browser to load a resource from another domain, such as www.example-thirdparty.com, a domain that may be unrelated and owned and operated by another individual. This functionality is important in that it enables many of the common functionalities we see on modern websites and that the web depends up on. [https://appcheck-ng.com/secure-inclusion-of-third-party-content]
A server that uses cookies to authenticate users can suffer security vulnerabilities because some browsers let remote parties issue HTTP requests (e.g., via HTTP redirects or HTML forms). When issuing those requests, browsers attach cookies even if the remote party does not know the contents, potentially letting the remote party exercise authority at an unwary server. Also known as the “Ambient Authority” problem, the browser might supply the authorization for a resource designated by the attacker, possibly causing the server or its clients to undertake actions designated by the attacker as though they were authorized by the user.
The SameSite attribute for cookies controls how cookies are sent during these cross-domain requests. This attribute may have three values: ‘Lax’, ‘Strict’, or ‘None’. If the ‘None’ value is used, then a website may instruct client browsers to perform a cross-domain POST HTTP request to another website, and the browser automatically adds cookies to this request. This may lead to Cross-Site-Request-Forgery (CSRF) attacks if there are no additional protections in place (such as Anti-CSRF tokens). [ https://appcheck-ng.com/csrf-cross-site-request-forgery/]
Failure to purge sessions on the server
Although the user session length is governed at the client-side by the Expires and Max-Age cookie attributes, it is obviously equally important that this same session expiration is managed effectively at the server-side. A malicious attacker is perfectly willing and able to submit a cookie after its designated expiry date provided that they are able to intercept or retrieve it from the computer memory or disk, or via a cache or other store. It is therefore important that rather than relying on client-side behaviour that the server effectively enforces session expiration at the server-side in parity with the expiration information sent to the client. Although not strictly a cookie security weakness itself, it is a commonly seen weakness pattern that a server relies on client-side enforcement for security decisions, rather than enforcing that logic server-side.
Enabling Session Forgery via weak session ID creation and management
As we have seen, the cookie mechanism is frequently used to overcome the limitations of the underlying stateless HTTP protocol by establishing a mechanism for acting as an HTTP State Management Mechanism – preserving the browser user’s state by issuing a cookie containing a session identifiers or session ID.
An important characteristic of a session ID is that it adequately establishes the identity of the user session in question – that is, it must perform the roles both of identity claim (identity) and identity proof (authentication). To do this, the server must generate a session ID that cannot be reasonably guessed or reproduced by an attacker. For a large global website with potentially millions of users, the session ID namespace (set of possible session IDs) must be sufficiently large that an attacker cannot guess any valid session IDs even via repeated brute force guessing.
If the session ID namespace is therefore too small, if the server sets session IDs either in a guessable or generated in an insecure way (e.g., sequentially, or using an algorithm based on inputs that are known to an attacker) then a valid session ID may be either guessable or calculable by that attacker. One of the most famous session forgery cases happened back in 2013 when attackers managed to calculate how Yahoo created their session ID cookies, permitting billions of user accounts to be accessed in an unauthorised way by attackers.
Failure to regenerate session ID’s
A user’s interaction and state with a given website is protected by a randomly generated session ID set by the server. The session ID cookie is used throughout a browser’s interaction with the server; from first visiting a web site and authenticating through to logging out or in the case of none-persistent cookies – exiting the browser. If the server fails to change the session ID during the lifetime of the session, and the session ID is accidentally disclosed at any point, the user’s session becomes vulnerable to being “hijacked” by a malicious party. The hijacked cookie can then be used to re-form an authenticated session by the malicious user with the server which originally issued the cookie.
Unlike typical session hijacking attacks, whereby an attacker steals an authenticated session token of a victim, the attacker takes advantage of the server not changing the randomly generated session ID from when the cookie was first set. The attacking party makes the victim use a session token, which is already known, and which can later be used to make requests once the victim has authenticated with it. Attackers can use a session cookie which is already been issued by the server, or in some cases arbitrarily craft a session ID value which will still be accepted by the sever as a valid session. In the case of a remote attack, a common way to set a cookie in a user’s browser is to exploit a cross-site scripting (XSS) vulnerability that exists either on the target application or on a host with the same parent domain. This may also be achievable if the application accepts session tokens as a HTTP GET parameters in the URL.
Failure to validate and encode cookie data
Since cookie data is user-provided, and then processed in some way on the server, it is therefore potentially subject to the same kinds of data validation issues as any other user-provided data. Reliance on cookies without detailed validation and integrity checking can allow attackers to potentially perform injection attacks such as SQL injection and cross-site scripting (XSS), or otherwise modify inputs in unexpected ways.
Including more than one Set-Cookie header field with the same cookie name
It is technically possible in many web server software platforms to issue an HTTP response to a client that contains multiple HTTP headers, each setting a cookie with the same cookie attribute name, but potentially with different values. This is especially common in modern web application infrastructure where application-layer logic may be applied not just at the issuing origin server but via header manipulation of the response in transit, on devices such as Web Application Firewalls (WAFs), Layer 7 Firewalls, Load Balancers, Content Delivery Networks (CDNs), Intrusion Detection Devices (IPS/IDSs), Application Delivery Controllers (ADCs) and more. If a server either sends multiple responses containing Set-Cookie headers concurrently to the browser or sends one response with multiple Set-Cookie headers, then this can lead to either a “race condition” that can lead to unpredictable behavior, or else to unpredictable and uncertain behaviour based on varying client implementations of cookie handling based upon their operating system (OS), browser engine, and user agent application.
Cookie Hijacking / Interception
Unless the cookie is being transmitted over a secure channel between the origin server and client (typically HTTPS over TLS), then the information in the cookies is transmitted in the clear via the request and response headers of the HTTP messages. Attackers who are suitably positioned on relevant network segments along the network path, or located on the same local network can fairly trivially use widely-available tools to extract the cookie from among the other data being transmitted on that network, and read any sensitive information that it contains – not just that but a malicious intermediary with sufficient technical skill could alter the headers as they travel in either direction, overwriting existing cookie values with their own chosen data.
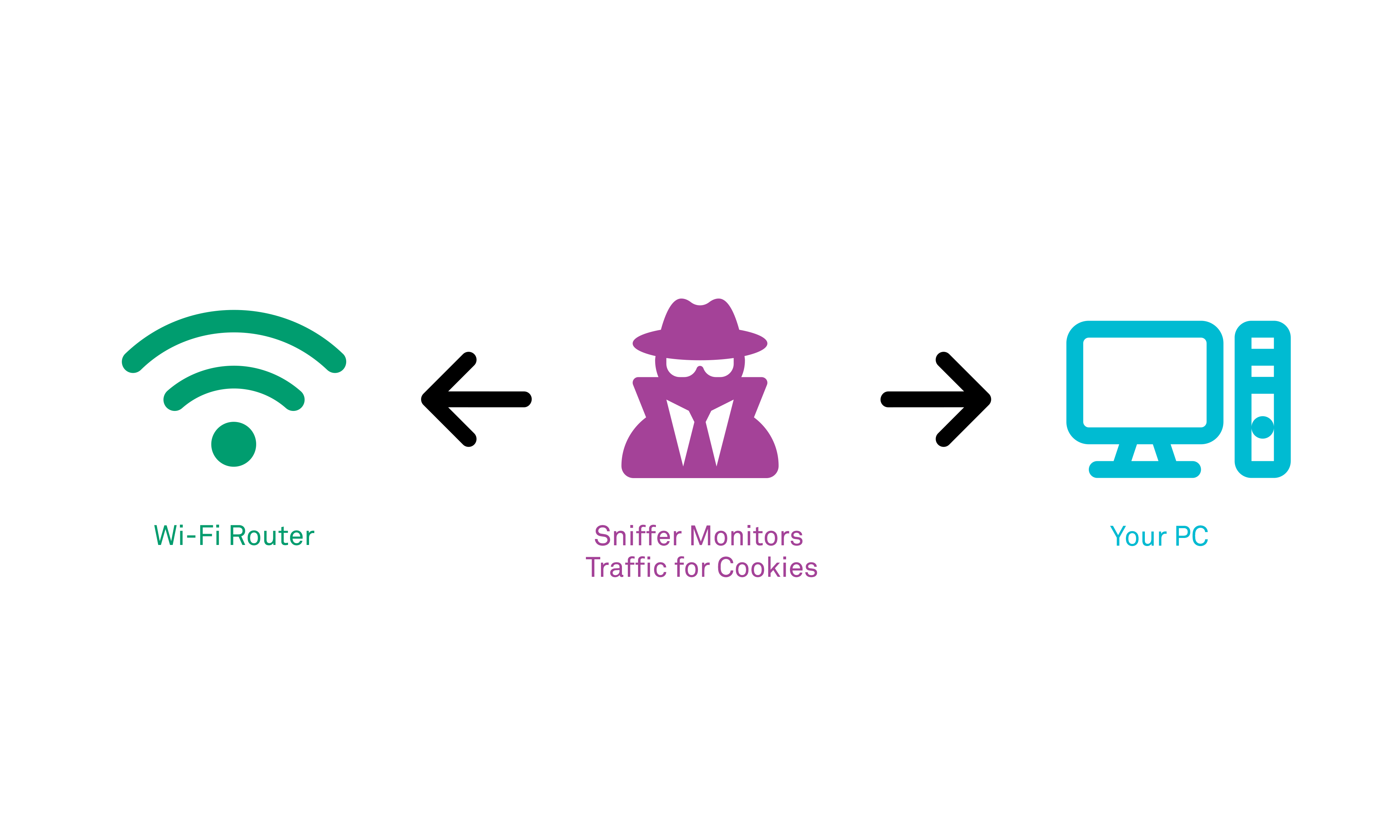
Persistent cookie information leaks
Persistent cookies are cookies that are stored on the browser’s internal storage. This can potentially cause security and privacy issues depending on the information stored in the cookie and how it is accessed – for example if a user shares a computer with others or accesses a website via an internet café or similar, then their cookie values may be inherited by the next user of the computer, potentially disclosing any sensitive information that it may contain. In the case of a session token being retained by the browser’s internal storage, a malicious party could use this as an attack vector to mount a session hijacking or fixation attack and take over the session (and hence identity) of the original user on the relevant website/domain.
Client-Side Cookie Poisoning
Web applications can make the mistaken assumption that data passed to the client in cookies is not susceptible to tampering and will be returned as issued, however there is no necessity for this to be the case – a cookie poisoning attack can be initiated by a malicious user who manipulates the content of the cookie before the cookie is returned to the web server, something that is very trivial to perform.
If the origin server fails to protect assumed-immutable values from modification – in this case by performing proper validation of data received in the client via a cookie – then this can lead to modification of critical data. For example, cookies commonly store session data as we have seen, as part of a web application’s authentication and access control system. If the cookie is used to directly store and transmit sensitive data, such as user credentials and privileges (as opposed a token that is then used to look up this data within the server-side storage) then the server is relying improperly on the value of the client-provided cookie. For example, a badly written web application may store the username of the currently logged in user in a cookie. Then, the application may use the content of the cookie to check which user is performing a particular operation. If so, the user may change the content of the cookie to impersonate someone else.
Mis-interpreting or mis-applying Cookie specification
If a server either sends multiple responses containing Set-Cookie headers concurrently to the browser (e.g., when communicating with the browser over multiple sockets),or sends one response with multiple Set-Cookie headers, then this can lead to either a “race condition” that can lead to unpredictable behavior, or else to unpredictable and uncertain behaviour based on varying client implementations of cookie handling based upon their operating system (OS), browser engine, and user agent application.
Denial of Service Attacks
Although there is limited guidance in the formal specification (RFC) for HTTP cookies regarding how many cookies should be accepted for a given domain, the exact number is subject to implementation decisions by the developers of a given user-agent (browser) and the underlying browser engine that it implements. Browsers may choose to set an upper bound on the number of cookies to be stored from a given host or domain name or on the size of the cookie information, but if they fail to do so then a malicious server could attempt to flood a browser with many cookies, or a small number of cookies of a massive length, on successive responses. This could potentially cause memory or processing denial of service on the receiving browser. Additionally, a browser may operate a limited-capacity shared cache of cookies from which cookies are evicted if it reaches capacity – extremely large cookies or an extremely large number of smaller cookies issued by a malicious server may trigger unexpected behavior within the browser, such as flushing or forcing out or evicting other (valid) cookies that the user agent had received from the same or other servers.
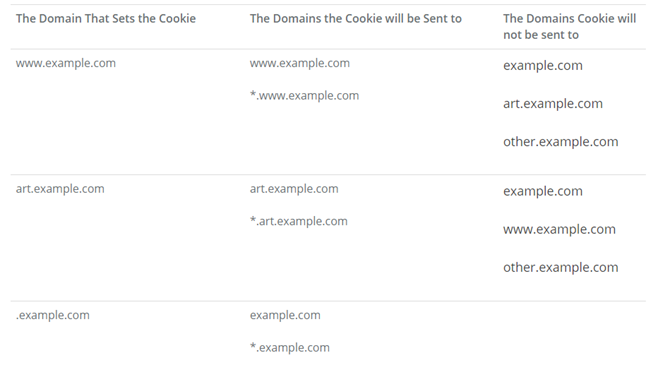
Undermining Cookie Integrity by failing to consider sub-domain handling
Cookies may contain attributes such as “domain”, in addition to flags like the HttpOnly, and secure that we have already looked at. The domain attribute specifies the domain for which the cookie is valid and tells the browser to which websites it can be sent with the request. It is an optional value, and in case it’s left empty, the top level domain name that the cookie is set by will be used. If you use an IP address to access the website, you’ll see this IP address in the value. However, cookies understand the concept of origin slightly differently than the Same-origin Policy (SOP). [https://appcheck-ng.com/secure-inclusion-of-third-party-content/]. Website A cannot set a cookie belonging website B, even if they specify the domain attribute accordingly. Due to security measures, such attempts are blocked in both server and client side.
However, a cookie may be used in multiple subdomains belonging to the same domain – that is, cookies do not provide integrity guarantees for sibling domains (and their subdomains). For example, consider foo.example.com and bar.example.com. The foo.example.com server can set a cookie with a Domain attribute of “example.com” (possibly overwriting an existing “example.com” cookie set by bar.example.com), and the client browser will include that cookie in HTTP requests to bar.example.com. In the worst case, bar.example.com will be unable to distinguish this cookie from a cookie it set itself. The foo.example.com server might be able to leverage this ability to mount an attack against bar.example.com.
As we have seen, cookie security is a complex subject and there are a number of issues to consider. However, the main bullet points can be summarised as below. Please note that all these measures may limit application flexibility and usability and should all be tested carefully before implementation on a production system:
AppCheck help you with providing assurance in your entire organisation’s security footprint. AppCheck performs comprehensive checks for a massive range of web application vulnerabilities – including cookie security weaknesses – from first principle to detect vulnerabilities in in-house application code.
The AppCheck Vulnerability Analysis Engine provides detailed rationale behind each finding including a custom narrative to explain the detection methodology, verbose technical detail, and proof of concept evidence through safe exploitation.
AppCheck is a software security vendor based in the UK, offering a leading security scanning platform that automates the discovery of security flaws within organisations websites, applications, network, and cloud infrastructure. AppCheck are authorized by the Common Vulnerabilities and Exposures (CVE) Program as a CVE Numbering Authority (CNA).
As always, if you require any more information on this topic or want to see what unexpected vulnerabilities AppCheck can pick up in your website and applications then please get in contact with us: info@localhost