In this article we are going to take a look at one of the newer technologies used in modern web applications, the “WebSockets” that were standardized by the Internet Engineering Task Force (IETF) in 2011. In contrast to many technologies used within modern web applications, WebSockets are not a language or tool that relies on the underlying HTTP protocol for transport. Rather, WebSockets use their own protocol, at the same layer of the network stack as HTTP, and browsers can make use of and switch between the two protocols using a hand-off mechanism.
However, to understand exactly what security issues may arise with web sockets – in particular Cross-Site WebSocket Hijacking that is the focus of this article – it’s necessary to first take a step back and look into what WebSockets are, why they are used, how they operate, and in what respects they differ from traditional HTTP-only communication.
The vast majority of web traffic uses the venerable HTTP v1.1 for transport, which dates right back to 1997. Major revisions of HTTP are currently underway to introduce and increase adoption of version 2.0 and version 3.0, which aim to progressively resolve some of the restrictions and inefficiencies that HTTP v1.1 presents to modern web applications. However as of 2019/2020, HTTP v1.1 still accounts for around 50% of web traffic and HTTPv3 is not yet enabled by default in any mainstream browser.
Every time you make a request to a webserver over HTTP (the layer 7 “application” protocol that your browser understands), the data and metadata that comprise the request are encapsulated and passed to a lower level protocol within the network stack. At a high level you have an abstracted software layer known as the application layer which is then encoded at lower and lower levels, ending up as binary streams (“1010101010001”) that are ultimately encoded as electronic or light-based signals and transmitted via a physical medium such as cable or radio wave:
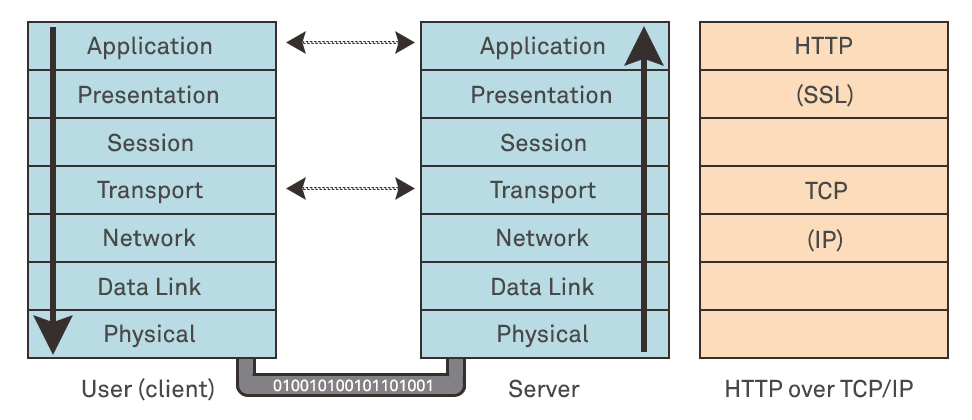
This may seem a bit abstract, but the reason why this is important will become apparent shortly. Critically, HTTP requests are transmitted over TCP (“Transmission Control Protocol”) connections for both HTTP 1.1 and HTTP 2.0.
In the first version of HTTP (v1.0), individual requests were viewed as isolated, standalone entities. There was essentially a one-to-one mapping between HTTP requests for web document (HTML documents) and the rendering of a “webpage” within your browser.
Later developments under HTTP 1.1 such as Asynchronous JavaScript and XML (AJAX) allowed clients to send and receive data asynchronously (in the background without a page refresh) to the server using a combination of JavaScript and the XMLHttpRequest object, in order to update page content. However, AJAX requires the client to initiate the requests and wait for the server responses, known as “half-duplex”.

As complex dynamic web applications have grown, web developers have looked for a better mechanism for communication between client and server that offers the asynchronous transfer of data between clients and servers, whilst also permitting the initiation of data transfer in the opposite direction – from servers to clients – without an initiating client request and at scale, something that HTTP is not able to offer in its client-server architecture.
In a theoretical full-duplex system, both parties (client and server) would be able to communicate with each other simultaneously and when either desired. An example of a full-duplex device is a telephone; the parties at both ends of a call can speak and be heard by the other party simultaneously. The earphone reproduces the speech of the remote party as the microphone transmits the speech of the local party, because there is a two-way communication channel between them, or more strictly speaking, because there are two communication channels between them.
In order to understand why such a system might be useful for web applications, consider a webpage such as the election feed on election night, or a running text commentary on a major sporting event on a news website. In both instances, we can imagine a client who visits the site and wants to see the “latest” content, but as soon as the page has loaded for them, the content is out of date and is not being updated. A crude method of overcoming this is simply to have each user mash the “F5” button to refresh the page continuously. However, it is possible for developers to overcome this slightly more elegantly under AJAX with a “client polling” technique in which each client aggressively polls (regularly sends requests to) the server, effectively asking if there is an update. Neither solution is really ideal and generates a high volume of requests that are effectively empty with no useful data.
WebSockets get around this fundamental limitation by implementing a completely new protocol, which works at the application layer, the same as HTTP, above an underlying TCP connection. The system allows the client to make an initial “half-duplex” request to the server using the standard HTTP protocol in order to request the establishment of a ‘full-duplex’ WebSocket protocol connection for further, full-duplex communications between the two:
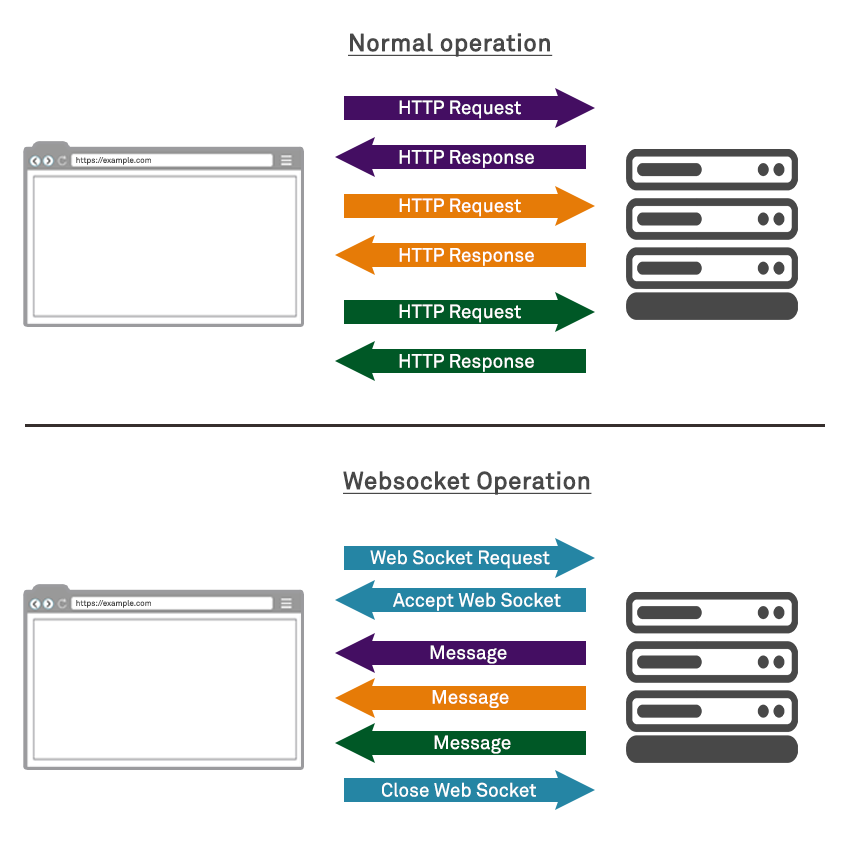
This delivers a (two-way) communication channel, allowing the client and server to truly communicate asynchronously. In our example above, once the initial “news” page is loaded, no further communication occurs until the server has an update that it is ready to publish, at which point it pushes the update to those clients with established WebSocket connections (clients who have accessed the page and not yet terminated the connection by closing the Web Socket).
WebSockets conduct their initial ‘upgrade’ handshake over HTTP and from then on all communication is carried out over TCP channels by use of frames. This handshake effectively upgrades the communication protocol to ws:// (or wss:// for TLS protected channels) via “The WebSocket Protocol” (RFC 6455).
The typical life-cycle of a WebSocket interaction between client and server therefore follows the steps:
The WebSocket protocol itself does not prescribe any particular way that servers can authenticate clients during the WebSocket handshake over HTTP. The WebSocket server can use any client authentication mechanism available to a generic HTTP communication link, such as Basic Authentication or the use of session token within cookies. A minimal example using cookies (and showing only key headers) may therefore look like the below:
Client request:
GET /ws/WebSocket HTTP/1.1 Host: www.example.com Origin: https://www.example.com Sec-WebSocket-Version: 13 Sec-WebSocket-Key: bm9zeQ== Sec-WebSocket-Extensions: superspeed Sec-WebSocket-Protocol: wpcp Cookie: JSESSIONID=1A9431CF043F851E0356F5837845B2EC Connection: Upgrade Upgrade: websocket
Server response:
HTTP/1.1 101 Switching Protocols Upgrade: WebSocket Connection: Upgrade Sec-WebSocket-Accept: z3vkEiLEb3Tlhva7BxrNyI6p0U4= Sec-WebSocket-Protocol: wpcp
The client verifies the Sec-WebSocket-Accept header contains the expected value and the status code is 101, then all further communication is carried out within the WebSocket frames.
Note that browsers do not allow custom HTTP headers or body to be included within the upgrade request, however query string parameters are permitted.
Unencrypted Communications
A plaintext WebSocket is established when the handshake is conducted over HTTP (i.e. when the ws:// scheme is used).
Data sent over an unencrypted connection is vulnerable to interception and modification by an attacker who is suitably positioned on the network. This includes the user’s own network, within their ISP, and within the application’s hosting infrastructure.
Additionally an insecure resource (i.e. a webpage loaded over plain HTTP), which then establishes a secure connection to the WebSocket server (using wss://), is susceptible to a positioned attacker injecting JavaScript into the page which can then send and receive data via the WebSocket.
Note that browsers will prevent a “secure” resource from initiating an insecure WebSocket handshake.
Unrestricted Cross Domain Calls
By design, the WebSocket protocol does not abide by the SOP (Same Origin Policy) that usually enforces boundaries separating one domain from accessing another domain’s data within the context of a browser’s session. Because of the missing SOP restriction, a browser is able to initiate a cross-domain WebSocket call to any domain on the Internet. This can potentially introduce security threats in that it allows an attacker to force a victim’s browser to initiate a connection to an endpoint that they control, or to any third party endpoint. A crude exploit of this may be to abuse a victim’s computer to perform Denial of Service (DoS) attacks against victim servers by opening multiple WebSocket connections.
Cross-Site WebSocket Hijacking (CSRF with WebSockets)
The lack of SOP enforcement also allows an attacker to put a malicious page on the Internet and entice users to that page. For example, an attacker could perform an attack similar to the below:
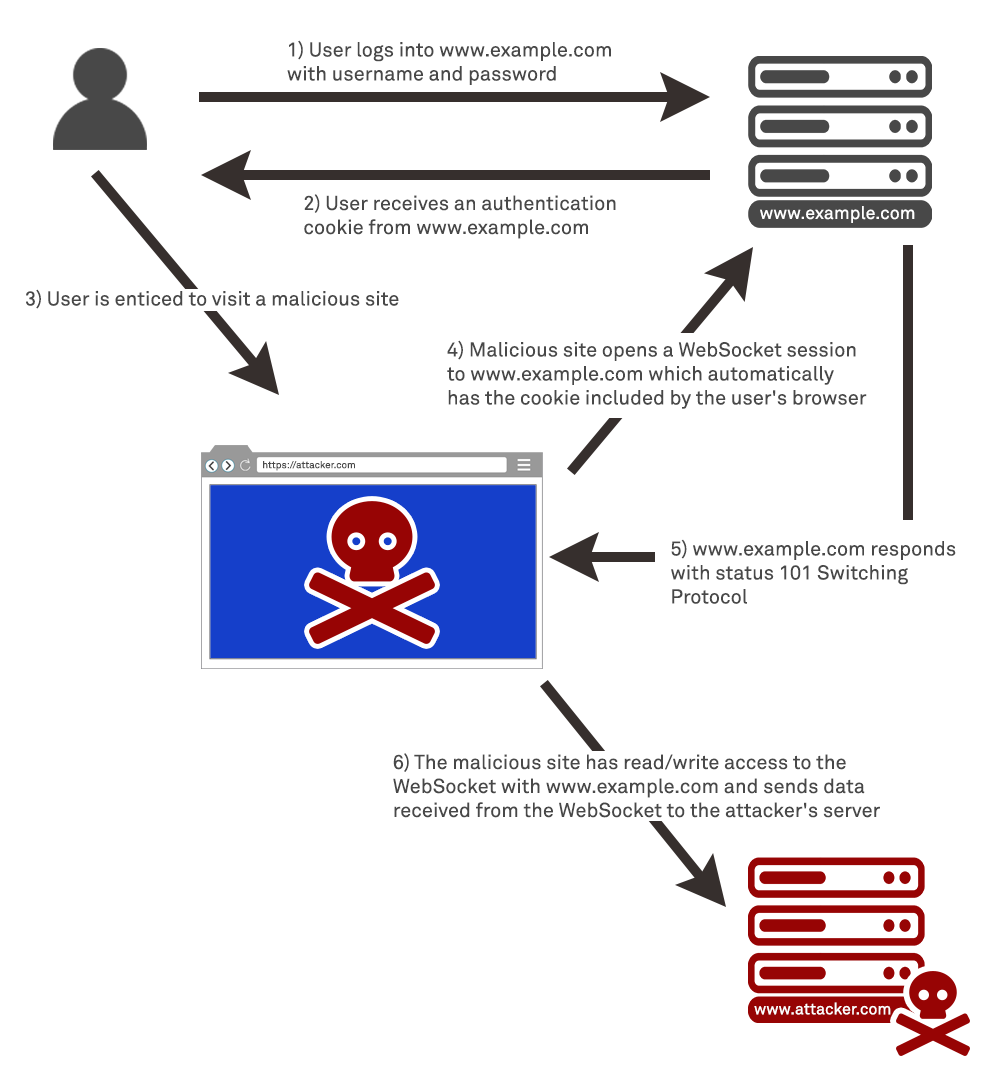
Web Application Vulnerabilities
WebSockets are merely a transport mechanism, therefore practically all web application vulnerability categories, including but not limited to those in the OWASP Top Ten, are still a concern for applications using WebSockets.
Encrypted Communications
All communication should be conducted over a secure connection (TLS) from beginning to end.
Ensure the server redirects all clients connecting using HTTP to HTTPS, ideally utilising HTTP Strict Transport Security (HSTS) to prevent the client from initiating an unencrypted connection to the site in the future.
Reject WebSocket upgrade requests received over an unencrypted connection.
Ensure any WebSocket URLs served by the application use the wss:// scheme rather than the ws:// scheme.
Ensure any applications connecting to the WebSocket are served over HTTPS, ideally utilising HTTP Strict Transport Security (HSTS) to prevent the client from initiating an unencrypted connection to the site in the future.
Origin Header Validation
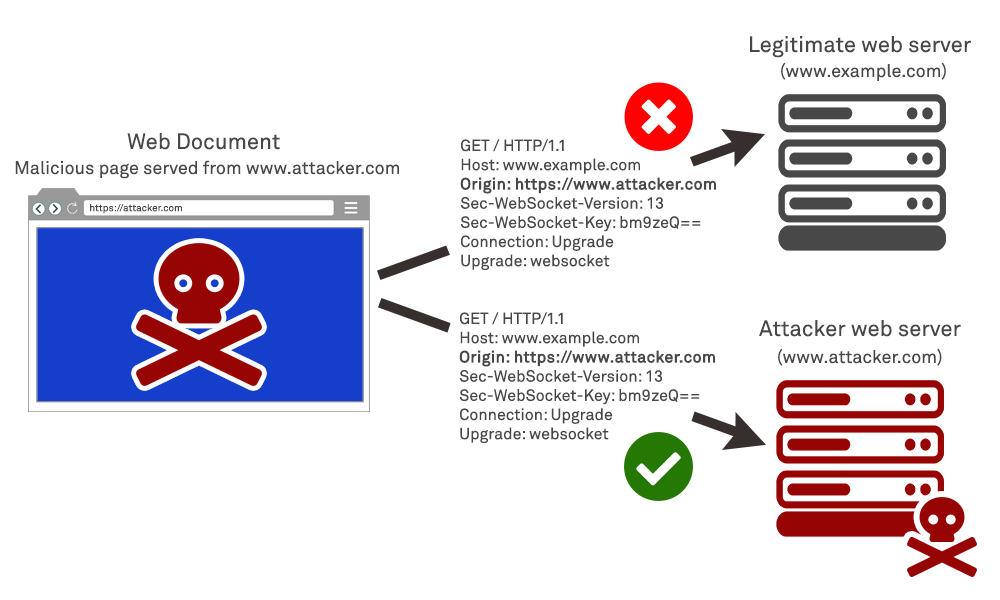
Ensure that the server is properly configured to verify and validate the contents of the “Origin” header received from the client over HTTP in its WebSocket handshake initiation request. When the client makes an “upgrade” request over HTTP, it sends an HTTP request header such as Origin: https://www.example.com within the HTTP request headers, as we saw in the example above. In typical usage, the client’s browser itself adds this header automatically based on the serving origin of the page within the current Document Object Model (DOM).
The Origin header is actually a special type of request header known as a forbidden header in that the user agent retains full control over it and it cannot trivially be set by an attacker even where they are able to execute malicious script within the user’s browser.
Since an attacker is unable to set or override the Origin header, it is therefore possible for a server to prevent attacker-initiated cross site WebSocket connections from compromised victim browsers. To do so the server must validate the domain in the Origin header and confirm that the page making the request is on a trusted domain. Most typically, this would be the same domain that the server itself is serving pages from (a.k.a the same origin) – i.e. the page making the request to open the WebSocket was (according to the user’s browser) itself served from the server now being contacted to open a WebSocket. If the origins do not match, the server can refuse to open a WebSocket connection and return a 403 Forbidden HTTP response code to the handshake request.
It is important that the method of verifying the origin is complete, allowing only those origin which are intended to communicate with the server. Some of the common pitfalls when implementing origin validation are:
CSRF Tokens
Use of the Origin header alone is not guaranteed to prevent cross site requests in all instances, if for example there is a bug in a browser implementation that permits an attacker to forge the Origin header, or for browsers that simply do not implement Origin header usage. As part of a “defense in depth” strategy, it is a good idea to use a second prevention mechanism also, one that can be enforced server-side regardless of client browser.
The most common anti-CSRF mechanism implemented is the use of “tokens” that are submitted by the client on the handshake request and verified as valid on the server. The principle is that when a client requests a page, the server includes an unpredictable value (token) which is uniquely bound to the user’s individual session in page. When the JavaScript which establishes the WebSocket connection is executed it first reads the token from the DOM then includes it within the handshake request and/or WebSocket messages to the server; the server must then verify it matches the one that it issued. In the CSRF attack scenario the attacker can never get the token because the Same Origin Policy (SOP) prevents them from reading the response that contains the token.
It is generally inadvisable to submit CSRF tokens in a URL as these may be stored in various locations, including the user’s web browser, the server and in any forward or reverse proxies. If an attacker can recover the token they may be able to use the token to interact with the application as part of a CSRF/CSWSH attack. However as the WebSocket handshake requires a GET request where custom HTTP headers cannot be added, separate two tokens may be appropriate:
Same-Site Cookies
Assuming cookies are used to pass authentication information within the application, the final measure against such attacks is Same-Site Cookies which are the same as regular cookies, but with the addition of the SameSite attribute, for example:
Set-Cookie: SESSID=12345678; SameSite=Strict
Enabling this attribute on the cookie will instruct the browser to not send the cookie on any cross-origin request, however support is not yet common across all browsers.
AppCheck helps you with providing assurance in your entire organisation’s security footprint. AppCheck performs comprehensive checks for a massive range of web application vulnerabilities from first principle to detect vulnerabilities in in-house application code, including WebSocket Origin validation issues. AppCheck also draws on checks for known infrastructure vulnerabilities in vendor devices and code from a large database of known and published CVEs. The AppCheck Vulnerability Scanner provides detailed rationale behind each finding including a custom narrative to explain the detection methodology, verbose technical detail and proof of concept evidence through safe exploitation.
As always, if you require any more information on this topic or want to see what unexpected vulnerabilities AppCheck can pick up in your website and applications then please get in contact with us: info@localhost