“XSS” and “SQLi” are household names within web application security – vulnerabilities that will be known by name, if not in exact detail of implementation, by almost everyone working within the IT sector. “Cross-Site Leaks”… isn’t. But Google web security researcher Krzysztof Kotowicz recently predicted that it’s only a matter of time until this little-known vulnerability may soon make it into the industry-standard OWASP Top 10 list. It’s a bold claim, and perhaps a little pre-emptive for the foreseeable future, but this class of techniques is certainly gathering momentum and finding its way from research papers and early proofs of concept into broader usage. As awareness of the methods reach a wider audience, attackers will doubtless find ways to expand, enrich and exploit the techniques further. So what is XS-L, how worried (if at all) do you need to be, and how can you protect against it?
As you’ll likely already know, web pages are simple documents written in Hypertext Markup Language (HTML), a pretty simple form of markup that can be read “raw” as source code, or else rendered and displayed in the browser window. The Document Object Model (DOM) is a way of representing the objects that comprise the structure and content of a document on the web as an addressable hierarchy of nodes and objects in a tree. It underpins how every web browser interprets and renders web pages that are received from the server. This allows various programs to perform programmatic reading and writing of the document dynamically. Programs such as browsers can read the DOM to interpret the document structure, style, and content in a web page in a standard manner, and scripts such as JavaScript that operate client-side can address can interact with and read or write these same elements, changing the page’s rendering and behaviour.
One of the basic features of the web is that of interconnections and (relatively) open access to resources. This means that a webpage served to a client from one domain (eg www.example.com) may return an HTML response containing an IMG tag instructing a client’s browser to load a resource from another domain, such as www.example.net, a domain that may be unrelated and owned and operated by another individual.
This functionality is important in that it enables many of the common functionalities we see on modern website and that the web depends up on, for example:
1. Allowing developers to create websites that load simple static resources such as images from an image hosting site or external source such as a content delivery network (CDN);
2. Allowing a user to upload a profile picture on one website such as an ID service and then have the picture display on a different website such as a forum or social media site;
3. Allowing developers to make use of shared resources such as common open-source libraries and scripts that are located on provider websites; or
4. Allowing marketing teams to integrate content such as videos or adverts from a different provider on their own site.
This concept is basic to the web and is often known as a “web mashup”. However, in a web where rich functionality allows modification of the DOM, where sites may instruct the local browser to cache and store authentication information such as tokens and cookies, and where some sites are malicious, a protection measure is needed to restrict the ability of resources from these differing domains and zones of trusts to access data stored on the client’s browser relating to other domain.
The concept of the “Same-Origin Policy (SOP)” was introduced as a security concept to manage interaction between resources of different origins by Netscape within their “Navigator 2.02” browser product in 1995. It was added largely in response to the introduction of JavaScript in Netscape 2.0, which enabled dynamic interaction with the DOM. Under the policy, a web browser prevents a script loaded from one origin from obtaining access to sensitive data on a page loaded from a different origin through that page’s Document Object Model. In turn this also prevents any malicious script from accessing the content of a different origin.
The origin doesn’t entirely coincide with the domain alone – web resources (or more accurately the URLs that they load from) are determined to have the same origin if the protocol (eg HTTP or HTTPS), port (eg 80 or 443), and host (eg www.example.com) are all the same for both resources.
The way that the SOP is delivered means that cross-origin reads are typically disallowed. This means that sites can still embed content from external sources – such as HTML iframes, a method of embedding or “framing” another website within existing HTML, to deliver those adverts or YouTube videos mentioned in our examples above – but in such a way that they do not grant the serving site for the loaded material the ability to read the DOM it is loaded within, or to view user interaction fired as actions within that DOM. The SOP therefore ensures that web mashups can continue to be used, but in such a way that helps to prevent potentially malicious changes.
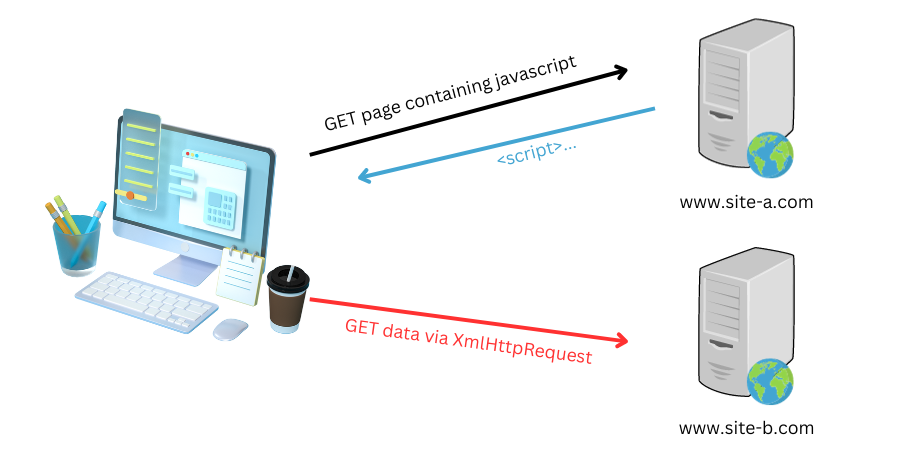
There are a few ways in which the Same-Origin can be bypassed to a greater or lesser extent. Many of these rely on the DOM API – the set of JavaScript functions that define interactions with the hierarchy of objects within the DOM, and the restrictions that they place (or don’t place) on access to document elements. In some very narrow circumstances, the API permits documents or elements from different origins to directly reference one other. When two documents do not have the same origin, these references provide very limited access to document objects such as Window and Location objects, depending on the browser in question.
So why is this a problem?
Lets look at an example, one that leverages the fact that the History DOM API relating to the history object can know how many entries there are in the history of the user, even where those history entries do not relate to the same origin as the domain querying the API. Lets consider an example in which a malicious site embeds an iframe containing a web resource to be loaded. It cannot directly determine the response of that resource, however by manipulating the history object it can, nevertheless, gain an inference as to whether the resource loaded, by whether the history.length function returns an incremented count after the call. In effect, information has been leaked from about the user in relation to their activity on that “victim” site.
In attacks similar to the above example, information on visitors to websites can be determined and reported on that would not normally be available. It is possible to determine relatively trivially if a user has access to certain resources, even though enumerating a set of likely candidate resources would be exhaustive and difficult to successfully exploit on a large scale with the techniques outlined so far. The primary exploits envisaged so far relate to information disclosure relating to private data – allowing individuals access to given websites or social networks to be objectively determined, which could cause embarrassment to some individuals if publicly disclosed.
In some cases, metadata that can be determined about the requests made to other origins via examination of alternative channels, such as timing information, can even reveal the size and contents of data such as the user’s shopping cart on a given online store. This information could conceivably allow attackers to create context-aware phishing attacks individual users are presented with custom phishing pages that match stores that are in the process of using or have very recently used, greatly increasing the success rates of the phishing attacks if the exploit is conducted at scale.
However, Cross-Site Leaks vulnerability refers to a whole raft of browser side-channel techniques. Given how immature the technique currently is, the likelihood is that both:
A direct network timing attack simply measures the time that a given website takes to respond to HTTP requests. It can be used either in a direct boolean determination (“is the user logged in to www.example.com ?”), or in a richer way to determine more complex conditions/states, such as estimating data sizes. However, network based attacks are difficult to implement since the decision logic can be inaccurate due to noise from inconsistent underlying network operation.
With basic direct network timing attacks, it is only possible for malicious code to make decisions based on resources that are public (ie accessible to anyone). Cross-Site Timing techniques allow an attacker instead to make requests as a specific user, using that user’s preferences and login credentials in order to find out information that is visible to that user alone, within their private context. In order to manipulate the requests from within this context, an attacker needs to be able to perform a form of cross-site request forgery to enable their malicious site to obtain information about the user’s view of another site.
“Cross-site search” is a specific form of cross-site timing attack that can be used, in which the differences in resource fetch times between resources that a user can and cannot access betray information to a script in another origin, violating the Same-Origin Policy.
“HTTP Cache Cross-Site Leaks” are a variation on an XS-Leak attack that involves deleting the HTTP cache for a specific resource before forcing the browser to render a website and, finally, checking if the browser cached the resource that was originally deleted. This allows an attacker to figure out if a website loads a specific resource or not and reveals information on whether the user has access to a specific resource. To understand why this might be useful to an attacker, imagine if the resource was an image that was only available in a given Facebook group such as (in this example) a race-hate group. Being able to determine that the user in question was able to access that resource demonstrates their access to the resource and hence their group membership. It reveals information about the user in violation of the Single-Origin Policy and could be used in further attacks such as social engineering or extortion attacks against the user.
“Cross-Site Frame Leakage (CSFL)” is a further variant that exploits the cross-origin properties of HTML iframe elements to determine the state of a vulnerable application. When loading a resource in an iframe, a malicious script located on one origin can infer information about whether content requested in another iframe could be retrieved or not – if the content in question requires specific group membership on a social media site for example, then it can be inferred that the given user again is a member of a specific group. It is possible to imagine numerous variants of this technique.
Attacks of this type to date have been relatively few, but in one recently example Facebook found a bug in its API that could have impacted 6.8 million users, allowing access to private photos by an attacker.
Preventing Cross site leaks requires precautions be taken starting with the software development lifecycle (SDLC) to prevent a robust series of measures that together reduce the overall risk.
In general, any website that contains a control flow statement that depends on sensitive data could lead to timing vulnerabilities – in practice that means that pretty much every dynamic web application that deals with personal or sensitive data will potentially be vulnerable. For example, an application that retrieves a list of records from a database and then selectively decides which ones to display will be vulnerable to leaking the total number of records at a minimum.
If specific search queries can be executed then an attacker will be able to use differential timing evaluation to make inferences about the data. Much as in a boolean blind SQL injection attack, the technique will often only be able to be teased out through making a large number of requests with subtly different inputs to tease out one bit of information at a time.
One defense against Cross-Site Timing attacks in particular is to ensure that where a web server makes a decision or contains a control flow statement that depends on sensitive data, that it always takes a constant amount of time to return data to the client in response to a request. This can be achieved by padding all request times out to an identical time value with a sleep function or similar, in order to reduce exposing information via a side channel. However, this technique may be implausible in many use cases, and does not prevent other forms of XS-L such as inference based on DOM API function manipulation that we explored above.
AppCheck is a software security vendor based in the UK, offering a leading security scanning platform that automates the discovery of security flaws within organisations websites, applications, network, and cloud infrastructure. AppCheck are authorized by the Common Vulnerabilities and Exposures (CVE) Program as a CVE Numbering Authority (CNA).
As always, if you require any more information on this topic or want to see what unexpected vulnerabilities AppCheck can pick up in your website and applications then please contact us: info@localhost