Every web application, whether purchase commercially off the shelf (COTS), provided as a cloud application service (SaaS), or deployed on-premise by an in-house development team, relies on the same basic principles of interaction in order to provide a dynamic experience: a user is presented with a (typically) HTML-based user interface, containing one or more interactive elements such as hyperlinks, forms, buttons and other elements. When a user explicitly interacts with one of these elements (or if an event is otherwise triggered in client-side script such as JavaScript) then – regardless of whether the application is a “traditional” web application or a single-page application (SPA) making use of an API – an HTTP request is generated and sent to the server, where it is processed, and a response returned to the waiting client.
What makes a web application interactive – and hence a true application rather than a static webpage – is that each HTTP request can vary in one or more ways for a given action even if generated from the same “starting page” and the same page element, dependent on factors such as the user identity and any content (data) they submit through form fields.
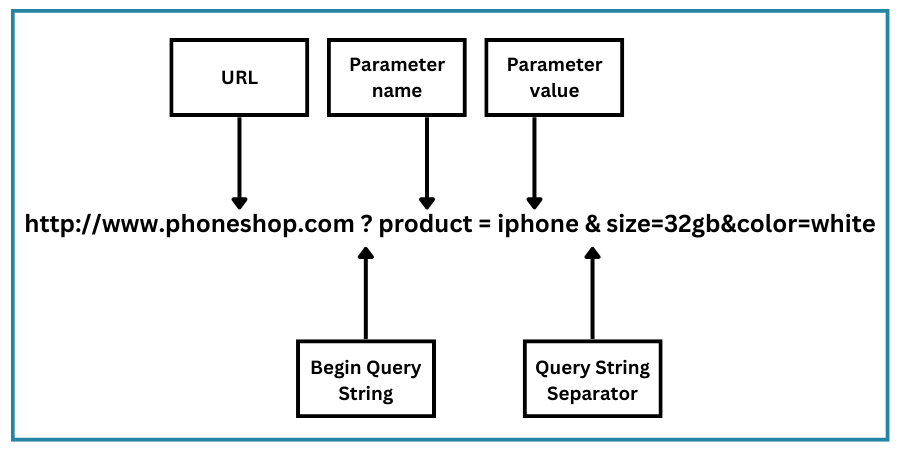
The variable input data is submitted most commonly within either GET requests (making use of the query string suffix portion of a requested URL itself), or within POST requests (where the URL is “static”/unchanged for each submission and the data parameters are contained instead within the body of the request itself)
GET Request with query string:
POST request with (encrypted) payload (parameters in body):
When a developer writes code to handle input provided by the user, their primary concern – understandably – is the functional requirements of the code. That is, “does the code do what it is supposed to do?”. In the example of a page containing a form requesting a user’s name for submission to the server, the functional requirement might be to receive the user’s name and add it to a database – the code is functionally successful or functionally operable when it delivers on this requirement. A developer who has written such code would necessarily test the code by at a minimum running some examples through it and checking that the names are written to the database as expected. In a Test-Driven Development (TDD) or other environment, the code may be accompanied by (or only written after) the production of test cases and a framework to test that the code operates as expected.
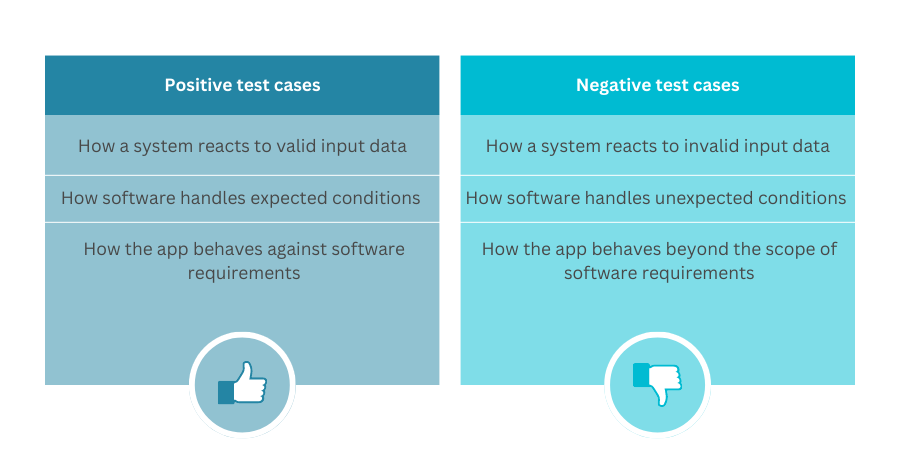
However, it is still less common to see full coverage of negative test cases – that is, to see how the code in question reacts to data that is invalid, unexpected, or otherwise not imagined that it may have to handle. Even where there has been such a consideration, it is incredibly difficult to rigorously define a comprehensive list of all potentially invalid inputs covering all scenarios.
A developer may assume that the “form handler” code that processes their form will only receive data from that form, and so they have some knowledge of and control over the input that is expected to be provided. But since the form exists on the client-side, and since it is the client that submits any form data, that client (in the case of a malicious attacker) is free to establish the endpoint that the form sends data to, and then simply throw any number of requests at the endpoint, with any parameters that you choose.
This is fuzzing. Application fuzzing provides the opportunity to test dynamically (that is, against a real deployed instance of the code) and at a high rate a very large number of such negative test cases that all aim to subvert the expectations of the developer’s “happy path” of code execution and make the application behave in some unforeseen way that can potentially be exploited.
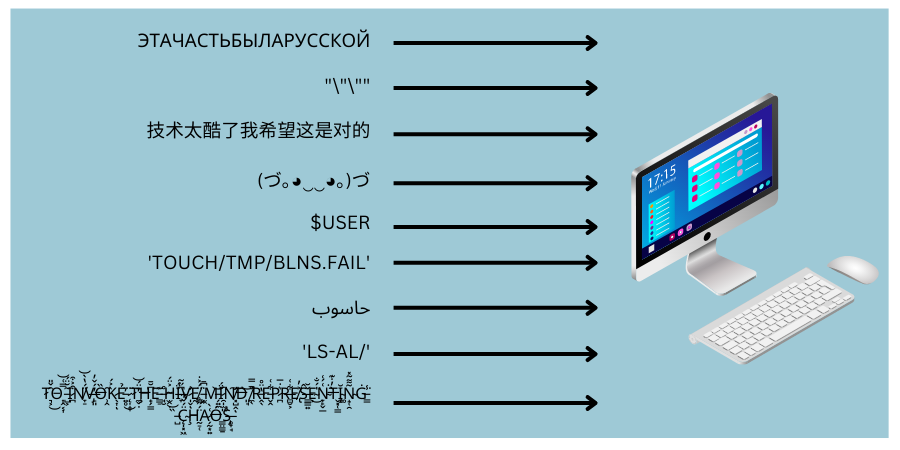
Application fuzzing operates by providing invalid, unexpected, or random data as inputs, and observing how the application behaves in response. This primarily (though not exclusively as we shall see) involves alteration of one or more parameter values. The data provided can be whatever the attacker chooses:
In general, there are three principal types of data input that are most likely to elicit an unexpected response from the web application, and result in an exploitable vulnerability. Although software engineering is a relatively young discipline, the terminology has been used in fields such as mechanical engineering for a lot longer:
Fuzzing is performed using code that executes several functions referred to collectively if informally as a fuzzer. A fuzzer that is specifically designed or utilised for probing for security vulnerabilities (such as that within a vulnerability scanner) will typically attempt to generate semi-valid inputs that are “valid enough” to not be rejected outright by the input parser or form-handling code on the server – yet are sufficiently unexpected to exploit opportunities provided due to a lack of explicit and considered handling within the server code. By doing this, the fuzzer looks to trigger unexpected behaviours “deeper” in the program (that is, in the code that is downstream of the initial form handler) and are “invalid enough” to expose corner cases that have not been properly dealt with. Since code can often rely on the initial parser/handler to sanitise or validate input, code that is “screened” behind this is often designed to handle only “happy path” input, believing that the parser will screen it from any malicious input. It can therefore be vulnerable if it can be reached.
Fuzzers are sometimes classified as either unintelligent (UF) and intelligent (IF) where the latter is able to use knowledge of the expected input (either in advance or gathered during testing) to adapt and inform later fuzzing requests. This intelligent fuzzing can be either mutation-based or generation-based but the objective of both is the same: to increase the likelihood that submitted parameters/data will be sufficiently valid to be processed/accepted, whilst containing sufficient variation or diversity between requests to test the application’s response to a broad range of unexpected values. Since the intention is to invoke a flaw in the application under test, the data must be sufficiently valid to be accepted, whilst being sufficiently unexpected to trigger unexpected application behaviour.
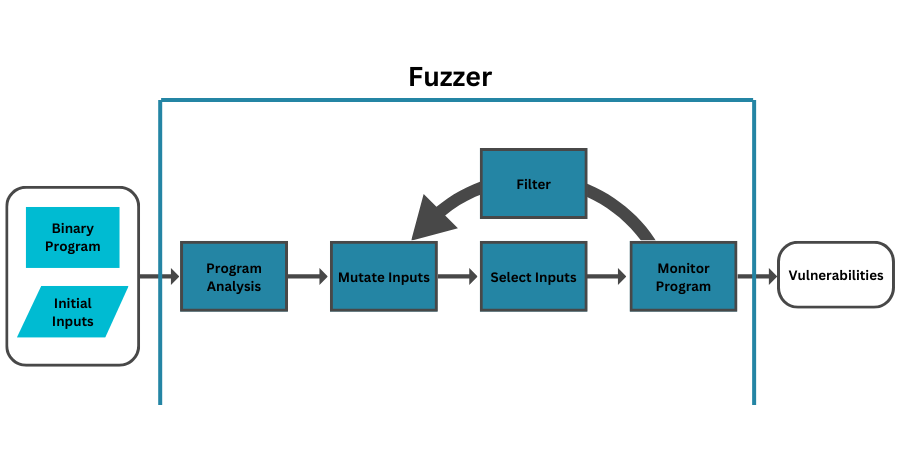
An effective fuzzer generates inputs that are “valid enough” in that they are not directly rejected by the server but may not have been considered by the developer – as we saw earlier, this typically involves parameters or parameter combinations that represent edge, boundary or corner cases.
Some examples may include:
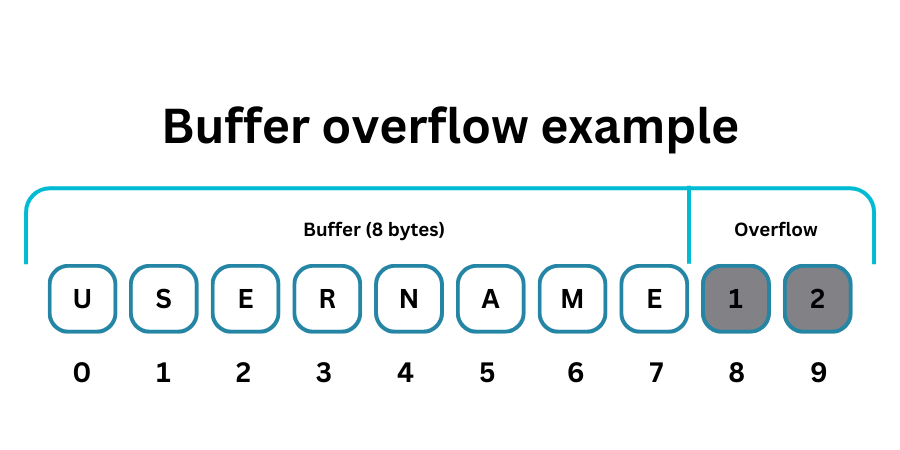
However, within dynamic web application fuzzing in particular, the most fruitful and commonly used form of input fuzzing is to attempt to inject interpretable characters that have some “special” meaning within various languages used on web application and database servers. These may include characters that represent “end of line” (EOL), line feed characters, or new line chars. The intention with these is to break out of the “data” context and into the “code” context within the server. This is explained more in our blog post on XSS and there is no room to go into a deep dive of how this operates here, but essentially it is sometimes possible to inject special characters into an input parameter that make the server mistakenly execute input following that character as if it were trusted and genuine code written by the developer.
The greatest part of web application fuzzing focuses on changing the content of parameters from within the query string of the URL. The fuzzer will analyse the construction of the query string, identify parameters within it, and then produce a list of “forked” response variants, each containing a different candidate value for one of the parameters to be submitted:
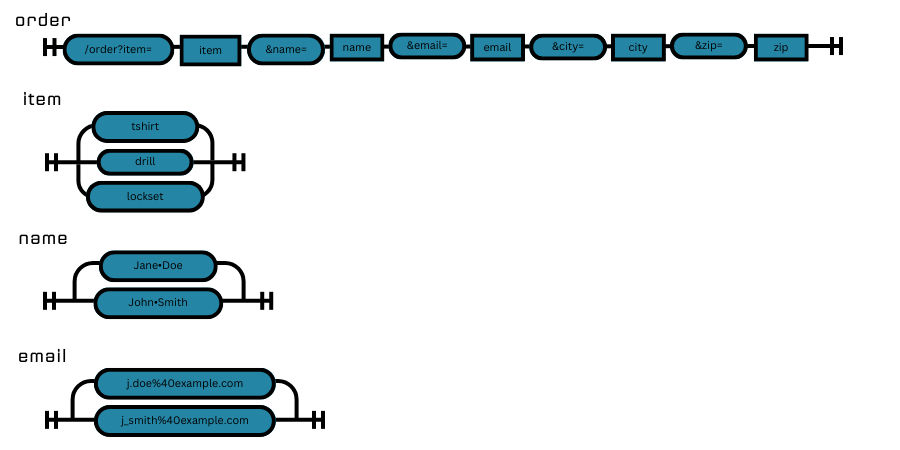
However, the fuzzer may also insert additional extra parameters that might commonly be seen “such as admin=1”, or leave off/crop out certain parameters the server expects, or else submit the same parameter twice, but with different values – this last example can sometimes cause unexpected or inconsistent behaviour /be interpreted differently if one element in the network stack (such as a WAF) reads (and makes logic decisions based upon) the first value and a second element (such as the webserver itself) does the same but using the second (different) value.
Additionally, any part of the HTTP request can be “fuzzed”, including:
GET /index.php?page=admin.php&username=jonny&password=dog HTTP/1.1 Host: localhost User-Agent: Mozilla/5.0 (Windows NT 5.1; rv:27.0) Gecko/20100101 Firefox/27.0 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8 Accept-Language: en-US,en;q=0.5 Accept-Encoding: gzip, deflate Referer: http://example.com/ Cookie: PHPSESSID=dkfdsfdsdf65656565656efphh0 Connection: keep-alive
Testing of corner cases can involve simultaneously altering the expected content of the query string at the same time as adjusting other meta parameters (such as request rate/volume), in order to uncover particular vulnerabilities involving code flaws such as exploitable race conditions, non-idempotent actions, deadlocks, out-of-sequence behaviours and other workflow issues.
Fuzzing on its own is only a method of varying the inputs sent to a server. In order to be useful within the context of a vulnerability scanner (or to a theoretical attacker) then it is also necessary to monitor the results in terms of the responses received from the server for each request made. Since the number of potential variants in input is enormous, fuzzers typically operate at a very high request rate, and so analysis of the responses needs to be automated within code. The code specifically needs to determine what a “normal” or expected response looks like, what an atypical response looks like, and – where an explicit payload such as attempted SQL injection via special characters within parameters – to be able to determine if the attempted exploit has been successful or not.
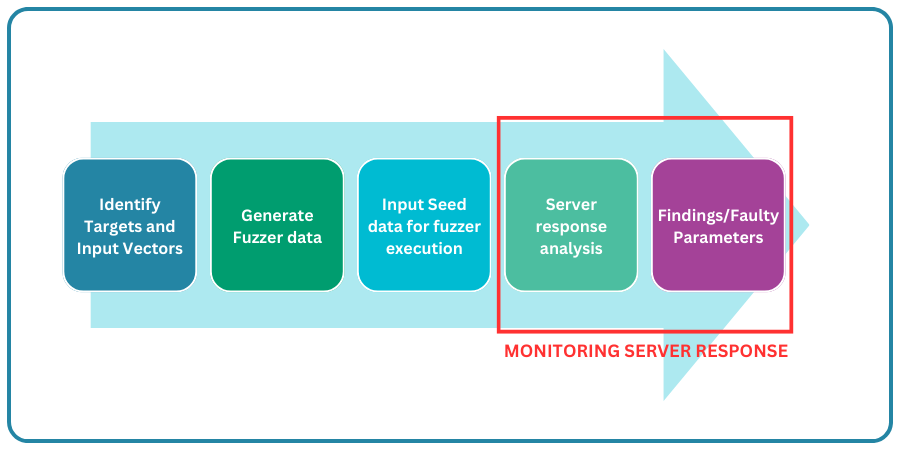
Uncovering simple unconsidered edge cases can be as simple as observing the returned HTTP code that accompanies the server response and looking for 4xx/5xx response codes, but it can also include parsing of verbose error output. Some forms of attempted exploit, such as “blind” SQL injection attempts require highly sophisticated processes to determine their success, since it cannot be directly determined based on the server’s HTTP response(s).
A web application fuzzer can be used to test for buffer overflow conditions, denial of service conditions, error handling issues, boundary checks, and parameter format checks but by far the most common vulnerabilities uncovered by this technique are the various classes of “injection” vulnerabilities – including command injection, SQL (database) injection, and cross site scripting (XSS) vulnerabilities.
Some vulnerability scanning can be done relatively passively, that is performing simple network requests during which the scanner sends no unusual or malformed requests to the server. Fully passive scanning silently analyses existing (genuine) network traffic to identify endpoints and traffic patterns and does not generate any additional network traffic. Semi-passive scanning also exists in which the scanner does make connections to a server/endpoint target, but at a basic protocol level to check for open ports and services, or to make simple HTTP requests that any normal user might make. It carries almost no risk of disrupting critical processes by interacting directly with the endpoints.
By their very nature, fuzzers submit attack payloads with their requests. That is, they deliberately submit parameter data that is intended to elicit an atypical response from the server – they therefore represent an “active” (rather than passive) form of vulnerability scanning and there are a few considerations to bear in mind:
AppCheck help you with providing assurance in your entire organisation’s security footprint. AppCheck performs comprehensive checks for a massive range of web application vulnerabilities – including injection vulnerabilities and buffer overflows – from first principle to detect vulnerabilities in in-house application code.
The AppCheck Vulnerability Analysis Engine provides detailed rationale behind each finding including a custom narrative to explain the detection methodology, verbose technical detail, and proof of concept evidence through safe exploitation.
Our proprietary scanning technology is built and maintained by leading penetration testing experts allowing us to understand how a penetration tester or attacker would explore a given application, utilising visual cues and ruling out equivalent instances of the attack surface if they have already been explored.
AppCheck is a software security vendor based in the UK, offering a leading security scanning platform that automates the discovery of security flaws within organisations websites, applications, network, and cloud infrastructure. AppCheck are authorized by the Common Vulnerabilities and Exposures (CVE) Program as a CVE Numbering Authority (CNA).
As always, if you require any more information on this topic or want to see what unexpected vulnerabilities AppCheck can pick up in your website and applications then please get in contact with us: info@localhost