A successful exploit of a DNS rebinding attack turns a victim’s browser into a proxy for attacking screened devices on the user’s private network, which are not exposed to the public internet. Rather than being a “standalone” vulnerability, it is typically used to enable further, onward attacks against devices that an individual or organisation may believe are inaccessible to attackers. DNS rebinding attacks aren’t as well known of or understood by organisations in the same way as household-name exploits such as “XSS”, and so many organisations may not have explicit protection measures in place.
Historically used primarily to exploit vulnerable consumer-tier Internet of Things (IoT) devices such as home automation systems and consumer CCTV cameras, there is growing concerns that attackers may begin to use DNS rebinding techniques to attack corporate networks. The challenge for attackers in targeting better-maintained and screened corporate networks is greater, but so too are the rewards. Because DNS rebinding attacks rely on the combination of two factors that organisations do not typically already address or restrict – the fact that browsers typically execute any JavaScript provided by default and without user prompt or permission, and the acceptance by clients and firewalls of DNS responses with low TTL values from off-network – many organisations are likely vulnerable to DNS rebinding attacks.
In this article we’ll run through a brief “tech refresher” to look at the underlying mechanisms that DNS rebinding attacks are able to exploit, investigate how the attack is performed, and finally look at why enterprises may be at greater risk in the future from this attack, and how they can best tackle mitigation.
The first technology involved in a DNS rebinding attack is JavaScript.
The majority of modern websites use JavaScript to provide at least some client-side code execution functionality. Some web applications even process all – or the majority – of their functionality client-side, in an approach termed “Single Page Applications (SPAs)”. However there is little scrutiny by users over what exactly this JavaScript is doing – there is no moderation or oversight of the script functionality by the user.
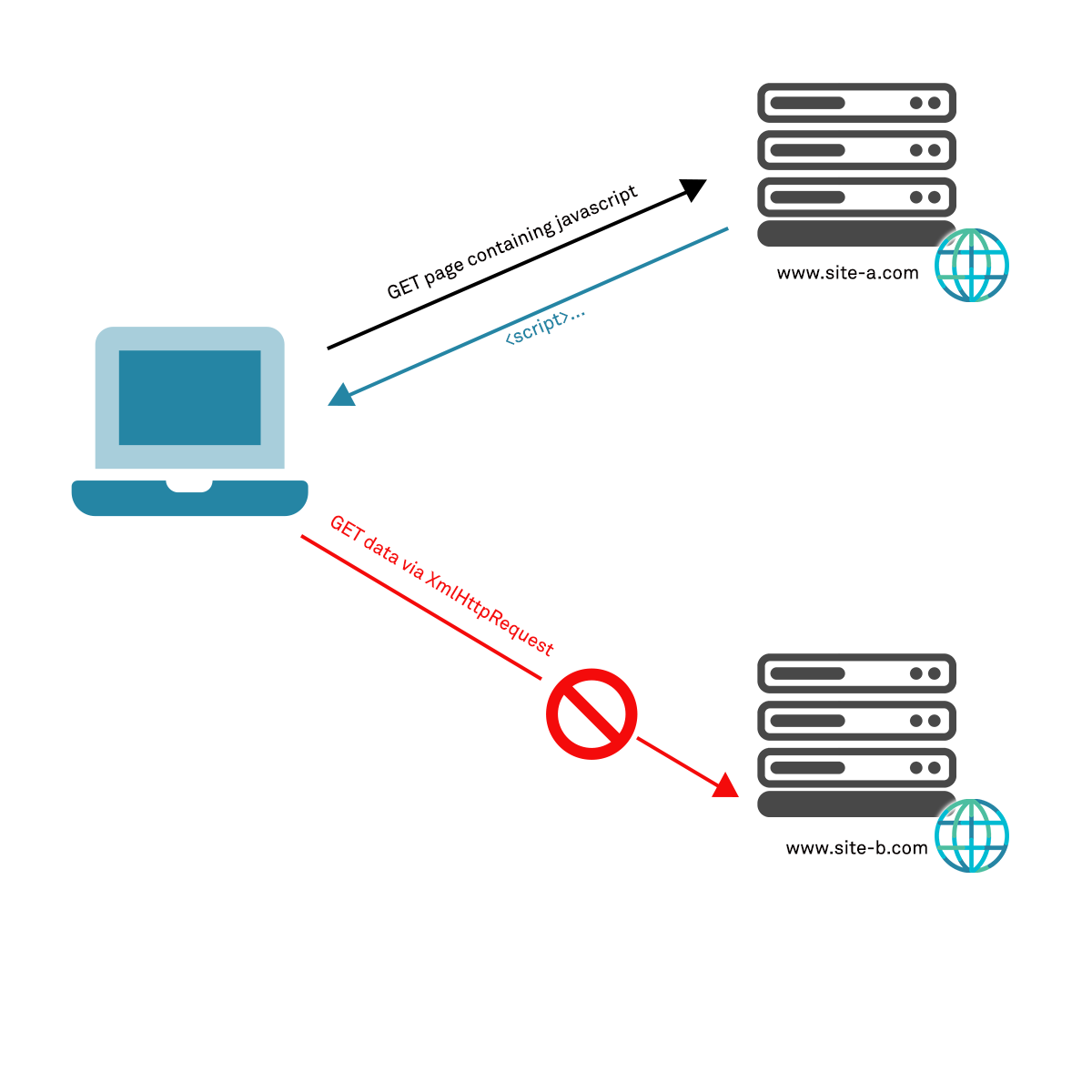
Normally requests from client-side code such as JavaScript are restricted to perform operations on data relating to the origin (protocol, port and domain) that they originate from (that is, that the webpage referencing the client-side script was served from). This is an important restriction that prevents malicious JavaScript from reading the response to HTTP requests it makes to other domains automatically on your behalf (such as to your online banking website). There is a separation of concerns in that it may only act on its own origin.
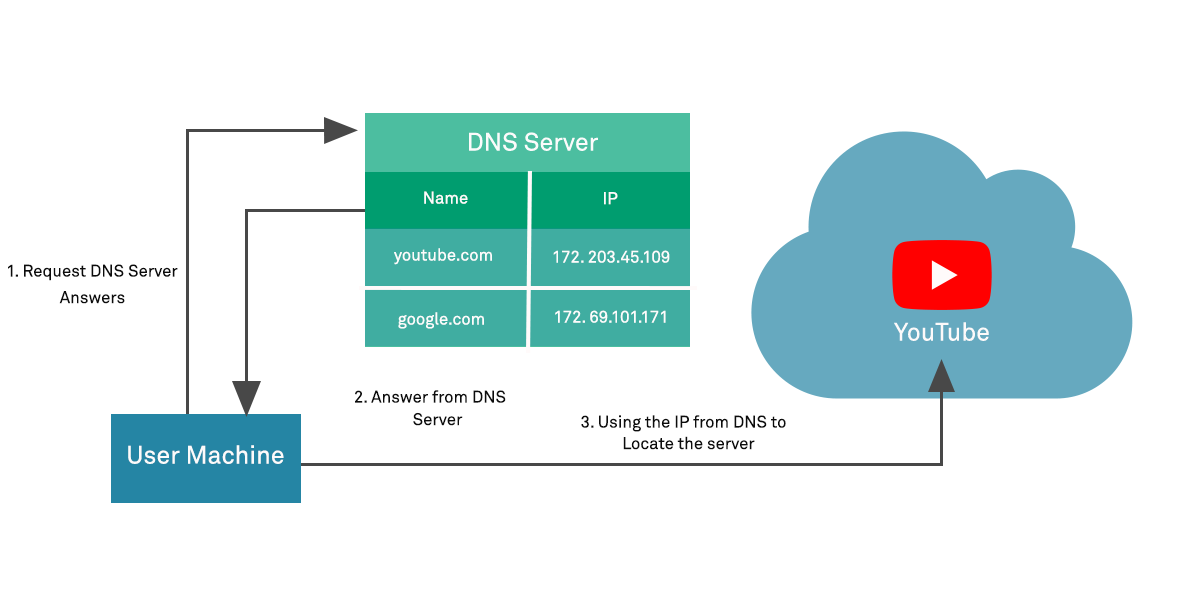
The second factor involved in a DNS rebinding attack is the basic operation of DNS services. The web is based on a system of domains that make it easy for humans to locate services they wish to access. Domain names such as “www.example.com” are trivial to remember. However, the underlying technology that the Internet operates on using a networking protocol stack known as TCP/IP which relies on internet addresses in “IP” format – such as “78.81.132.239” – for routing of network packets.
DNS services are therefore operated to allow clients to perform a lookup to retrieve an IP address that should be used when the client wishes to access a particular domain. For example, a client may have a domain name “www.example.com”, so they send a query to a DNS server for that domain, and the DNS server responds with an IP address the client should use (this is called DNS resolution). For various reasons – such as needing to re-point a domain to a secondary host if the primary were to fail – DNS responses have a TTL (Time To Live) that effectively act as expiry dates for the returned records, after which the client should query the DNS server again in case the record has changed.
As we have seen the Same Origin Policy (SOP) is an important protection measure in ensuring the separation of one origin’s content from another in a browser, and presenting any kind of cross-origin activity or data access. The Same Origin Policy, somewhat obviously, is based fundamentally on a comparison of Origins for data. An origin is unique if it has a given URL scheme (e.g “https:”), host (e.g “www.example.com”) and port (e.g “443”). Critically, the origin is the same if all these three factors are identical for two resources, and the host portion used in the origin assessment may be a human-readable hostname.
Comparing domain names is therefore an essential part of enforcing the Same Origin Policy, so the Same Origin Policy has a critical dependency on DNS to provide accurate mapping of hostnames to IP addresses. If it was possible for an attacker to circumvent reliable domain name resolution via the Domain Name System (DNS), then they may be able to bypass Same Origin Policy protection.
And this is exactly what DNS Rebinding attacks do. They rely on trickery with short TTLs to “rebind” domain names from resolving to one IP address to another. If JavaScript is loaded from a domain that maps to an IP under the attacker’s control, but then quickly swapped to map to a victim IP, the browser can be tricked into accessing the victim IP believing it to be in the same origin (or “zone of trust”) as the executing JavaScript. How exactly does this work?
In a DNS rebinding attack, an attacker first registers a domain, e.g “www.example.com”. This is completely legitimate. They set up two services on their new domain:
1. An HTTP web server, on which they host a dynamic web application, complete with JavaScript; and
2. A DNS server, to respond to client queries for how to resolve their domain to IP addresses. The DNS server is specifically configured to respond with a very short TTL parameter which prevents the result from being cached
The attacker then waits for a user to visit their perfectly normal looking website. The website loads JavaScript in the web application. The JavaScript is written to start firing off HTTP requests using legitimate methods such as XMLHttpRequest or the “fetch()” function to the example.com domain every few seconds in the background. For example:
POST /admin/resetPassword HTTP/1.1
Host: www.example.com
password=Password1
So far there’s nothing unusual here, plenty of legitimate websites perform background HTTP fetches in this way. The first request triggers a lookup of the domain “www.example.com” via DNS, and the DNS server responds with the IP address of the attacker’s server (the same site the webpage itself was served from and that the DOM/origin relates to). Again, everything so far is legitimate and just describes how many dynamic web applications work.
However, what happens now is not normal. The DNS record provided expires due to an incredibly short TTL of just a few seconds, and the attacker has scripted his server to alter its provided responses that the “www.example.com” resolves to. With each subsequent DNS request, the DNS server will return a record mapping to a private RFC1918 address – an address that is likely to exist on the user’s local network but is not presented on the public internet, such as “192.168.1.1”.
The next dynamic AJAX call fires from the user’s browser, targeting http://www.example.com/admin/resetPassword again, only this time resolves the domain in DNS to “192.168.1.1”. The browser faithfully makes a web request to the domain:
POST /admin/resetPassword HTTP/1.1
Host: www.example.com
password=Password1
Only this time, the request is sent to the new IP address resolved via DNS – to http://192.168.1.1/admin/resetPassword – which is their local router and (in this simple example) resets the password to one that the attacker provided.
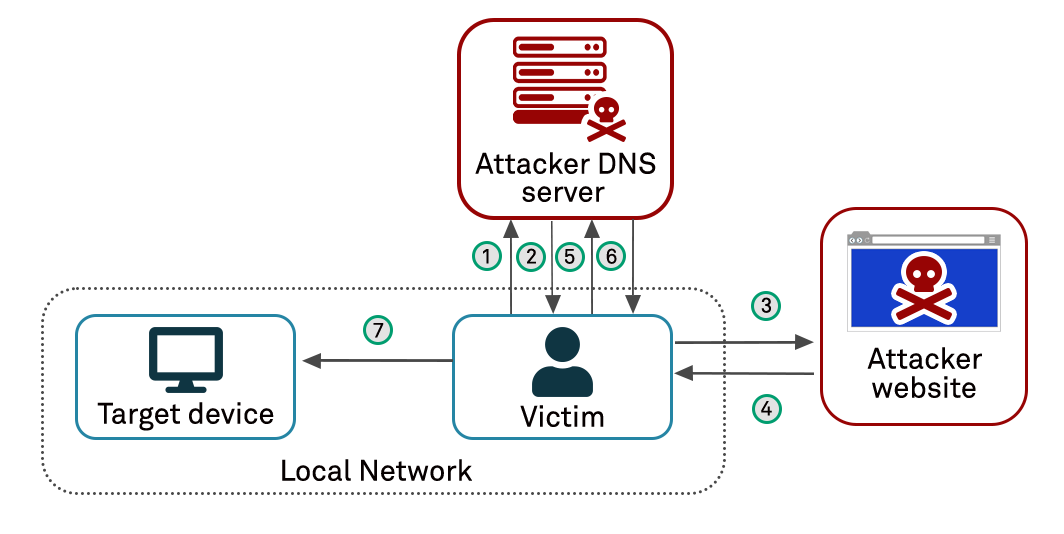
At this point, an attacker can use the victim’s browser as a proxy to access screened local-network devices. scan local IP addresses for devices, and target specific devices with further attacks from a privileged network position. Many devices that are presented on local networks only typically have default passwords, weak passwords or – occasionally – no authentication at all, on the basis that they are not accessible by attackers across the public internet and so do not require strong controls such as strong authentication etc.
In the ideal scenario for an attacker, they will be able to fully compromise one targeted device, and establish a backdoor access channel such as a reverse shell to their own server, and using it to pivot further attacks against other devices within the screened network segment.
DNS rebinding attacks have been known about since at least 2007 with a research paper and CVE vulnerability both published in that year. Instances of DNS rebinding attacks remained relatively low until the growth of cheap mass-market consumer “Internet of Things” devices began to proliferate between 2016 and 2018, when the attack saw a large-scale resurgence in popularity. Many of these “IoT” devices were produced to a low cost point and protected with only rudimentary authentication, leaving them vulnerable to compromise.
Its possible for organisations to be complacent and believe that only consumer networks are weakly protected by technical controls, and that corporate services and devices are better hardened against simple attacks. However, organisations continue to deploy services such as Redis, MongoDB, and memcache on local networks without authentication – these services are screened from direct access by attackers based on the public internet but may be liable to compromise via DNS rebinding attacks.
The first wave of IoT attack campaigns have been quite successful attacking only publicly exposed consumer-tier devices, but increased competition for this low-hanging fruit may be expected to drive botnet operators to seek out improved techniques for reaching valuable targets on private corporate and home networks.
Home networks are typically restricted to a small address space such as /24 range, making device enumeration simple for attackers. Enterprise networks can be substantially larger, so being able to find valid target IP addresses within the address space can be more challenging for attackers. Without implementing more sophisticated techniques, attackers may be faced with scanning up to 18 million IPv4 addresses in a large RFC1918 network, which is going to present challenges. However, new techniques such as calls to WebRTC’s getStats may allow attackers to trigger browsers to make requests from JavaScript to STUN servers in order to return in-use local IP addresses much more efficiently than brute-force scanning and enumeration.
So what techniques can an enterprise use to mitigate the potential for DNS rebinding attacks?
It is possible to configure your clients so that all DNS lookups are “proxied” through a local DNS server that is operating in “resolver” mode – that is the DNS server will accept DNS lookups for all domains, and resolve the queries itself via recursive lookups if it cannot resolve the query immediately via cache – and blocking direct DNS lookup by users to external DNS hosts. The DNS server can typically be configured to prevent domain names resolved via forwarding to external servers from resolving to internal IP addresses.
If not able to restrict your enterprise DNS configuration to operate in the above manner – i.e. direct DNS resolution from clients must be permitted, then an alternative method is to configure a packet-inspection firewall at the network boundary to reject inbound DNS Responses from external servers that specify a low TTL or IP addresses that are non- routable addresses (RFC 1918, Address Allocation for Private Internets), or routable address space used internally.
An additional measure that can be applied in addition to the above is to try and reduce the issue with malicious JavaScript executing in the first place, by preventing access to known-bad websites, using a web filtering proxy for outbound traffic from your user’s browsers, and preventing any other outbound HTTP traffic that does not originate from the proxy. There are various limitations with this technique, such as challenges with HTTPS traffic and how to effectively know which target sites, domains and webpages from the billions on the internet are known or suspected malicious, but it can nevertheless be effective as an additional measure within a “defence in depth” strategy.
All local services on the private network should make use of strong authentication and CSRF protection measures. Just because services are not exposed directly on the public internet should be taken as reason to not provide adequate authentication and access control to them.
A strong mitigation strategy against DNS Rebinding attacks is to implement the validation of HOST headers on all exposed web services:
GET / HTTP/1.1
Host: www.example.com
If a webserver that receives an HTTP request in a DNS rebinding attack validates that the host header is both present in the request and matches the host service being requested then requests made by the compromised browser will fail, because the target service that the browser believes it is connecting to (based on the malicious rebound DNS lookup response) and hence provided in the Host header value made to the server will not match the actual service being connected to.
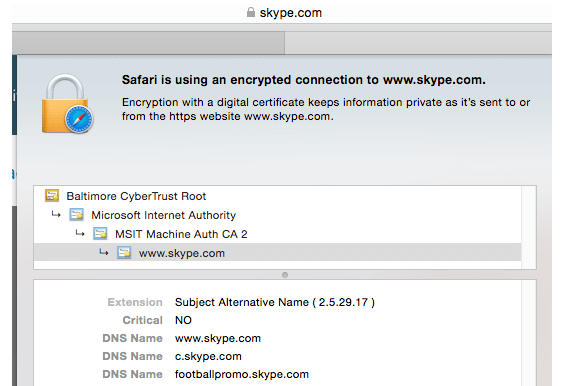
HTTPS SSL/TLS can also help mitigate DNS Rebinding attacks – not because of the encryption it provides – but because of SSL certificate validation, in that the site that the user’s browser believes it is connecting to will not match the site listed in the SSL certificate’s “Common Name (CN)” or extended “Subject Alternative Name (SAN)” fields.
AppCheck help you with providing assurance in your entire organisation’s security footprint. AppCheck performs comprehensive checks for a massive range of web application vulnerabilities from first principle to detect vulnerabilities in in-house application code. AppCheck also draws on checks for known infrastructure vulnerabilities in vendor devices and code from a large database of known and published CVEs. The AppCheck Vulnerability Analysis Engine provides detailed rationale behind each finding including a custom narrative to explain the detection methodology, verbose technical detail and proof of concept evidence through safe exploitation.
As always, if you require any more information on this topic or want to see what unexpected vulnerabilities AppCheck can pick up in your website and applications then please get in contact with us: info@localhost