Vulnerabilities relating to file uploads are most commonly described as occurring when remote users are able to upload files to a web server that fails to perform appropriate checks on the provided file’s attributes (such as its type, content, or size), leading to issues such as the ability to upload malware or other dangerous file types. However, both the transfer process itself, as well as the processes of file storage and subsequent file-serving or file retrieval can also lead to additional issues that may not always be considered: transfers occurring across unencrypted connections can allow attackers to intercept sensitive files, for example, and if incorrect permissions are used for stored files, then attackers may be able to retrieve confidential files which other users have uploaded. In the most serious cases, file upload vulnerabilities can permit attackers to perform remote code execution including the execution of arbitrary, attacker-provided code directly on the server, and potentially leading to complete host compromise.
In this blog post, we take a deeper than usual dive into the topic of file upload vulnerabilities: we look at the mechanisms that operate underneath the hood when uploading and storing files on a webserver, and at how these can be exploited by attackers if developers fail to adequately ensure their safe implementation and operation.
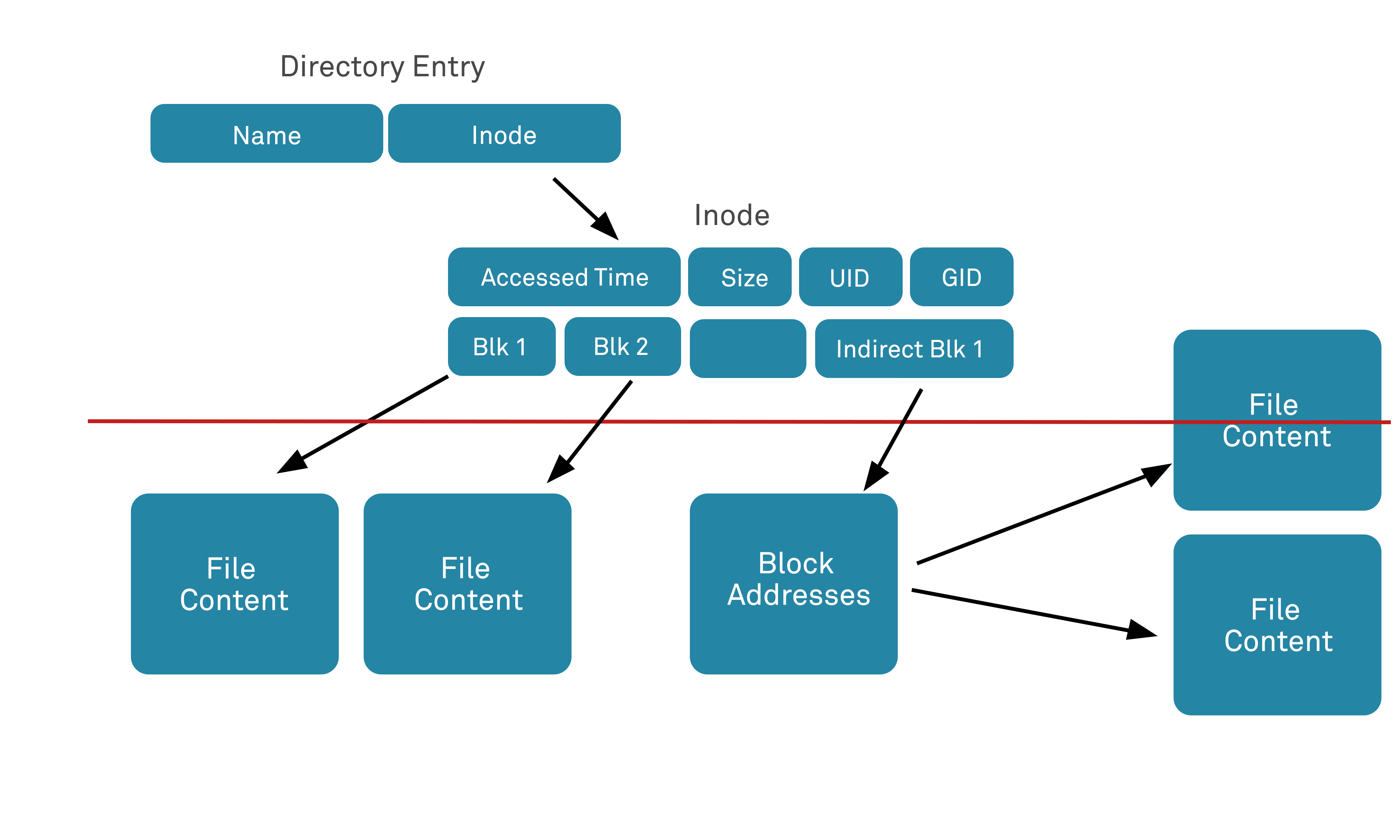
The question of what files are isn’t intended to be either flippant or rhetorical, even if it first might appear so. We all know informally what computer files are, of course, and deal with them every day. However, it can be useful to dig a little deeper into exactly how files are constructed and stored, in order to better understand potential security issues that may arise during file uploading.
Under most web server operating systems, files are computer records that exist as discrete bundles of data that are addressable by name – they are organized and addressed by fixed start and end point locations on the underlying storage medium. The internal structure of an individual file doesn’t follow a globally standardized file structure but rather is dependent upon the specification outlined for a given file’s file type. It is common for files to have a filename extension that identifies the file format that the file is based on, but files typically also contain a few bytes of metadata at the start – data describing the file and its properties – depending upon the file format.
Files also typically have an associated set of access permissions and attributes that are set at the operating system level: these and other attributes vary per operating system, but for the simple purposes of this article it is worth noting that these attributes are evaluated at the time of creation, modification and access and determines the level of access granted to either a user or a group of users.
File uploading refers to transmitting data from one computer system to another through means of a network. It can exist in variants such as client-to-client (peer to peer), and server-to-server, but for the purposes of this article we’re going to focus on the client-to-server variant that perhaps also is the form that most commonly springs to mind.
Common methods of uploading in the past have used protocols such as FTP, SFTP, FTPS, TFTP, RCP SCP, PeSIT, AS2/3/4 and even telnet, but HTTP & HTTPS are by far the most common form now seen – the same protocol used to request and transfer the standard HTML and other content between clients and web servers.
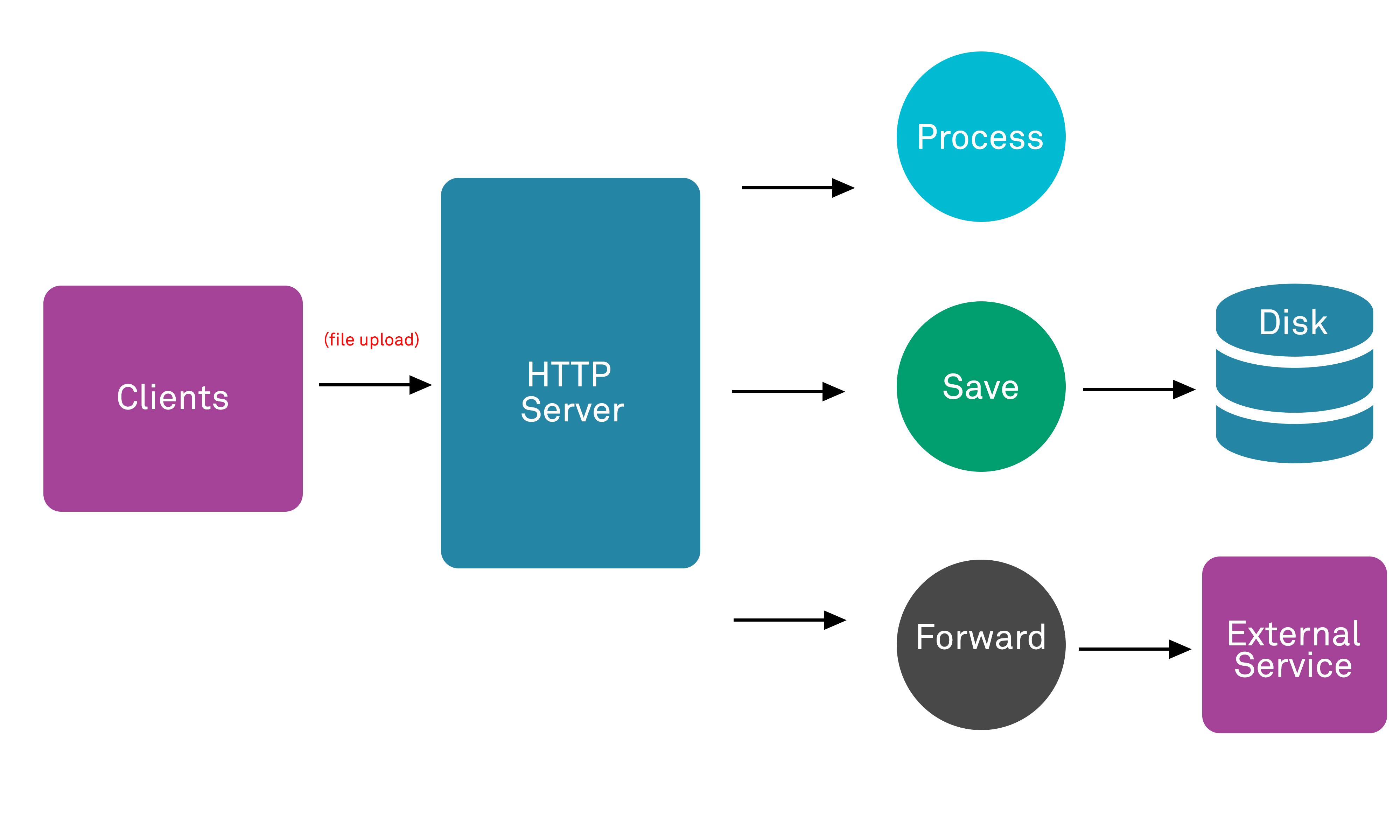
Once the file is received it may be processed, persisted to disk, or forwarded to an external service – although storage to disk is the most common use case.
Under the original HTTP protocol specification, there no specific provision or support was included for uploading files from a client to a server, but in 1995 RFC1867 “Form-based File Upload in HTML” was published, adding this functionality. Under this mechanism, a client can initiate a connection to the server and then use either the POST HTTP verb (method) to transfer the file to the server (the PUT and PATCH methods also allow file upload – sort of! – but we won’t explicitly cover them here and they are not widely used).
The file to be uploaded by the client is included in the body of the request sent to the server, in much the same way as any other (text-based) request content. The upload of a file is indicated by setting the Content-Type HTTP header to multipart/form-data, along with a “boundary” parameter if uploading multiple files in one request:
Content-Type: multipart/form-data; boundary=———Separator
Content-Length: 465
Since the RFC1867 and the multi-part file upload specification, various methods of file upload have appeared. One notable attempt at improving on the original HTTP protocol was the Web Distributed and Authoring and Versions (WebDAV) extension, allowing clients to edit remote content on a server. As part of this extension, it offered file upload capabilities. Whilst it is rarely seen on servers today, it is still vulnerable to most of the issues we will discuss later in this article.
On modern web applications you can expect to see asynchronous uploads sending files as encoded strings embedded within a larger transport medium such as a REST or SOAP API. File uploads have even progressed as far as streamed files over a web socket.
Files received by the web server may be transiently processed and no permanent record kept, but it is more common to see applications in which the data is written to persistent storage on devices such as hard disks. In order to understand the risks posed by file uploads, it is also necessary to understand how files are stored on the web server once they are received.
In general, files are stored in one of three ways:
There are also some hybrid storage options that incorporate multiple storage types within one umbrella mechanism, such as MSSQL’s “filestream” feature that writes files sent to the database to filesystems rather than within the database, and the ability of S3 buckets to be mounted as filesystem-addressable directories. A given file upload solution may even make use of multiple storage options within a given application, or may store metadata (data about the stored files) within a separate storage backend to the location that the files themselves are stored:

The majority of file upload vulnerabilities historically have related to exploits against flaws in implementing filesystem-based storage, however vulnerabilities are also possible in applications that use database storage or cloud storage buckets for received uploads. We will cover each of these use cases slightly later in this article.
In some web applications, uploaded files are provided by individuals on a confidential basis and for the organisation that operates the file server only: an example might be a web application that receives scans of passports as part of a proof of identity check. However, in many instances, the file upload functionality is provided as part of an application whereby the uploaded files are intended to be published and shared with others: examples might include a social media platform where a user wishes to publish and share photographs of their holiday.
In this second case, the server needs a mechanism to serve the files back to requesting users once received. In the case of static resources (non-executable files), such as images that have been uploaded, a web server will just send the file’s contents to the client in an HTTP response.
However, if the web server determines by the file extension or MIME type of an uploaded file that it is executable – such as a PHP file – and the server is configured to execute files of this type, it could present some confusion for the server and execute the script locally and send the resulting output the client in an HTTP response. This is just one example of a possible file upload vulnerability and as we shall see shortly, attackers are sometimes able to leverage this difference in file handling in order to trigger inappropriate server behaviour.
File upload vulnerabilities may not be as immediately familiar to audiences as vulnerabilities such as Cross-Site Scripting (XSS) or SQL injection (SQLi), however they can be extremely serious. In the more severe cases some file upload vulnerabilities can be leveraged to upload an attacker-provided script or executable file, and then execute it on the server. These executables can contain code such as web-shells which can permit remote users to run arbitrary commands on the server’s operating system: potentially they could then browse the server’s filesystem, exfiltrate data, modify records, wipe the server, or launch further attacks at other systems within the organisation. However, some file upload vulnerabilities could be as simple as exploitation of the lack of a limit on the size of an uploaded file, resulting in malicious parties filling up a web server’s disk space. Whilst it may be considered less severe it can be equally as disruptive for an organisation.
Now that we have seen how file upload, storage and retrieval via HTTP works, its time to consider how exactly attackers are able to exploit these mechanisms in order to compromise server security.
The standard that added file upload functionality to the HTTP protocol – RFC1867, as we saw above – lists only two potential security concerns relating to the file upload mechanism – the use of client-provided filenames; and the lack of a built-in encryption mechanism – before finishing with the cautionary note that “once the file is uploaded, it is up to the receiver to process and store the file appropriately”. No further guidance provided as to what “appropriately” means in this context, or what potential risks may be involved.
We shall cover the risks outlined in the RFC document, as well as many others. These can be broken down or classified in a couple of different ways:
A vulnerability with file upload services that is not often considered is the possibility of Denial of Service (DoS), in which file uploads can exhaust the resources of the server, causing it to become unavailable to serve legitimate clients.
One form that this can take is the exhaustion of file storage space by an attacker uploading a series of extremely large files, if the server fails to suitably restrict the filesize of uploaded files. This is a relatively uncommon form of deliberate attack since it is a particularly inefficient form of DoS attack compared to other variants, requiring significant resources at the attacking client’s end and taking a long time to exhaust storage space typically. However, if the server in question attempts to buffer the entire file transfer in memory or uses a smaller temporary filesystem to store the file while it is being transferred, this can be exhausted much more quickly than permanent diskspace. If diskspace is exhausted, then clients may be unable to upload further files, and in some instances the web server itself may stop responding entirely to any client requests at all.
A number of variants exist that revolve around this style of attack. It may be possible for a malicious attacker to just simply upload the same file repeatedly, bypassing any size restrictions on the uploaded file, and achieving the same goal of consuming disk space on a target server. Similarity on Unix based filesystem using inodes to store information about files, directories, and devices. One way to make the disk unusable is to consume all of the free inodes on a disk so no new files can be created. This can be trivially achieved by an attacker simply by repeatedly uploading the same small file over and over.
Further denial of service attacks can happen due to the lack of restrictions on the uploaded file types. Uploading a file on a Windows server that uses a reserved (forbidden) names such as CON, PRN, AUX, NUL, COM1 etc, may lead to denial of service if the application keeps the name and tries to save it with another extension (detecting it wrongly as an existing file). Again, on Windows file systems and IIS webservers, uploading a web.config configuration file can overwrite the web application’s configuration causing the server to halt operation altogether.
In file upload applications, a server will often preserve the name of the uploaded file provided by the client, or use a filename provided by a text input sent by the client and use this filename to save the file to server storage. In cases where the server operates in this manner and fails to validate the provided filename, then an attacker can sometimes inject special characters into the filename such as directory traversal indicators (e.g., “../”). If the server contains code to concatenate this input filename with a local path, in order to produce the destination filepath to write the file to, then it may be vulnerable to a directory traversal attack.
In a directory traversal attack (otherwise known as filepath manipulation) an attacker can use these indicators to cause the server to write the file to a location other than planned, typically outside of the Webroot. If the attacker can control the target filepath in this manner, then they can potentially cause the server to write the uploaded file in a location other than the server intended, overwriting critical files on the server.
For example:
https://example.com/upload-file.jsp?filename=../../../etc/passwd
As we have already touched on in the previous section, uploading a web server’s configuration file can result in critical files being overwritten and possible denial of service taking place. This issue can be compounded if a path traversal attack exists allowing attackers to further overwrite operating system configurations and abuse a target system. However, both Apache and IIS web server’s use their own version of a web configuration file to provide a way to make configuration changes on a per directory bases, or in the case of IIS, application wide changes. The configured settings offer a wide variety of functionality but most notably control URL re-write rules, dictate how file types are processed, and re-enable extensions. This means that if an attacker discovers a means of overwriting these key files, its entirely possible for them to also upload a web shell and take over the server.
As we saw above in our explanation of how files were handled by a web server, a web server that serves files needs to make a decision as to whether a requested file should be served to the requesting client as requested resource (images, for example), or else executed locally and then the content generated as output sent to the requesting client as text in an HTTP response (as with PHP files for example). It does this by determining the filetype via some combination typically of the filename/extension, or the file’s metadata or MIME type.
If an attacker is able to upload files that a server recognises as executable files or files that should be sent to an interpreter for process (for example PHP file with a “.php” file extension) and then provides a path to the client to retrieve the file, then a serious class of vulnerability may occur in which a client can execute arbitrary code on the server. A malicious client can exploit this vulnerability by uploading an executable file and then executing it by requesting the server returns it.
One of the most serious forms of this vulnerability is if the attacker can upload a file that functions as a web shell, which permits them to execute arbitrary commands and can effectively grant them full control over the server if the server process executes with insufficiently limited local permissions.
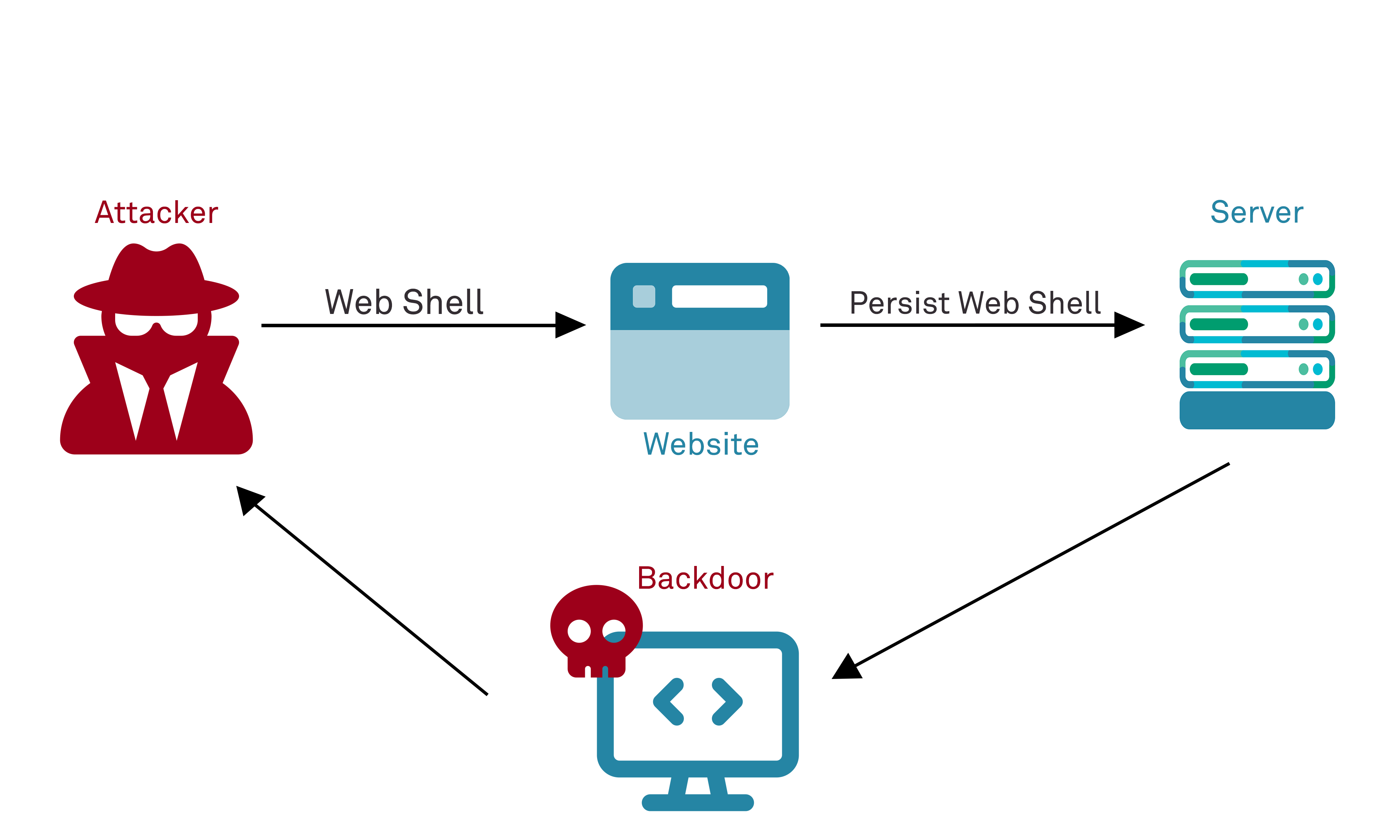
An issue that is often not considered is the situation where a file is uploaded that is seemingly benign in and of itself but requires specific third-party libraries that are referenced and loaded dynamically by the server. If a vulnerability exists in the third-party library, then executing the file may introduce a vulnerability even though the code in the uploaded file is itself benign and without vulnerability. A common example of this in recent years has been the ImageMagick vulnerability (CVE-2016-3714). Originally detected in 2016 (and with subsequent flaws resurfacing in 2020) the commonly used library was found to contain multiple serious vulnerabilities, including those that enabled command injection and arbitrary file read/write by attackers.
In cases where a server supports the upload of binary or executable files in particular, it is potentially possible for an attacker to upload malware onto the webserver. Even where no additional vulnerability exists that permits the attacker to then cause the malware to execute within the server’s local context, the file that is uploaded may – depending on the application – be published and made available to other users, making the server an inadvertent accomplice in spreading the malware.
Since users may place trust in the service in question, they may not make the mental distinction between content that is sources from the host server officially and third-party (other user) content that has been uploaded to it for distribution, making them less cautious of the files they download from it and more likely to fall victim to any malware that is distributed in this way.
In some cases, a server may inadvertently disclose information about files that have been uploaded by other users. This can occur if, for example, a server uses client-provided filenames for uploaded filenames and performs a check for newly requested uploads if the provided filename already exists on disk, in order to prevent duplication or overwriting of existing files.
The issue with this approach is that in some cases error messages warning of a duplicate filename being provided would provide information on which filenames were already present on the system. In circumstances where the file is, for example, named after the requesting user, then the server can disclose what users have made use of that file upload function. In the case of sensitive services or those promising anonymity to clients, an attacker can use this to enumerate a list of users of the service via trial and error in uploaded filenames and the subsequent duplicate-file error messages seen.
One of the main use cases for a file upload existing on a web application is typically to allow users to control their own content. In the typical case of Internet forums or message boards, where rich text editing is common place and the functionality of uploading files is also possible, a number of client side attacks can occur. Due to poor validation on the content of the uploaded file, malicious content such as embedded HTML, can be used to carry out a stored cross-site scripting attack. This can be leveraged to attack any number of different users visiting the same content to where the file was uploaded.
Further client-side attacks can occur when users are allowed to upload their own content and the application server fails to validate the content sufficiently. An attack known as Cross-Site Content Hijacking which leverages the lack of validation on the content of the uploaded file can be used to bypass cross-site request protection on a target site. Even if the file upload functionality properly validates the extension by using a white-list method and restricts the allowed file types to a few non-dangerous extensions such as .jpg, .png and .txt, this attack is still possible. A typical attack scenario for Cross-Site Content Hijacking involves an attacker uploading a malicious Flash, Silverlight or PDF to a target server with a file extension permitted by the file upload. They then trick a user into visiting their own website which embeds the contents of the uploaded file, which when executed is done so in the domain of the target server. Whilst the browser prevents the embedded content from executing JavaScript in the context of the target website, it is still possible for the embedded file to make requests within the domain of the target server, thereby bypassing any cross-site request protection in place.
File upload applications can frequently suffer from access control failures. There are many forms that this can take but most variants involve the use of a common or shared Webroot directory that all files uploaded are stored within, with no access control checks on the file retrieval. The application may respond to a given user with a message such as “Your file has been saved and is available at https://www.example.com/files/12345”.
If the filename is guessable or predictable (a simple incrementing count used as the file ID in this instance) and the system fails to check that a requesting user is the owner of the file in question, then other files can be accessed simply by manually entering a different path in the URL, such as “/files/12346” or “/files/11111”.
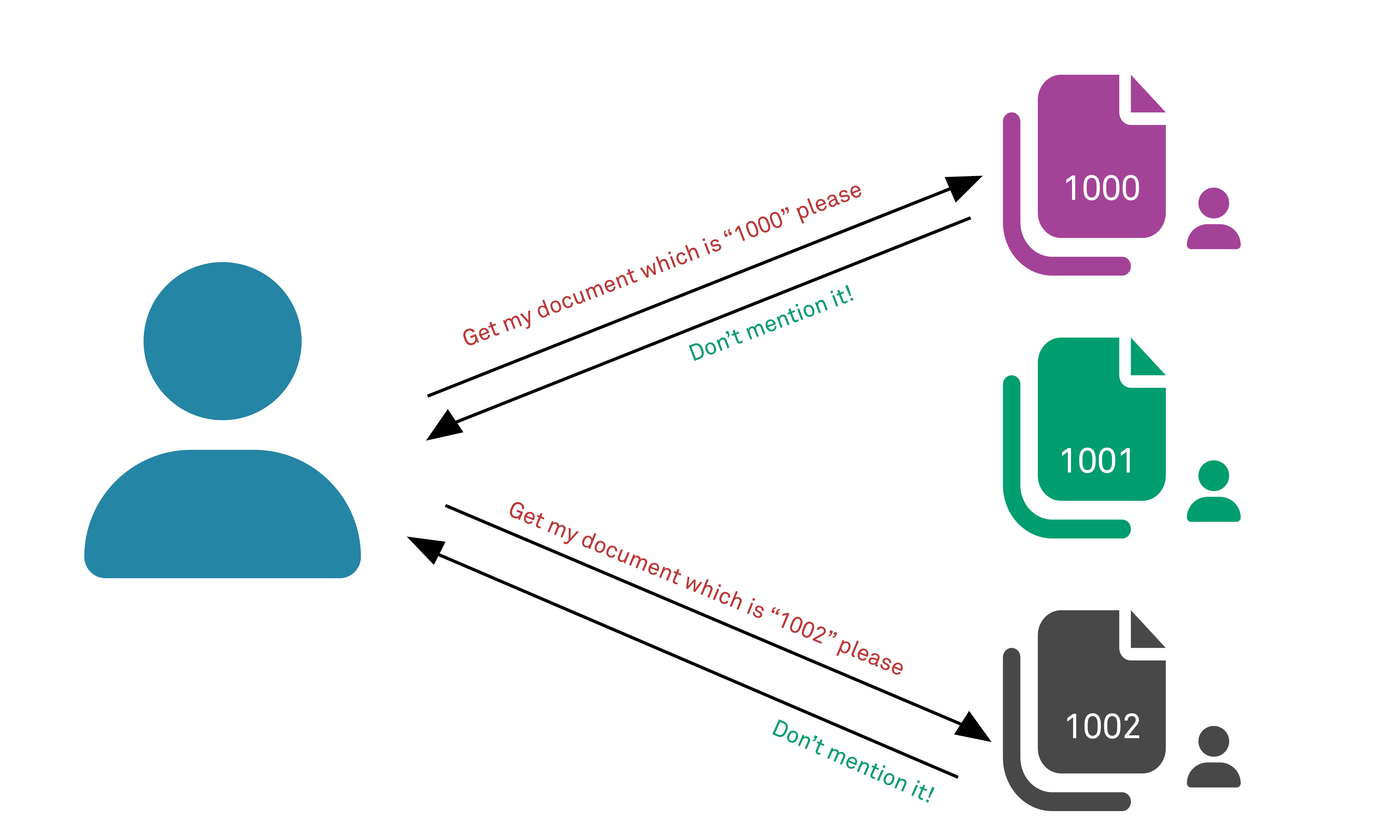
This can be variously referred to depending on the source as Forced Browsing, Insecure Direct Object Reference (IDOR), or Authorization Bypass Through User-Controlled Key.
An emergent risk with the growing popularity of cloud storage such as Amazon’s S3 for backend file storage has led to new security issues. Most commonly, a cloud storage bucket may be misconfigured such that it is world readable with indexing enabled. If configured in such a state, it is possible for the attacker to index the contents of the affected bucket and download any of the files within it. This may lead to the leak of sensitive or confidential information if the files that are uploaded to it are not intended to be shared publicly. If sensitive data files are uploaded and stored within the Bucket, this flaw could present a significant security risk.
One final consideration for file upload services is the possibility of an organisation’s fileserver being used to host and distribute illegal content. It is a very tough problem for computers to be able to determine whether content – especially binary (compiled) files – contain any material or content that may constitute illegal or objectionable content such as hate material or pirated software.
In general, many file upload vulnerabilities can be avoided by using an established framework for pre-processing file uploads rather than attempting to write your own validation mechanisms. This isn’t a universal panacea – and frameworks can themselves sometimes contain vulnerabilities – but in general it is more common for those maintaining frameworks for a specific function to be more aware of the risks presented by that function. A distributed user base and greater product visibility can also, in general, lead to quicker detection of any security vulnerabilities, and updates to fix them can be distributed to all users of the software. In practice, however, this is not always the case, and knowledge of how to avoid file upload vulnerabilities is worthwhile for most development teams.
In general, certain vulnerabilities can be avoided by restricting uploaded file types to a “known good” whitelist. This may not be possible in all applications, but in the case of photo ID upload, for example, a set of common image formats could be whitelisted, and all other filetypes denied upload. Ultimately the file types allowed to be uploaded should be restricted to only those that are necessary for business functionality.
It is safest to perform multiple checks of the file type and to ensure that a file passes all checks, to prevent attempted bypass of the filetype restrictions. This can include checks on the provided filename to ensure that the file extension is from a permitted list, as well as checking the file dynamically for its MIME type. One solution would be to use a MIME type detection library or function (such as PHP’s mime_content_type) to detect the MIME type of the file uploaded and rejecting the file upload if the file extension provided does not match the detected MIME type.
Where there is a requirement for uploaded files to be re-downloaded by the user, the “Content-Disposition: Attachment” and “X-Content-Type-Options: nosniff” HTTP headers should be set in the response, this will heavily mitigate the risk of possible client-side attacks. It is recommended that this practice be performed for all the files that users need to download in all the modules that deal with a file download.
It is sensible to set a maximum file size and name length for uploaded files, in order to prevent diskspace exhaustion, however inefficient an attempted DoS attack using this method may be. Such checks can be implemented client-side to warn legitimate clients if their file is too large before they begin upload, but client-side checks for security issues should always be duplicated server side, since they can be bypassed otherwise by malicious attackers.
If possible, uploaded files should be scanned for malicious content using an antivirus tool or similar, either deployed locally on the server or accessed via API: VirusTotal is one common solution accessible via API that is able to perform malware detection and static analysis of uploaded files.
It is generally good practice for any uploaded file to be isolated and segregated away from the contents of the web server outside of web root, this ensures that any malicious content is not further distributed or re-downloaded by other user’s of the web application.
A potential solution for many vulnerabilities relating to upload of files onto a filesystem is to store the files within a database. Although not always suitable for larger files, and not universally supported as a solution by all database administrators, there are some benefits to such an approach, including benefiting from built-in access control restrictions to the files, as with any other record type.
If an application is going to serve or make available for download files that have been uploaded to it, then in most cases access control to requested files will need to be considered. Most commonly this means ensuring not only that a requesting user is authenticated per se, but that they have subject access rights to the specific file being requested.
Additional context checks may involve making sure that the file being served from the web server is an expected one given all other contexts: is it of an expected type and size for example (and not some other file from elsewhere on the filesystem). One commonly recommended solution is to ensure that all files are referred to not by filename but by an abstracted index ID only, with that index ID mapping to a file location within a database record, for example. In this way, only files that have specifically been uploaded and indexed within the database can be retrieved and there is no way to access arbitrary files from elsewhere on the filesystem for download.
A “best practice” in many areas of security is to ensure that code is executed using the lowest privileges that are required to accomplish the necessary task and – if possible – creating isolated accounts with limited privileges that are only used for that single task. The reasoning is that in the event of a vulnerability being discovered, the impact will be somewhat mitigated, since a successful attack will not immediately give the attacker access to the entirety of the software or its environment. For file upload functions in particular, this may mean ensuring that the file upload service has specific access only to a single filepath and no access to any other system path or directory. Although some implementations have been subject to bypass, this can include running a file upload service in a semi-isolated pseudo-environment such as a chroot jail, sandbox or more recently container.
Several vulnerabilities that we outlined above, including IDOR vulnerabilities, can be somewhat mitigated as part of a defence in depth strategy by ensuring that filenames associated with uploaded files are discarded entirely. In their place, the server generates a new, unique filename for the uploaded file instead of using the user-supplied filename, so that no external input is used. Where this is done – and especially if the filename is to be used in file retrieval operations rather than the recommended “indexing” approach outlined above – then it is important that the files are not named predictably. What this means is that the filenames should not be guessable by an attacker based either upon the name generated for a file they themselves uploaded, nor based on knowledge they may have about other clients.
For example, sequential filenames (e.g., 1234.jpg) should not be used, since an attacker can simply increment (or decrement) the filename to attempt to access other records. Similarly, the filenames should ideally be random (or apparently random) rather than based upon user input or attributes in a guessable or determinable way. For example, an attacker who sees that his file has been generated using his own username may attempt to access another user’s file upload by guessing the filename “johnsmith.jpg”.
Metadata, or the data relating to a file, should be redacted, if possible, to prevent inadvertent information disclosure relating either to the user that uploaded the file or that exposes a property of the file itself that may be useful to attackers.
One very common example is to not display the local filepath to the user in any file upload confirmation dialogue, since this discloses information about the filesystem that could be leveraged in, for example, a filepath manipulation attack. However, a less commonly considered variant might be to consider stripping all metadata from the file itself using a metadata removal or scrubbing tool– information such as EXIF metadata within images can contain ancillary tags such as GPS location indicators that may reveal the precise GPS location of users who uploaded images for example.
Lastly, it is advisable to confirm that an application is free of file upload vulnerabilities using a dynamic web application scan. Since production applications have specific environmental configuration that may not be found in other, pre-production instances, it is essential to check the production instance itself to screen it for such vulnerabilities.
AppCheck helps you with providing assurance in your entire organisation’s security footprint. AppCheck performs comprehensive checks for a massive range of web application vulnerabilities – including file upload vulnerabilities – from first principle to detect vulnerabilities in in-house application code.
The AppCheck web application vulnerability scanner has a full native understanding of web application logic, including Single Page Applications (SPAs), and renders and evaluates them in the exact same way as a user web browser does.
The AppCheck Vulnerability Analysis Engine provides detailed rationale behind each finding including a custom narrative to explain the detection methodology, verbose technical detail, and proof of concept evidence through safe exploitation.
AppCheck is a software security vendor based in the UK, offering a leading security scanning platform that automates the discovery of security flaws within organisations websites, applications, network, and cloud infrastructure. AppCheck are authorized by the Common Vulnerabilities and Exposures (CVE) Program as a CVE Numbering Authority (CNA).
As always, if you require any more information on this topic or want to see what unexpected vulnerabilities AppCheck can pick up in your website and applications then please get in contact with us: info@localhost