File path manipulation vulnerabilities occur when user supplied input is received directly from remote clients is used to either partially or wholly construct a local filepath that is used on an application to address a local resource that is to be accessed. If an application fails to handle this received data safely, then a remotely positioned attacker can potentially submit data to the application that causes it to access a resource not anticipated by the application developer. The resource may contain (and return to the attacker) sensitive information, impacting data confidentiality. Alternatively, the resource may contain (and permit the attacker to overwrite or delete) critical data, impacting data integrity and potentially system availability.
In this blog post, we look at how filepath manipulation can occur at a technical level, at how attackers may seek to exploit such vulnerabilities, and at how developers and system administrators within an organisation can best guard against falling victim to such exploits.
Data is stored on storage media such as hard disk drives in the form of fixed-size blocks, addressed using inodes (Linux) or similar, containing metadata about the file’s size and location. However, almost all computer systems offer an intuitive, logical, and addressable hierarchical and recursive file system layer to users and applications.
This hierarchical filesystem makes use of multiple nested directories, each of which may contain either files or further sub-directories. Some of these directories may be “built-in” and present from time of operating system installation, whilst others may be created either by users themselves, or by applications and utilities during installation or usage.
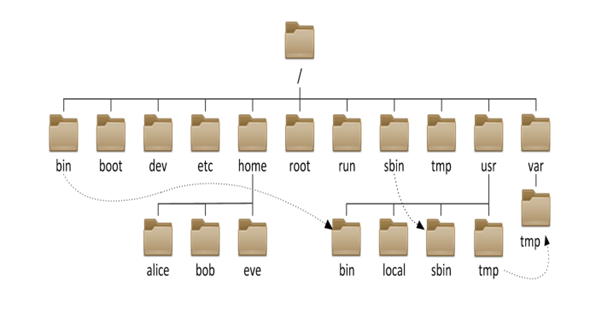
A filepath is a string of characters that is used to represent a location in this hierarchical directory structure in a simple, string format. It is composed by following the directory tree hierarchy, concatenating (appending) each “level” in order to build up an address to the file. Each level in the hierarchy is separated by a delimiting character that represents descending into the next sub-directory. This delimiting character is most commonly the slash (“/”) or backslash (“”) character.
Filepaths allow specific files or directories to be unambiguously addressed during filesystem operations within application code.
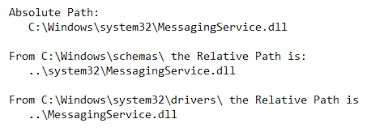
Importantly, as we shall see shortly, a filepath may be either absolute or relative. An absolute or full path points to the same location in a file system, regardless of the current working directory. To do that, it includes the full path descending from the base (root) directory explicitly and in full. By contrast, a relative path starts from some given working directory, and provides instructions on how to navigate to the target, potentially traversing up one “branch” of the filesystem hierarchy and down another. A filename can be considered as a relative path based at the current working directory.
Often, a web application will need to serve a file or resource to a requesting client. Whilst most web applications will generate a resource dynamically on-demand using a combination of static templates and variables drawn from a database, for example, there are some instances were pre-generated static media or resources that exist on disk need to be served to requesting clients.
One way of doing this is to allow the client to specify the name of the file that they wish to be served, either by explicitly entering the filename, or by clicking on an entry from a pre-generated list on a webpage – either way the file to be returned is communicated to the webserver as an HTTP parameter in the URL. A naïve example might be a request such as:
http://example.com/get-files.jsp?file=report-DaveRogers.pdf
where the portion in bold represents the filename that is to be returned.
So, what can go wrong? In filepath manipulation (also known as directory traversal) it is possible for an attacker to craft a value for the filename parameter such that, rather than returning a file from a permitted or expected list, they are able to use special characters within the filename parameter in the URL in order to access unexpected and potentially arbitrary files in a way that was not anticipated by the application developer.
In the simplest, and potentially overlooked form, filepath manipulation may consist of an attacker simply recognising that the resource being returned is represented by a parameter in the URL and simply amending the requested filename to another one.
In a very simple example, if an application were to store files relating to all users in a single undifferentiated directory location with identical access permissions and no further access control restrictions, then in an attack that can variously be described as filepath manipulation, as access control failure, or a file inclusion vulnerability, an attacker can simply modify the filename to a different one and return a file that relates to another user other than themselves.
For example, if they can access their report using the following URL:
http://example.com/get-files.jsp?file=report-DaveRogers.pdf
then they may discover that they can instead access another user’s records by altering the filename parameter:
http://example.com/get-files.jsp?file=report-JeffSmith.pdf
However, when we talk about filepath manipulation, then most commonly we are referring to a more specialised and advanced form in which the filepath is modified in such a way as to permit navigation to a different directory in the filesystem’s hierarchy – as opposed to simply returning an unexpected record from the same directory, as in the basic form. In the next section we will take a look at how this occurs exactly.
Many file operations performed by a web application are intended to take place within a restricted directory, typically the “webroot” – a directory that is specifically laid aside for the serving of files by the web application. This folder is often named either public_html, htdocs, www, or wwwroot depending on the web server in use.
A website can keep files outside of the public document root but such files are not by design intended to be accessed via URL – they can only be accessed by the web application through server-side code, via their filesystem address that we outlined above. The key elements for navigation to a file are the special elements “..” used to navigate up one directory in the hierarchy and “/” separator used to descend one directory level.
If an attacker is able to submit these characters within the filename parameter in the request URL, then they can escape outside of the restricted location to access files or directories that are elsewhere on the system in a relative path traversal attack. Similarly, if an attacker is able to submit a full absolute pathname in place of the filename parameter in the URL (such as “/usr/local/bin”) then they can perform an absolute path traversal attack.
For example:
https://example.com/get-files.jsp?file=../../../etc/passwd
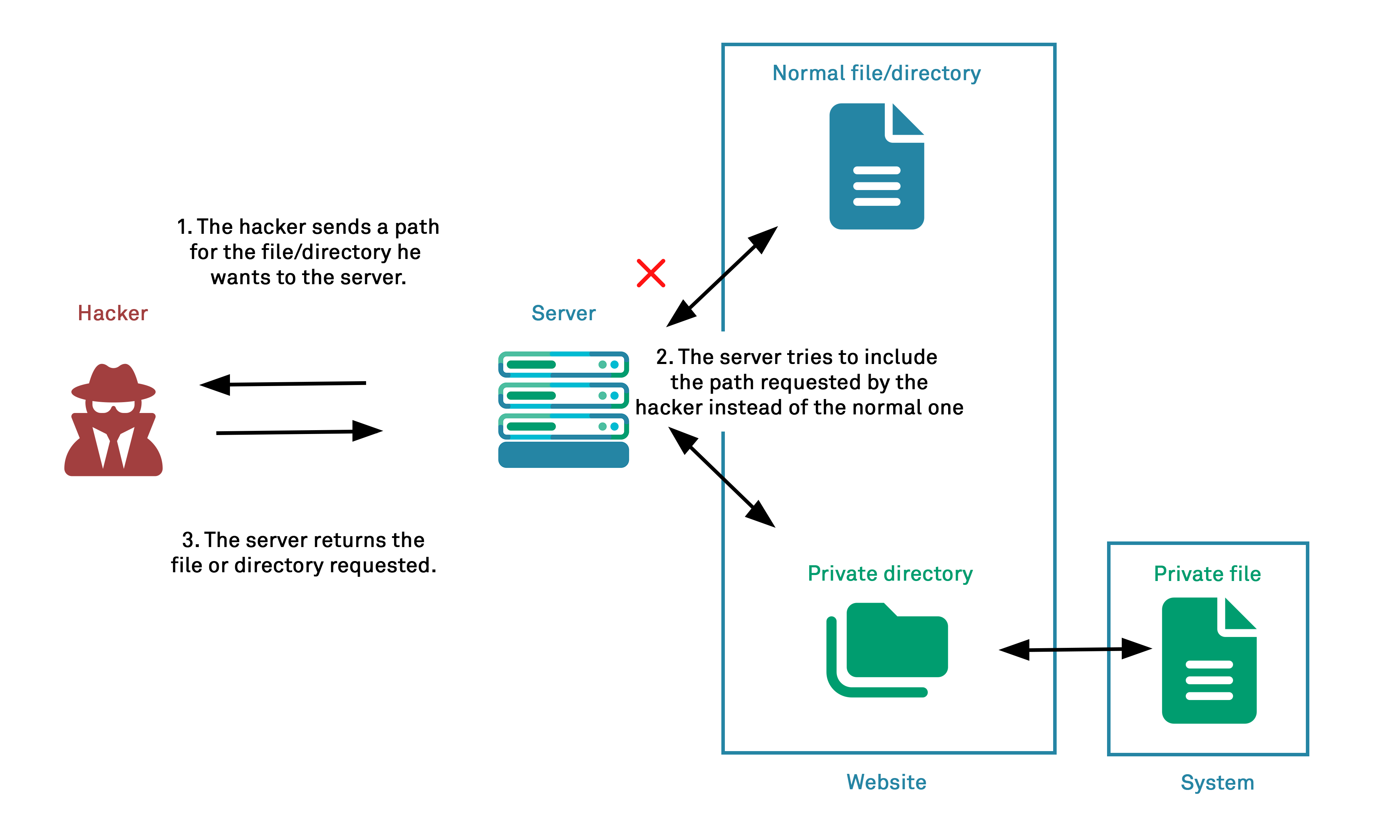
If an attacker is able to return arbitrary files from across the filesystem, then there are confidentiality concerns at various levels:
Data – an attacker may be able to access other user’s records from within the application, in addition to their own, leading to data breach of potentially personal and sensitive information.
Application / Service – an attacker may be able to return configuration files from the service itself, potentially containing information such as database passwords used by the application for database access and that the attacker can use to pivot an attack against other systems.
System – sensitive operation system files such as /etc/passwd or /etc/shadow contain username lists and masked passwords, potentially allowing complete machine/host compromise.
In some cases, the filename parameter may be getting passed in not as the name of a file to be returned, but as the filename to use in saving or writing some user-submitted data or files to disk, in a file upload functionality or similar. If an attacker can insert a full or relative filepath instead of a filename, then they can potentially get the application itself to inadvertently act in a harmful manner by, for example, overwriting critical system files, causing total system outage and data loss.
Ideally, application functionality should be designed in such a way that user-controllable data does not need to be returned in the URL as a parameter in order for the application to know which local resource on the server is to be accessed. This can be achieved in a number of ways, but one best practice solution is to instead generate a list internally within the application of permitted or whitelisted files, and then map each to a unique key that does not need to contain filepath characters, such as an index number. Also known as “enforcement by conversion”, the application then looks up the received ID and accesses the file name that this maps to. Because the index number is from a simple character set (e.g. [0-9] only), it can trivially be validated for correctness when received from the user. The internal data structure might look something like the below:
[
{
id: "1",
value: "../reports/1.pdf"
},
{
id: "2",
value: "../reports/2.pdf"
},
]
Another solution is to ensure that all operations that address the local filesystem do so using a well-reviewed and vetted library or framework that does not allow this weakness to occur or provides constructs that make this weakness less likely to occur. Third-party libraries and frameworks are not themselves entirely immune from security vulnerabilities, so their usage is not an absolute panacea, but alongside other measures it can assist as part of a defense in depth strategy. Typically, the broader the install base of a given framework, the more scrutiny it will have come under and the more likely it is to have been tested in various production instances for various security weaknesses. A third-party framework or library will generally have a public changelog that can be accessed in order to assess its maintainers’ ongoing commitment to the project, and its patching history.
If it is considered unavoidable to place user data into file or URL paths, then the data should ideally be validated when it is received by the server, against a whitelist of acceptable values. This is known as an “accept known-good” or “whitelist” input validation strategy and is preferred versus a “blacklist” strategy that relies exclusively on looking for malicious or malformed inputs.
Simply blocking input containing file path traversal sequences (such as dot-dot-slash) is not always sufficient to prevent retrieval of sensitive information, because some protected items may be accessible at the original path without using any traversal sequences. Negative or blacklist strategies are also likely to miss at least one undesirable input or may not cover all eventualities or bypasses if a developer is unaware of them, such as double-encoding techniques.
For example, if “../” sequences are removed from the “…/…//” string in a sequential fashion, two instances of “../” would be removed from the original string, but the remaining characters would still form the “../” string.
As a general best practice, an application should be set to execute using the lowest privileges that are required to accomplish the necessary tasks. In most cases, it is possible to create and assign an isolated special-case account with limited privileges for the specific task of running the application in question and having permissions only to a very limited set of files relating to that application, and nothing else.
This will not prevent filepath manipulation exploits, but rather will limit the impact of any exploit that an attacker is able to conduct.
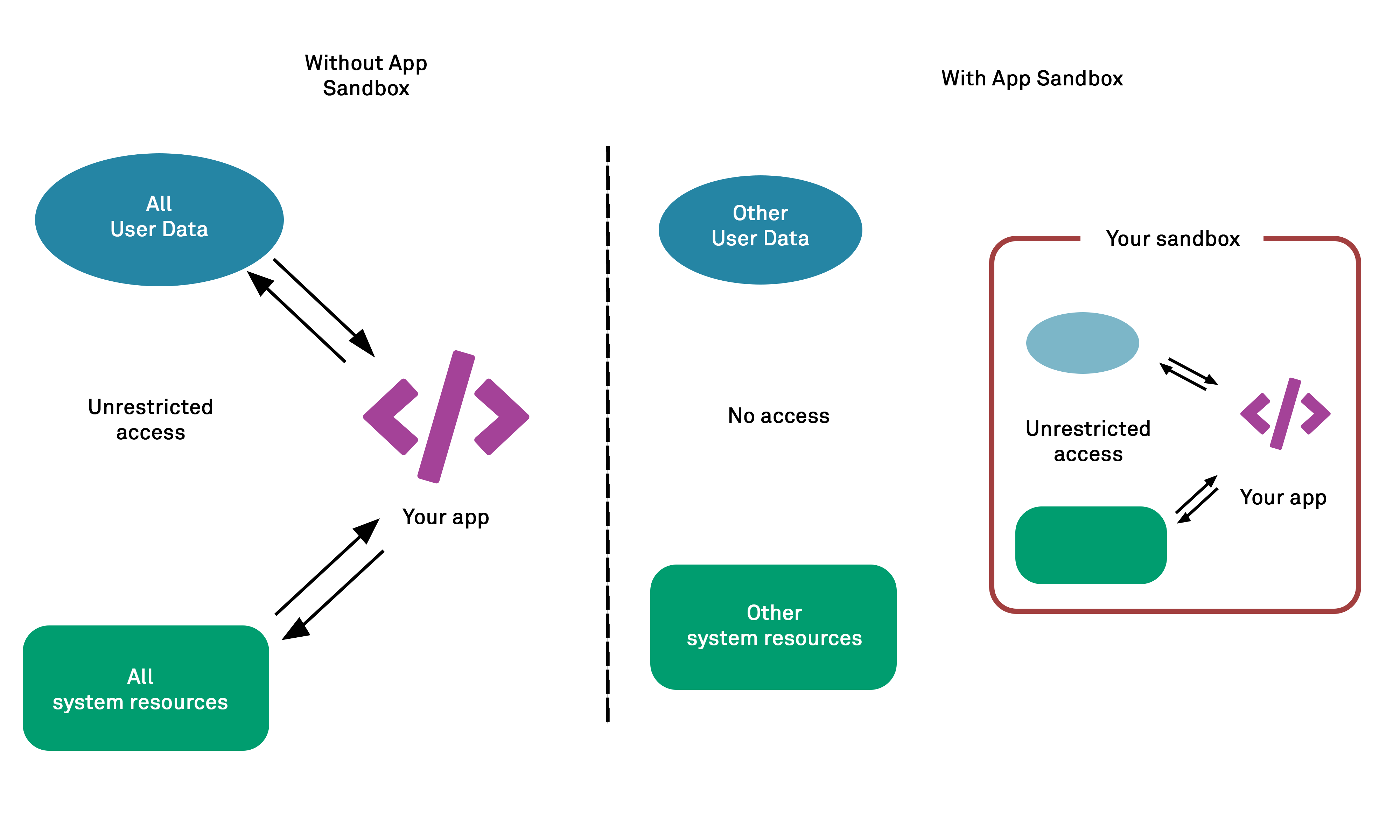
Similarly, in some operating systems and environments, it is possible to run applications in a “jail” or similar – a sandbox environment that enforces strict boundaries between the process and the operating system and assigns only limited and bounded resources for the application to access. This effectively restricts which files can be accessed by the application.
Lastly, it is advisable to confirm that an application is free of filepath manipulation vulnerabilities using a dynamic web application scan. Since production applications have specific environmental configuration that may not be found in other, pre-production instances, it is essential to check the production instance itself to screen it for such vulnerabilities.
AppCheck help you with providing assurance in your entire organisation’s security footprint. AppCheck performs comprehensive checks for a massive range of web application vulnerabilities – including filepath manipulation vulnerabilities – from first principle to detect vulnerabilities in in-house application code.
The AppCheck web application vulnerability scanner has a full native understanding of web application logic, including Single Page Applications (SPAs), and renders and evaluates them in the exact same way as a user web browser does.The AppCheck Vulnerability Analysis Engine provides detailed rationale behind each finding including a custom narrative to explain the detection methodology, verbose technical detail, and proof of concept evidence through safe exploitation.
AppCheck is a software security vendor based in the UK, offering a leading security scanning platform that automates the discovery of security flaws within organisations websites, applications, network, and cloud infrastructure. AppCheck are authorized by the Common Vulnerabilities and Exposures (CVE) Program as a CVE Numbering Authority (CNA).
As always, if you require any more information on this topic or want to see what unexpected vulnerabilities AppCheck can pick up in your website and applications then please get in contact with us: info@localhost