Every year we hear about more cases of so-called ‘data breaches’ in which sensitive information belonging to customers and stored by organisations is stolen by attackers. The Verizon Data Breach Investigations Report (DBIR) for 2019 examined over 2000 such breaches within organisations, leading to lost data, direct financial losses, and regulatory fines and penalties.
However there is a different form of data leakage that is more widespread and pervasive, less detectable, and requires very often no explicit action from an attacker beyond making seemingly-legitimate requests to a web service – requests that will not trigger IDS, WAF or other intrusion detection alerts.
We’re talking about the general category of ‘information disclosure’, or simply returning “unexpected stuff” to remote requesters – typically service or system metadata – that we did not intend to, and which do not form part of our service contract or intended service operation. In general, web applications whether static or dynamic offer some form of planned data service, allowing requester users to access (and sometimes modify or update) data records. Depending on the system, that data set may be health records, order entries, or photos of kittens, but the principle is the same – there is an established data set that is intended to be operated upon. Everything else that supports the system information is not an in-scope asset and should not be made available to customers.
Information disclosure occurs when this out-of-scope data – such as information relating to the service operation, or its operators – is returned to clients in-band through the defined data response channel (e.g HTTP responses). Typically exploiting these vulnerabilities doesn’t require an attacker to do anything other than make passive requests (those not containing a malicious payloads) or to attempt to bypass access controls – often there is therefore no “attack signature” that can be detected in logs or blocked by Web Application Firewalls, and companies may find it impossible to prosecute an attacker or prove that they performed an action that was in any way criminal.
So let’s take a look into a few of the different ways that metadata and other information can be exposed, and the potential consequences of this occurring.
The first top-level category of information disclosure involves the exposure of a service, method or resource to the wrong audience.
Unintended Service Exposure
On occasion, a system is deployed that serves up useful information (‘metadata’) around technical service configuration or availability, intended for internal consumption. If this service is accidentally exposed on a public network, then an attacker can access it and retrieve information that can be useful to them in ‘fingerprinting’ a company’s service layout, and guide further attacks.
Classic examples would include the RPC service used within NFS, which responds to (unauthenticated) queries with a response containing a list of all registered RPC services as well as the ports that they are available on:
rcpinfo -p 192.168.122.131
program vers proto port service
100000 4 tcp 111 portmapper
100000 2 udp 111 portmapper
100024 1 udp 32781 status
100024 1 tcp 32775 status
100011 1 udp 32787 rquotad
100002 2 tcp 32777 rusersd
Similarly, the multicast DNS service (‘mDNS’ or ‘Bonjour’) is only meant to be exposed on a local rather than public network since it allows anyone to uncover information from the remote host such as its operating system type and exact version, its hostname, and the list of services it is running. In this example query we can see that:
$ mDNS -L secure-shell ssh tcp local 5353
Geraldine-Sbragias-iPad.local,Geraldine-Sbragias-iPad.local
Mary-Jane-Longrichs-iPhone.local,Mary-Jane-Longrichs-iPhone.local
Jeffrey-Heines-iPhone.local,Jeffrey-Heines-iPhone.local
Ian-Moffats-iPhone.local,Ian-Moffats-iPhone.local
Alex Shuker?x80x99s MacBook._afpovertcp._tcp.local,Alex Shuker?x80x99s MacBook._smb._tcp.local,Alex Shuker?x80x99s MacBook._ssh._tcp.local,Alex Shuker?x80x99s MacBook._sftp-ssh._tcp.local,Bluetooth DUN @ Alex Shuker?x80x99s MacBook._ipp._tcp.local,Alex-Shukers-MacBook.local,Alex-Shukers-MacBook.local
In this hypothetical scenario, the user’s names used in the discovered machine hostnames (a common practice) enables an attacker to perform attacks such as targeted spear-phishing.
Although it is perhaps relatively uncommon to find an exposed RPC or mDNS service on the public internet in 2020, this same type of inadvertent service exposure continues to be present in more modern services such as cloud infrastructure, such as the potential exposure of AWS metadata service:
user@host~$ curl www.example.com/latest/meta-data/iam/security-credentials/[ROLE]
{
“Code” : “Success”,
“LastUpdated” : “2019-08-15T18:13:44Z”,
“Type” : “AWS-HMAC”,
“AccessKeyId” : “ASIAN0P3n0W3y1nv4L1d”,
“SecretAccessKey” : “A5tGuw2QXjmqu8cPEu1zs0Dw8yt905CDCzrF0AdE”,
“Token” : “AgoJd2JpZ2luX2VjEJv//………”,
“Expiration” : “2019-08-16T00:33:31Z”
}
In this (fictional) example, the misconfigured metadata service on AWS is exposed publicly and can be accessed to access the customer’s AccessKeyId, SecretAccessKey, and the Token for their AWS account. Using these credentials, an attacker could login to AWS and compromise the customer’s operated services and instances.
Unintended Method Exposure
Related to the above, a service can sometimes be intended for public exposure, yet offer up specific privileged methods that are inappropriately accessible to a public audience and hence expose data. One commonly encountered example is the ability of attackers to conduct DNS zone transfers from vulnerable DNS hosts. The DNS service itself in this scenario is exposed deliberately, in order to permit hostname resolution – however if an attacker is able to successfully request a zone transfer from the vulnerable host then all the DNS entries for a given domain will be transmitted to them. Zone transfers offer a wealth of reconnaissance information. With this information, a hacker can map your network in preparation for an attack.
A lesser known and more esoteric example is the similar exposure of inappropriate methods on SMTP servers. Just like the HTTP protocol has well known verbs including “GET” and “POST”, SMTP servers can implement verbs including “VRFY” and “EXPN”. VRFY and EXPN essentially ask the server for information about a given email address. If an attacker can access this service directly, then they can swiftly enumerate through available accounts, performing username enumeration to use in a phishing attack for example. The VRFY verb might reply with a full email address based on guessed username. For example:
VRFY jones
250 jones@heaven.af.mil
VRFY smith
250 Locksmith <pick@heaven.af.mil>
Resource Exposure
A third variant of the above is when a low level resource is inappropriately exposed. That is, the service (e.g HTTPS) and method (e.g GET) are both offered legitimately, but a specific resource is presented to the public internet when it should be restricted to an internal resource sphere. Perhaps the most commonly seen example is the failure to restrict access to the “phpinfo” page on a PHP platform. Commonly published as a webpage in its own right, the page can reveal details including server software versions and absolute filepaths to attackers.
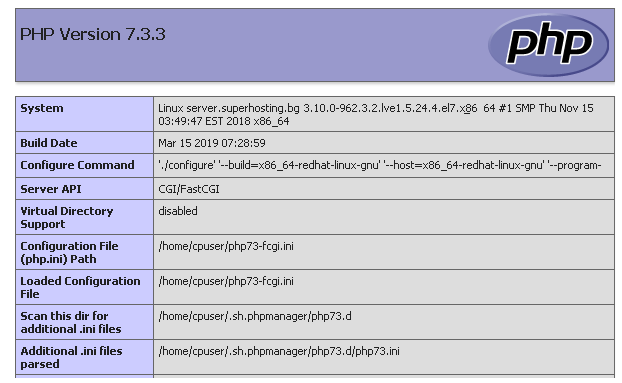
Banner Grabbing & Leaky Headers
Even where a service, its methods and its resources are both exposed deliberately and appropriately restricted, an attacker may still be able to discover data where it is returned to the user. A commonly seen example is the exposure of HTTP headers by a web server in its responses, in which the server inadvertently discloses information that can aid an attacker, such as the server version and languages used by the web server.
There’s two variants of this vulnerability. In the first, simpler example, a misconfigured webserver may simply return details of its running software because that is how a vendor configured it. For example:
Server Type : NGINX
Server Version : 1.12.2
The reason this is an issue is that in a ‘banner grabbing’ attack an attacker can harvest these responses in order to learn more about the system they are probing, in order to better understand its configuration and hence its vulnerabilities. Since there are openly published lists of vulnerabilities for given versions of services, an attacker can perform very specific targeted attacks against the vulnerabilities known to exist in the disclosed service version.
A second variant of this vulnerability is the exposure of headers that are added by developers or internal systems within an organisation, to aid debugging or allow request processing and filtering on services such as proxies. In this variant, headers provide some useful function internally, but represent an information disclosure if leaked externally and not stripped at the network edge. A commonly seen example is the exposure of a server’s internal IP addresses that are usually hidden or masked behind a Network Address Translation (NAT) Firewall or proxy server – there is a known issue with some versions of Microsoft IIS 4.0 web server doing this in its default configuration, for example. The server may leak information in its response, such as:
HTTP/1.1 301 Moved Permanently
Cache-Control: no-cache
Pragma: no-cache
Location: https://10.119.79.28/owa/
An attacker is again able to use this information in helping to “fingerprint” a company’s service layout, and guide further attacks.
In the examples that we’ve seen so far, the service is acting as designed and exposing only the information that it is intended to – the vulnerability comes in the fact that the audience that it exposes the information to is not appropriately restricted. However, sometimes a web service may be mis-configured in such a way that the information exposed has no place being served as a published web document at all. That is, the data presented does not form part of the documented service at all. We’ll look at several variants of this type below:
Service Configuration & Source Control Management (SCM) Files
Most development teams use some from of ‘Continuous Deployment’ pipeline in order to deploy assets and code for publication on the website. These are typically bundled into some form of discrete ‘release’ and may be versioned and published to an artifact repository from which they are deployed. Critically, the bundled artifact can contain – inadvertently – a range of files that are metadata relating to the service configuration, rather than intended content for publication within the web directory. Examples include the Web.config file that is used to define .NET framework projects, and Dockerfiles used to configure Docker images – most languages have their own variant. Depending on the file it could disclose sensitive data such as user credentials and configuration data. The resources are unlikely to be hyperlinked, but an attacker can guess “obvious” paths such as https://www.example/Web.config and see if the file is available.
Likewise, files describing the version control system or artifact repository system itself may be inadvertently bundled into a software release and deployed. Examples include:
Developer Comments
Developers will frequently use comments in code-bases in order to leave notes on function operation, details of why code is written in a specific way, notes for future work required and other purposes. This code is not intended for public consumption, but can occasionally be exposed. Such comments are generally safe if they are in server-side code (though we’ll see one exception to this below) but can be exposed if the comment is:
An attacker who discovers these comments can sometimes map the application’s structure and files, expose hidden parts of the site such as admin portals, and study the fragments of code to reverse engineer the application, which may help develop further attacks against the site.
Incorrect MIME Types
An exception to the rule that server-side code is generally not readable by attackers is the incorrect serving of the code as a resource to a requesting attacker. To understand how this occurs, we need to understand that there are generally two types of data within a web server’s document root:
Critically, both are requested in the same way, e.g https://www.example.com/example.dop
Whether a given resource is executed locally by the webserver, or returned to the client as a static resource generally relies on the configured handler in the webserver. An example from Apache here is a directive to process “*.php” files as locally-executed resources:
<FilesMatch .php$>
SetHandler application/x-httpd-php
</FilesMatch>
Apache and other webservers can determine the correct handling for a file based on either the file extension or its media type (also known as a Multipurpose Internet Mail Extensions or MIME type) such as “text/html”, which can be either ‘sniffed’ via parsing the file, or else explicitly set in the file, e.g:
header(‘Content-Type: text/html’);
However there are a couple of ways in which this can go wrong:
Unprotected Public Code Repositories
In addition to the exposure of individual files, occasionally an entire source code repository may be inadvertently published or exposed without access control. A code repository can often contain sensitive information and should generally not be accessible to users. Server-side source code may contain information which can help an attacker when preparing attacks against the application.
The final type of information disclosure typically seen relates to some kind of response variance between two requests made by a user. That is, there is a “normal” response state when a certain request is made, and then a secondary or alternative state that can be triggered under changed input or request conditions that discloses unintentionally some information about the system’s operation, environment, users or internal state.
Error Pages & Error Conditions
Perhaps the most obvious example is the possibility for a server to return an error page in certain conditions. This can be useful to an attacker in two ways. Either:
Both the triggers for and content of error messages can be either ‘self-generated’ in that the application source code explicitly constructs the error message and delivers it to the user or ‘externally-generated’ in that a system component such as a library or language interpreter handles the error and constructs its own message, the contents of which are not under direct control by the developer.
An attacker may use the contents of error messages to help launch another, more focused attack. For example, an attempt to exploit a path traversal weakness (CWE-22) might yield the full pathname of the installed application. Similarly, an attack using SQL injection might not initially succeed, but an error message could reveal the malformed query, which would expose query logic and possibly even passwords or other sensitive information used within the query.
Observable Response Discrepancy & Enumeration
Even in situations in which no error message is generated, a developer may inadvertently disclose some useful aspect of the decisioning logic within the application to an attacker by serving up differential responses to incoming requests in a way that reveals internal state information to an attacker. This issue occurs most commonly in the form of ‘user enumeration’ (revealing whether a given username is valid) that occurs on websites’ login pages, registration pages and in ‘Forgot Password’ functionality.
For example, when the user enters an invalid username and password, the server returns a response saying that user ‘Daniel’ does not exist – the system has revealed that the login failed because that username does not exist in the system. On the other hand, if the user enters a valid username with an invalid password, and the server returns a different response that indicates that the password is incorrect, the malicious actor can then infer that the username is valid. Since they know that the username is valid, they can then target that specific username with methods such as a password brute-force attack.
Side Channel Disclosures
We’re almost at the end of our run-through of information disclosure vulnerabilities, and we’ve left the most exotic and perhaps least commonly seen variant to last. This is the so-called ‘side channel’ attack, in which the application reveals nothing in its returned data that can be used to undermine or exploit the service, but the manner in which it serves the response, or some other observable characteristic nevertheless reveals information.
It may be possible for example for a highly skilled adversary to make determinations as to system state via discrepancies between multiple response in things like the response timings. For example, in some cryptographic algorithms, attackers can use relatively trivial timing differences to statistically infer certain properties about a private key, making the key easier to guess.
AppCheck help you with providing assurance in your entire organisation’s security footprint. AppCheck performs comprehensive checks for a massive range of web application vulnerabilities from first principle to detect vulnerabilities – including many of the information disclosure vulnerabilities outlined above – in in-house application code. AppCheck also draws on checks for known infrastructure vulnerabilities in vendor devices and code from a large database of known and published CVEs. The AppCheck Vulnerability Analysis Engine provides detailed rationale behind each finding including a custom narrative to explain the detection methodology, verbose technical detail and proof of concept evidence through safe exploitation.
AppCheck is a software security vendor based in the UK, that offers a leading security scanning platform that automates the discovery of security flaws within organisations websites, applications, network, and cloud infrastructure.
As always, if you require any more information on this topic or want to see what unexpected vulnerabilities AppCheck can pick up in your website and applications then please get in contact with us: info@localhost