When a user agent (web browser) receives a response from a web server in response to a request, it will most commonly contain a response body containing HTML code that that the user browser is intended to parse within the context of a Document Object Model (DOM) and render graphically as a webpage for display to the user. However, the specifications that underlie the technical implementation of the protocols used for the web mean that other response types are possible. One of these is the “redirect” mechanism that instead instructs the user agent to make a second request to an alternative resource instead.
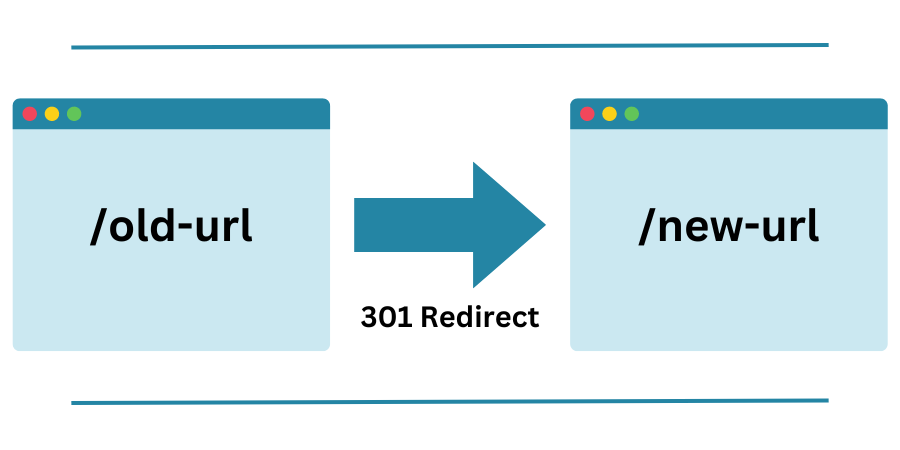
Having the user agent (the client) make this request themselves – rather than the server simply returning the resource at the redirected URL itself – is done for a few different reasons. Firstly, the server may wish to instruct the client that the resource has moved so that it does not make requests to the “old” location in the future. And secondly, the resource or URL that the redirect points to may actually be external, in that it is located on a different domain or host and not something that the original webserver is able to fetch locally and provide to the requesting client. As we shall see, this second form can be the cause of security issues.
Developers can choose to return a redirect response to clients for a number of different reasons. One of the original intentions for the mechanism was to provide a means of handling changed file locations and directory structures in the early days of the web. Modern web applications are largely dynamic and “build” webpages using techniques such as “MVC” (Model-View-Controller) using application logic, but early websites were largely static, with web resources and URLs mapping directly to the file structure on a web service. If a resource was moved within the directory structure, then the URL that mapped to it would no longer work and requesting clients would simply receive a “404 Not Found” response. Redirects provided a simple way of notifying clients where the resource had now been moved to, allowing website operators to move files within a directory structure without breaking functionality for remote clients that requested the resource at its previous location.
URL redirectors have since been pressed into service to implement newer techniques including load balancing, and features such as “URL shortening” as seen in services such as tinyurl.com.
However, within a typical web application the most common usage may be in tracking an “end state” URL that a user is to be sent to at the end of an interrupted workflow. For example, a user requesting access to a given page may need to login first. A web application might need to send them to a login page for this, diverting them from their intended destination, but then wish to redirect them onward to the originally requested page once login is completed.
For example, if a user requests access to:
http://example.com/my_account.html
then they may need to login, with the server redirecting them to a login page, but using the query string parameter to retain the originally requested page:
http://example.com/login.html?redirect=my_account.html
Once login is complete then the server takes the value from the query string and redirects the client back to the “my account” page, which they can now access, since they are now logged in:
http://example.com/my_account.html
There are a few different techniques that can be used to implement redirect functionality. The first, and one which is not as common as it used to be since it has been formally deprecated, is the <meta> tag or element within HTML itself. Designed for transferring metadata (literally data about data, rather than data that is intended for rendering as part of a webpage content), the META tag can take various arguments, with the “http-equiv” used for redirection:
<META http-equiv="refresh" content="60 http://www.example.com/newpage">
A second mechanism exists within client-side script that is returned by the web browser for execution within the user’s browser. The DOM can contain various elements that perform actions including redirection. In the below code for example, the action is triggered via the “onLoad”event: that is, executed immediately after the page has been loaded in the client’s browser:
<body onload="window.location = 'http://example.com/'">
However, the most common technique that is used is redirects via HTTP response codes. Most webpages returned via a browser use a “200 series” response code (between 200-299), indicating normal operation and typically confirming that the user’s request was completed successfully and requested content (if any) is being returned. However, HTTP also has a special kind of response, called an HTTP redirect. Redirect responses have status codes that start with 3 (300-399), and a Location header that contains the URL to redirect to: the most common response codes are “301 Moved Permanently”, “302 Found”, “307 Temporary Redirect” and “308 Permanent Redirect”.
When browsers receive a redirect, they immediately load the new URL provided in the Location header.
As we have seen above, the location to be redirected to is often explicitly passed as a parameter within the URL, although it is possible for the URL to be stored within an HTTP cookie on the client and then passed to the server within the Cookie header. In both cases (or even if some other, more esoteric method is used), the parameter is passed from the client to the server. When the server receives it, it sends a redirect to the client via one of the methods we outlined, such as a 300-series HTTP response code.
As with any situation in which the server performs an action that is contingent on user-provided input (as here), there is the potential for malicious behaviour if the user provides input other than what the server is expecting. When the evaluates the client-provided parameter but fails to validate it then many different types of security issue arise. In general, weaknesses where an attacker supplies untrusted input to a program which causes a security vulnerability are known as injection attacks and include the infamous class of vulnerability known as “XSS” or “Cross-Site Scripting”.
However, in the specific case of URL redirection, the issues most commonly being referred to when the user-provided input is returned back to the user with an instruction to redirect to it are known “Unvalidated Redirects”: these are less commonly referred to as “Open Redirects”, “Cross-Site Redirects”, “Cross-Domain Redirects”, or “URL Redirector Abuse”.
It is easy to envisage how attacks can involve a user sending malicious input to a server when the input is executed or used on the server in question. It can be less obvious how a vulnerability can occur when the server is simply returning input back to the client that it (the client) initially provided in the first place in an earlier request: surely a client isn’t going to attack themselves? Why would a client send an HTTP request that contained malicious input that was then sent back to themselves!
The answer to this apparent riddle is that although the URL to be redirected to is sent from the client’s web browser, a client (in terms of the human operating the web browser) does not explicitly form the URL (and the query string containing the malicious input). In most cases, navigating the web is performed by simply clicking on links, and often without checking in advance the URL that is being requested. Only infrequently are URLs typed out in full, especially after the initial start of a session.
This means that the ability to control the URL redirection parameter actually lies with whoever is serving that initial link. When this is a trusted and legitimate website such as the BBC, then there is typically no danger in this, provided that the URL is entirely formed by elements within the site’s own control. However, whenever control of the URL parameter in question has been passed to a malicious actor in forming the link, then security weaknesses such as URL redirection can occur.
This can occur either when the link being clicked on is from an untrusted source (such as an email sent by an attack) or from a trusted source but using user-provided content (such as the “forums” area on a trusted website) then an attacker is free to craft a URL containing a malicious redirect, which is then clicked on by an unsuspecting victim. This is very commonly seen in so-called “phishing” attacks.
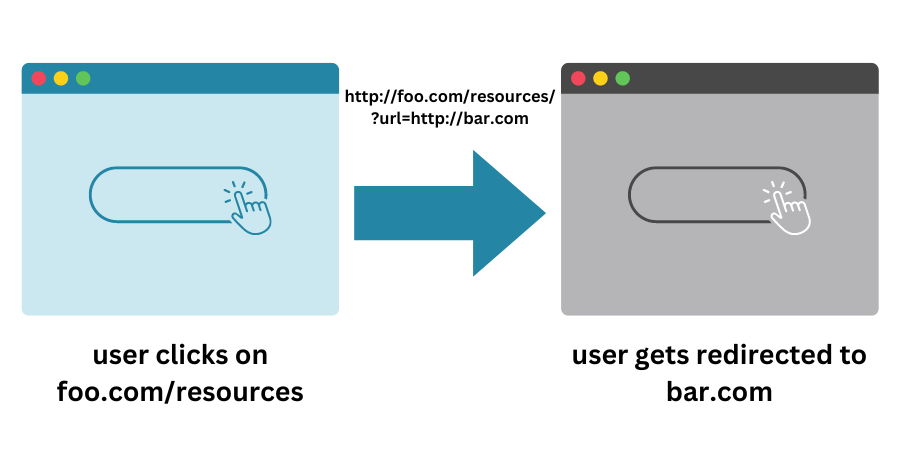
By crafting a URL value that contains a link to a malicious site within the query string parameter used by the server to pass back to the client in the form of a redirect, an attacker can therefore control which webpage a victim ends up on. This is obviously true for any links that exist on a malicious website: the attacker has complete control of the webpage content in any case. However, without URL redirection, an attacker is reliant on a client visiting a malicious site, which they are normally unlikely to do, and would not trust even if they did. In the case of URL redirection, the attacker relies upon the fact that the URL originally requested in the crafted link looks legitimate because the original domain is one the user is familiar with and trusts.
http://example.com/login.html?redirect=http://www.evil.com.html
URL redirection effectively performs a “sleight of hand” trick, in that the client requests a URL from a trusted site but is redirected to the untrusted one. Since this redirection is invisible, if the attacker crafts the malicious URL to look and behave the same as the original website, then a client who does not check the URL in the “Location” address bar of their browser after every single click will believe that they are still on the original (trusted) website.
Clients landing on the malicious site will believe that they are still on the trusted website. All the attacker has to do to exploit this is have their malicious site simply ask a user to login. Since the user still believes they are on the trusted website, then will enter their login credentials for the trusted site: but the credentials are submitted and captured by the attacker. Once the credentials have been harvested in this way, the attacker can then use the captured valid credentials to login as the client on the trusted site.
This could be exploited in a number of ways depending on the website or web application in question, but the dangers should be fairly clear: if the site is an online bank for example, an attacker has just gained access to the client’s account and funds.
If the use of client-provided redirects cannot be avoided altogether, then as with all user-provided input it should be assumed that the input is malicious and needs validating before it is used. MITRE, who maintain the “Common Weakness Enumeration” list, as well as OWASP (The Open Web Application Security Project) both advise the input validation should involve the use an “accept known good” input validation strategy, i.e., checking user-provided input against a list of acceptable inputs that strictly conform to specifications. Ay input that does not strictly conform to specifications should either be rejected completely or else transformed into a safe form that does via a process known as sanitization.
When performing input validation, it is possible to check various attributes of the supplied string, including length, type of input, the full range of acceptable values, and the input syntax.
A less common prevention mechanism is the use of intermediary “redirect warning pages” by the site. This involves the insertion of a “warning, we are redirecting you to Page X on an external site” webpage being displayed by the trusted site, with the target URL being shown, rather than immediately redirecting. This lets users view the URL and sanity check it but is a relatively weak control, since it relies on the user being able to notice maliciously formed URLs and could be missed completely by them.
The most robust form of defense against URL redirection is simply not to reflect the user-provided input back to them as the URL to be redirected to, but instead using a trusted value. This can be performed when the list of possible redirect locations is known in advance. Each can be documented on the server and mapped to a numeric ID, for example:
| ID | URL |
| 1 | http://www.example.com/login.html |
| 2 | http://www.example.com/my-account.html |
The redirect parameter is therefore only stored server-side and never exposes to the client. The parameter used to indicate which page redirect to is instead a simple numeric ID. This can be much more easily validated, and any input that does not match a known ID simply rejected by the server.
AppCheck can help you with providing assurance in your entire organisation’s security footprint, by detecting vulnerabilities and enabling organizations to remediate them before attackers are able to exploit them. AppCheck performs comprehensive checks for a massive range of web application and infrastructure vulnerabilities – including missing security patches, exposed network services and default or insecure authentication in place in infrastructure devices.
External vulnerability scanning secures the perimeter of your network from external threats, such as cyber criminals seeking to exploit or disrupt your internet facing infrastructure. Our state-of-the-art external vulnerability scanner can assist in strengthening and bolstering your external networks, which are most-prone to attack due to their ease of access.
The AppCheck Vulnerability Analysis Engine provides detailed rationale behind each finding including a custom narrative to explain the detection methodology, verbose technical detail, and proof of concept evidence through safe exploitation.
AppCheck is a software security vendor based in the UK, offering a leading security scanning platform that automates the discovery of security flaws within organisations websites, applications, network, and cloud infrastructure. AppCheck are authorized by the Common Vulnerabilities and Exposures (CVE) Program as a CVE Numbering Authority (CNA)
As always, if you require any more information on this topic or want to see what unexpected vulnerabilities AppCheck can pick up in your website and applications then please contact us: info@localhost