A cache in computing is a temporary store of any content that has been retrieved from its original (master) source. Caches are typically used so that the data can be served faster the next time it is requested, since it needs only be retrieved from the local cache rather than the original source.
A common example is the RAM in your computer, phone or tablet, which is small in storage capacity but many times faster to access than the larger but slower disks used for permanent storage. The idea behind caching is therefore very simple and almost ubiquitous within computing wherever content is frequently requested.
So how does this apply to web applications? Retrieving content from web servers can be both slow – especially if the file being retrieved is large or the server remote topologically – as well as “expensive” to generate for the source web server in terms of computing power if it has to be dynamically generated. Caches allow web servers to serve frequently-requested content far more quickly.
A caching system will sit somewhere in-line between requesters (users) of a service or content and the server. When the first request is made, the request is stored temporarily in the cache. If another request is made (by a user) for the same web address or URL, the web cache can use the response that it stored before, rather than relaying back a fresh request to the origin server:
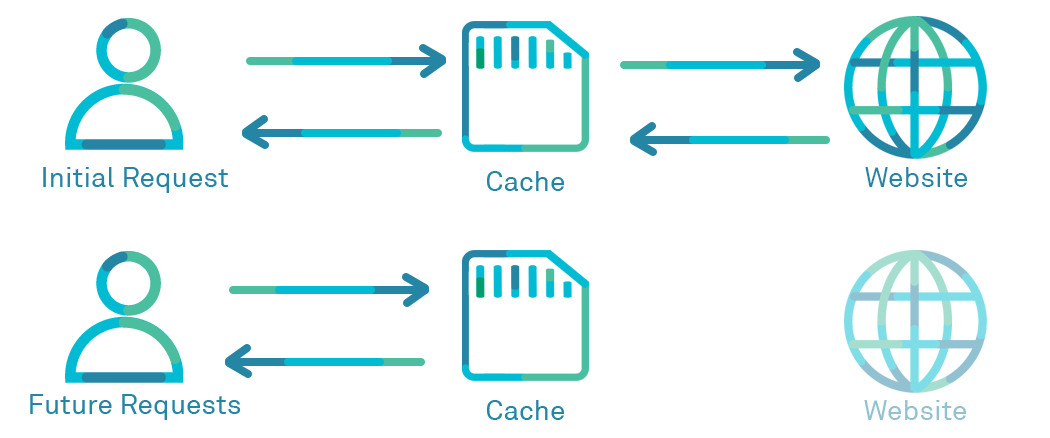
There are more than one type of web caches – they exist at several steps along the way between your browser and the source/origin server:
Browser Caches – browser caches use a portion of your device’s local disk storage to hold static copies of content such as web pages that you’ve previously visited to help speed up your online experience – when you visit a page again it may be loaded, invisibly to you, direct from your own PC’s cached copy – the request may never even leave your computer.
Proxy web caches – web proxies are often deployed by organisations to jointly cache requests from all the organisation’s users. They are located at the organisation’s network edge and can be very effective where many users are accessing common resources such as news websites.
Internet Service Providers (ISPs) – ISPs also typically operate proxy caches via interception proxies on their underlying network, leveraging the scale of possibly hundreds of thousands of users to cache frequently-requested content for all their subscribers.
Content Delivery Networks (CDN) – CDNs such as Akamai or Speedera are located across the world and are generally leased by commercial organisations who produce content. When configured in DNS, customers performing a DNS lookup for the origin server will receive an IP for a local CDN server operated by the CDN company that is authorised to masquerade as if it were the origin server, caching content from that provider for all users within a given region and drastically reducing the volume of requests made to the origin servers.
Gateway web caches – also known as surrogate caches, or reverse proxy caches – are typically used by website owners or managers, to make their sites more reliable and scalable.
Server memory caches – Examples include Memcached and Varnish and can run on same exact local host as the content origin source, generating static cached copies of dynamically-generated pages to save re-generation of them on the next request.
So caching sounds like it is massively beneficial, reducing both network delay (lag) and server loads. However, caching has limitations. A caching system needs to have at least two key functionalities in place:
Time Limits
Resources change and are updated so the cache needs to have a finite lifetime for each cached resource. We wouldn’t be happy if we requested the BBC News webpage on May 5th and found out that the news we were reading was from September the previous year. Cache items therefore have expiry time limits.
Hits and misses
Whenever a cache receives a request for a resource, it needs to decide whether it has a copy of this exact resource already saved and can reply with that, or if it needs to forward the request to the application server. For static content such as images, this might be simple – a photo of a cat is a photo of a cat, whoever requests it. However some pages are dynamic – if we access www.ourbank.com/balance then we want to see our own bank balance, not someome else’s (and vice versa) so caches can’t simply cache all content for all users.
Caches and their origin sources tackle this problem collaboratively using an agreed arrangement of “cache keys” – a few specific components of a HTTP request that are taken to uniquely identify the resource being requested. This can be done manually through the use of HTTP headers. The owner of the source data can ensure that the origin server returns headers to mark a resource as public or private, set a maximum age to store it, ask the browser to re-validate this resource each time or tell the browser not to cache a specific resource.
The problem from a security point of view is that any response that is successfully cached will by design be stored and served to other users, and in some circumstances this can lead to problems. Two specific types of web cache attack that have been seen are:
WCD attacks arise when there is a discrepancy between how a cache and an origin server interpret a given HTTP request. For instance, an attacker can craft a URL that points to the account information on a banking website but append to it a non-existent path component disguised as a static image, such as “/account.php/nonexistent.jpg.” Many origin servers will simply ignore the invalid suffix as spurious and respond with account details.
However, a web cache proxying the content may be oblivious to the processing that happens on the origin server to insert dynamic user-specific content, and store the response as if it were an image because of the file extension. If the attacker can trick a user into clicking on this link, the victim’s account information will be cached. The attacker can then access the same URL, retrieving the cached content containing the (dynamic) information personal to that user, and giving the attacker an opportunity to steal it.
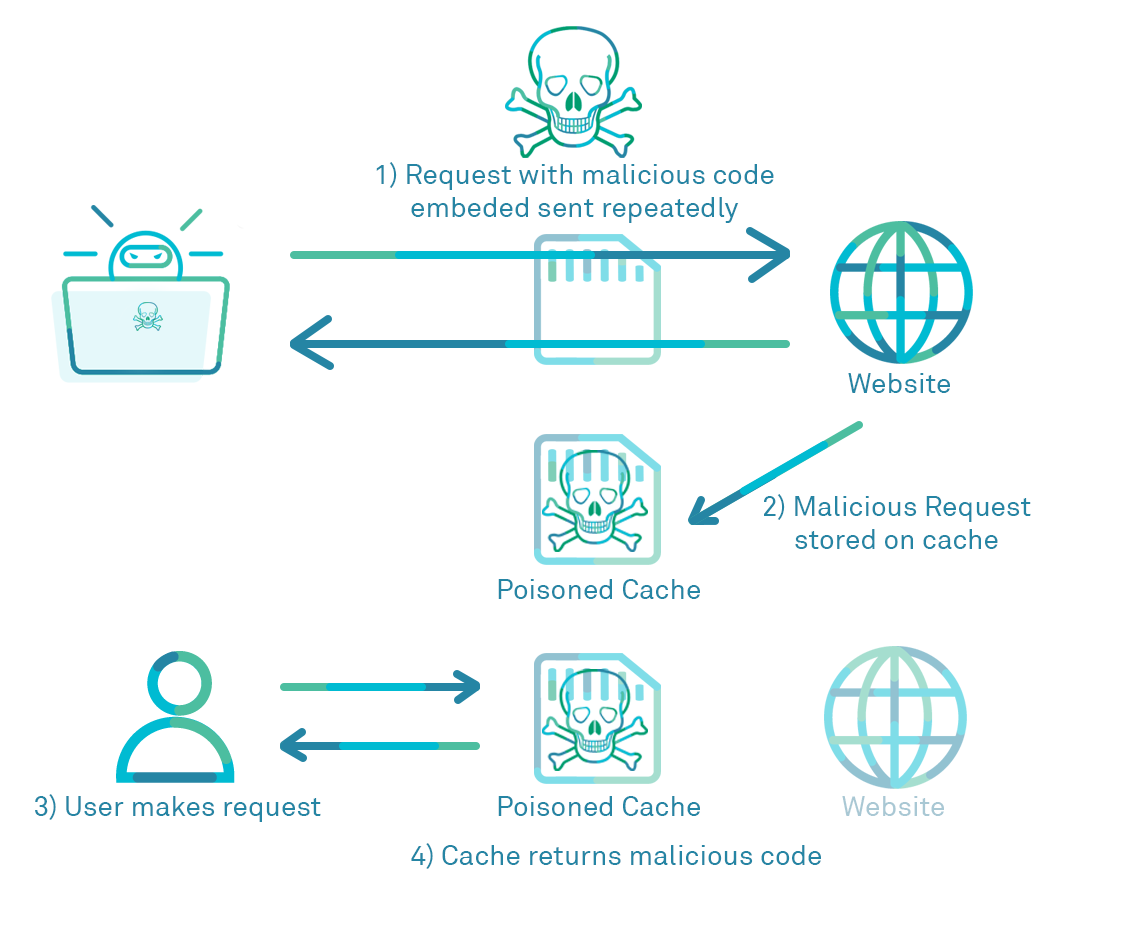
In a nutshell this is when an attacker manages to successfully embed malicious content in a request that gets reflected back into the server response and saved in the cache. The cache server will then unwittingly serve up the malicious response to anyone subsequently requesting the resource.
For example, an attacker could find a webpage vulnerable to reflected XSS. However reflected XSS is difficult for the hacker to exploit, since it requires getting a user to click on a specific link with the malicious payload within in. If however the attacker finds that the server in question has a cache and will store the malicious response payload in that cache, then future users requesting the page will have a malicious response returned from the cache. Executing the attacker’s arbitrary JavaScript.
A basic diagram of web cache poisoning in action:
So what steps can you take to avoid these attacks? Defending yourself against Cache Poisoning attacks can be quite tricky. Disabling caching entirely is one such way but it is not feasible in most instances. A less drastic option may be to only cache files that are truly static such as *.js, *.css, and *.png files.
If you depend on caching for performance however then you may be willing to accept a slightly greater risk and instead take a range of measures that together manage the risk without eliminating it entirely:
As always, if you require any more information on this topic or want to see how AppCheck can help with web cache poisoning vulnerabilities then please get in contact with us: info@localhost