Passwords remain the most commonly used form of primary authentication factor in both customer-facing web applications and internal corporate web-based systems. The insecure storage of passwords on the server side has been subject to frequent and repeated exploit, with entire username and password datasets being exfiltrated by malicious attackers. The situation has become so common that some websites now track and publish details of data breaches, with one such site reporting over 11 billion individual compromised accounts as of 2022 from over 600 websites and counting.
In this blog post we look at the issues surrounding secure password storage and how the use of salts in particular can help protect passwords in the event of a hack or data breach. We look at why salts are needed, how they work, and the best practice guidance for implementation.
Authentication is the process of verifying a claimed identity in order to establish a trust relationship between two parties. Verification relies on the provision of one or more “authentication factors” – types of evidence that can be supplied to back up your claim to a given identity. These factors are normally described as “something you are”, “something you own” and “something you know”.
As a simple example, imagine a phone call you receive asking you to transfer money. If the person claims to be your mother, then you would almost subconsciously verify this by noting whether the caller ID had displayed your mother’s mobile number when the phone rang (here the first authentication factor is “something you own”– your mother’s phone) as well as whether you recognise the voice as being that of your mother (here the second authentication factor is “something you are”, a biometric trait such as a voice pattern). We do this instinctively without even being aware that this is what we are doing.
When one party supplies a password to another, it is as a “shared secret”. This means that both parties must have knowledge of the password in advance. Passwords can be shared between multiple parties to create a trust network, such as in the sign/countersign system used by the Allied forces on D-Day during World War II: the challenge/sign was “flash”, and the password response “thunder”.
However, in computing the most common form is where passwords are used in combination with and are unique to a specific user ID. They are typically used in a client-server relationship in which multiple clients need to authenticate (using their own unique IDs) to a single central server or authentication service, creating a many-to-one relationship.
This many-to-one relationship means that servers become repositories for vast numbers of passwords. Whereas each client or user only has a single password (and hence account that can be compromised), the server has to maintain a record of every user-password combination, in a potentially massive central repository, in order to be able to verify each individual connecting client’s identity.
The server therefore needs to verify that for a given user the password they have supplied is “correct”, in that it positively verifies their claimed identity. However, this causes something of a dilemma from a security point of view: simply storing every single user’s password in plaintext on the server, so that passwords supplied by users can be compared against them to check if they are valid is incredibly dangerous. Attacks such as SQL injection are incredibly common and can allow remote attackers to exfiltrate or steal entire data sets. In the case of username/password combinations, this could lead to potentially millions of accounts being compromised in a data breach.
Every year hundreds of millions of real-world passwords are exposed in data breaches. This can be individually catastrophic for a given organisation that is the subject of a data breach, leading to loss of customer trust, lost customers, negative publicity, regulatory fines, direct costs in digital forensics and additional corrective controls, potential compensation, and lawsuits, and can sometimes even threaten business continuity and viability.
However, it can also have far-reaching consequences for individual customers of the breached organisation too. Even if the data breach in question is from a site that is relatively low value in terms of direct account breach – such as a website that simply allows users to share cooking recipes with one another for example – the consequences for the users can be far more serious than might initially be assumes. This is because once a password has been leaked in a data breach, they are known to attackers. This exposure makes them unsuitable for ongoing use and clearly that password should not be used again when creating any new accounts. However, critically, the password may already have been used by the user on another website – potentially one with much higher value to attackers, such as an online bank.
This is because of the combination of “password reuse” as a weakness and “credential stuffing” as an attack. Password reuse is simply where a user, struggling to remember multiple passwords and perhaps unaware of tools such as password managers (or reluctant to use them) simply picks one, memorable password and then uses it for all their accounts. Password reuse undermines security but remains relatively common because it is convenient, and users are often unaware of or unable to foresee the potential impact should a single service have a data breach.
However, attackers make use of “credential stuffing” attacks, taking advantage of this known behaviour. They are able to take advantage of reused credentials by automating login attempts against systems that have not been compromised, using known emails and password pairs from systems or services that *have* been compromised.
Every compromised system and data breach therefore acts in a cascading manner to lead to more and more other systems becoming vulnerable to credential stuffing attacks: a failure of one organisation can directly impact the security of users on other organisation’s websites, even if they are not themselves at risk of direct data breach via a vulnerability of their own. It is therefore important on three counts – for an organisation itself; its users; and as a responsible member of the greater community to protect other organisations – to ensure that passwords are safely and appropriately secured at rest.
The simplest approach to password storage is to simply store every user’s password, in plain text, alongside their username, in a central repository such as a database. However, history has repeatedly shown that this is a tremendously bad idea. Common forms of attack such as SQL injection have demonstrated repeatedly the relative ease by which a simple vulnerability in front-end application code can be leveraged by attackers to exfiltrate entire data sets. Attackers with access to potentially thousands of valid username/password combinations for an organisation makes for one very bad day for everyone from the security team and operations staff, through the IT management and up to director level.
A relatively common mistake made by developers who are at least marginally aware of the risk posed by storing passwords in plaintext is to encrypt them before writing them to database or file. When a user logs in, the application reads the (encrypted) password from disk, unencrypts it using a key, and then compares it to the (plaintext) password provided by the user. However, this does not add much additional security and therefore provides a relatively weak form of protection: if an attacker is able to access the encryption key in addition to the dataset, then, again, they have access to the entire data set. It does provide some additional security, just not much – and there is a better approach.
The issue with encryption is that it is designed for a different purpose, in that it has to be reversible – that is, the plaintext must be recoverable using a mirroring process of decryption in order to read the original message. Without this property, encryption is no use for its primary purpose of securing data, since the data is no longer useable or recoverable, it may as well be simply erased.
However, there is a cryptographic transformation other than encryption, and which does not have the property of being reversible. It is not quite as much of a household term as encryption so is less widely known. That is hashing. Hashing is a cryptographic transformation that is one-way – that is, not reversible. A given plaintext once hashed is transformed into a string, but there is no reverse function that can be applied to recover the original text.
For example, using one example hashing algorithm, the phrase “password” can be hashed resulting in the following string:
hash("password") = “2cf24dba5fb0a12e26e83b2ac5b9e29e1b161e5c1fa7425e7”
You may be wondering how this is useful: if the password cannot be recovered from the hash, then how is storing the hash useful? Surely, it’s no more useful than just storing a random string, and equally useless for checking a user’s password is valid.
The answer lies in the fact that although there is no transformation that can be applied to the hash to recover the password in order to compare to the user’s password that they supply on login… there is a transformation that can be applied to the user-supplied password: the same hashing process. Rather than recover the password from the stored form for comparison (as in encryption), we instead hash the user-supplied password, and then compare hashes to the stored hash. At no time does the server actually “know” the password, but it can verify the user-provided password is correct (without knowing it) by checking if the resultant hash matches the stored one.
Hashing works because it has additional properties beyond that of being irreversible as we saw above. The first property is that it is repeatable or consistent, in that the same hash function always generates the same hash for a given input – the output is not random each time. This is important since it means that the user-provided password can be hashed and compared to the stored password hash.
It also has additional properties that are perhaps slightly less obvious but equally important. The first is termed collision resistance and means that it is highly unlikely that two given inputs (passwords) will result in the same hash. This is an important property when using hashes for password storage, since without it there may be multiple passwords that could gain access to a user’s account beyond the real one: remember that the server does not “know” the true password, only the password hash. So, without the property of collision resistance, an attacker could potentially authenticate successfully using multiple passwords other than the real one!
The final property is known as cascading and means that any minor change in the input (the password) results in a substantial and unpredictable change in the hash output. This is important since it prevents attackers with access to the hashed password dataset from using a trial-and-error process of “hotter… colder…” to try repeated password inputs to the hash and seeing if the resultant hash gets closer in appearance to the stored hash.
Hashing passwords certainly moves security on compared to simply storing passwords in plaintext. However, as in all areas of security, there is always somewhat of an “arms race”, with attackers devising techniques to address increased security measures. Although the first instance of storing hashed passwords likely thwarted attackers at the time, that is no longer the case.
The underlying issue is that attackers can run passwords through the exact same algorithms and check if the resultant hash is valid. When in possession of a data set, this doesn’t need to be done slowly across a network but can be done using a brute force attack, at high speed, using a local data set and multiple CPUs or GPUs. Even with this resource on-tap, a hash may take some time to find a match via brute force. However, the problem is that once a hash of a password is generated, it is valid (within a given hashing algorithm) in perpetuity, and across all systems. This means that an attacker doesn’t even have to perform a hash calculation of each password. They can simply download a dataset (which is freely available) of hashes of all common passwords. These so-called hash tables or “reverse lookup tables” contain pre-calculated hashes of every password (or at the least millions of passwords up to a given length) that someone else, with greater time and computing resources has already generated. Now all they need to do is check to see if any of the hashes of the hash table match with any of the hashed passwords in the database – an extremely lightweight and fast process that can take literally minutes – and they have your (and everyone else’s) password.
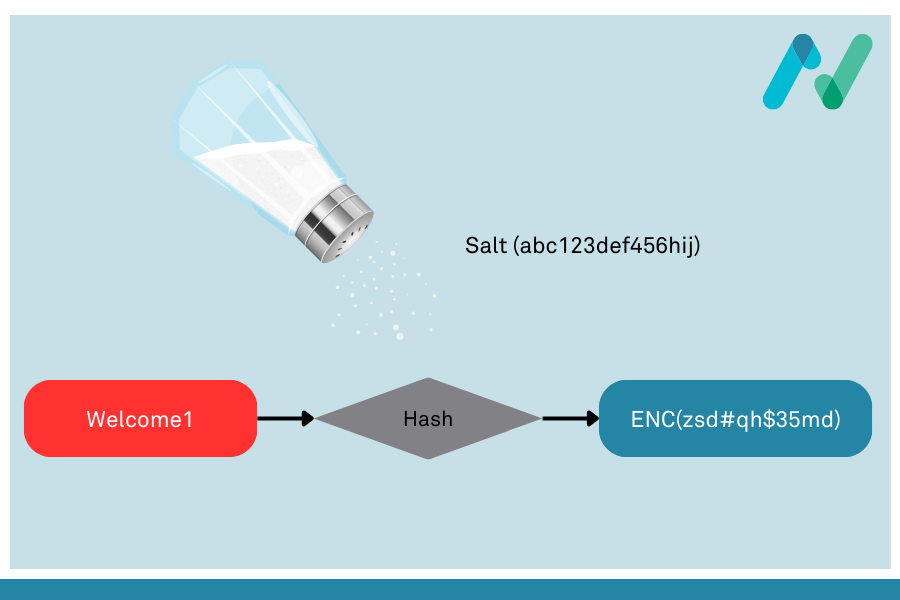
Lookup tables (and a variant known as rainbow tables) work because each password that is hashed produces the same resultant hash each time, due to the property of hashing transformations as being repeatable and consistent, as we saw above. What’s needed to prevent lookup table attacks is some way of performing a hash function on a password when we store it on our system such that the resultant hash is different to when the same hash function is performed against the same password on any other system. That sounds initially like a contradiction of the property of repeatability, however this is where the concept of “salts” comes in.
Salts are an incredibly simple idea, and do not rely on any additional complexity or changes to hashing algorithms: they simply require that the input that is fed into the hashing algorithm (i.e., the password) is different on our system than on any other system. Clearly the password itself can’t be changed since we need to verify the user’s password by hashing it. However, there is nothing to prevent us from simply appending extra characters to the user’s password in order to change the resultant hash. As long as the extra characters are a unique string that we use on our system, and we use the same unique string when both generating the hash to store, and when hashing the user-provided password on login, then we can still perform a hash comparison. The following pseudo-code shows how the hash output would vary depending on the hash of the same password but using different salts:
password = “password”
Salt_one = “12345”
salt_two = “67890”
input_one = concatenate(salt_one, password)
input_two = concatenate(salt_two, password)
hash(input_one) = 58756879c05c45dfac9866712fad6a93f8146f337a78t2
hash(input_two) = c0e81794383291161f1777c232bc6bd9ec38f616560b1
It is of course theoretically possible for an attacker to generate hash tables for every possible password combined with every possible salt. However, there are two factors that make this unfeasible. The first is that managing to generate a matching hash doesn’t actually provide attackers with a guarantee that they have found the password, because they cannot tell what part of the input is the salt and what part is the password. However, the second factor is more critical and is that provided the keyspace of possible salts is sufficiently large (i.e., the salt is not a simple one as in our example but something like a 256-bit number) then an attacker would need to generate an infeasibly large set of hash tables, one for each of potentially hundreds of billions of salts. Given than one commonly used hash table for unsalted passwords is around 17.2GB then creating hashes for potentially billions of salts for billions of passwords would require an exponentially massive amount of both storage and processing power. It would take literally exabytes (thousands of petabytes) of storage, or over one quintillion bytes. It’s hard to express such a large number, but it’s simply not feasible.
As with any security measure, it is possible to implement salts in optimal or sub-optimal ways. In general, it is generally considered best to try and make use of known and trusted third-party libraries rather than attempt to write your own code to perform the functions needed, since the latter can introduce errors in coding or be based on potentially flawed understanding of the underlying concepts. This is especially true for cryptographic functions. However, if you do need to develop your own functions for password storage and salted hashing, then the following tips can prove useful:
Although we have discussed hashing functions in this article within the context of password hashing and storage, hashes are widely used for a variety of purposes, such as in checksums and integrity verification or error detection in communications. There are therefore a wide range of hashing functions available, and many are developed with specific use cases in mind. This means that not all hashing algorithms are cryptographically secure – that is they are not optimised for, and perhaps may not be at all suitable for, use in password hashing. Hash functions such as SHA256, SHA512, RipeMD, and WHIRLPOOL are cryptographic hash functions, but each has specific advantages and disadvantages, and some are stronger than others. Where possible a specific cryptographic library should be used.
Not all hashing functions are created equal, even if designed to be cryptographically secure. Some hash functions are simply outdated or old, making use of algorithms that were optimised for much slower processors used in the past but are no longer suitable today. Other algorithms have been found simply to have weaknesses that can be exploited by attackers and are no longer recommended. MD5 and SHA1 for example are both now considered to be deprecated and outdated in most usage cases.
So long as a hashing algorithm is still considered to be cryptographically secure, then it is important when used in password hashing that it is relatively slow or expensive in performing its operations. This generally involved the use of multiple “rounds” of hashing. The advantage of a slow hashing algorithm is that hashes are slow to generate. This presents a minor burden on servers performing login since they are only generally performing a few hashes at any given point in time but provides assurance that an attacker attempting to generate large numbers of hashes within a brute force attack or in order to generate a hash table will require an unlikely amount of computing power.
In order to provide maximum resistance to brute forcing and hash tables, the salts used for hashing should be unique per user. That is, each user has their own unique salt stored against their record that is used in generating the hash of their password.
Ensure that salts used have the same properties as passwords, in being not only unique per user but “strong” in terms of being from a suitably large key space: this means using a varied character set and a minimum salt length, ideally the same length in bits as the resulting hash. A longer salt effectively increases the computational complexity of any attacker attempting to generate hash tables, and increases the candidate set exponentially. A longer and “stronger” salt also increases the space required to store hash tables while decreasing the possibility that such a table exists in the wild.
“Key stretching” has a few different use cases within cryptography, but within hashing means ensuring that the hash function is chosen or configured to be suitably slow by using a large number of cryptographic “rounds” when generating hashes. Modern, high-end graphics cards (GPUs) in particular can compute billions of hashes per second if each operation is sufficiently fast: using key stretching makes these efforts by attackers far less efficient.
A “pepper” is a partnering measure that can be used along with “salts” to improve hash security, although it is somewhat controversial and not universally recommended by all best practice guides. A “pepper” (also known as a “secret salt”) involves using a secondary value, in addition to the salt that is used as an additional input to the hash function along with the salt. The “pepper” value differs from the salt in that it is not stored alongside a password hash (as the salt usually is), but rather is kept separate in some other medium, such as a Hardware Security Module in the most secure implementations, or code if not.
The idea is that an attacker might have partially compromised a host via SQL injection, and hence have access to the hashes and salts, but not have achieved complete host compromise. A pepper can be either universal (shared in common by all users) or per-user and is similar in ways to an encryption key in that its value over a salt relies upon it remaining secret. So long as the pepper is used in addition to the salt, and not in place of it, then there is little disadvantage to making use of it so long as it is properly implemented.
In many ways similar to the use of peppers, encrypting the hash output also makes use of a secret cryptographic key, but is used to encrypt the hash output prior to storage, rather than having the key used as an additional input to the hash function. The overall intent is the same as with the use of peppers – that an attacker who has exfiltrated the dataset via a means such as SQL injection, but who has not achieved full host compromise, cannot use hash table attacks to brute force the passwords from the hashes.
One final tip to mention is that the hashing should always be performed on the server. Sometimes developers will attempt to use client-side JavaScript to hash the password on the client side and send the hash to the server for comparison. This greatly weakens the security that hashing provides, since the hash itself effectively becomes the user’s password in that an attacker needs only to know the hash (and not the original password) in order to authenticate as the user.
AppCheck can help you with providing assurance in your entire organisation’s security footprint, by detecting vulnerabilities and enabling organizations to remediate them before attackers are able to exploit them. AppCheck performs comprehensive checks for a massive range of web application and infrastructure vulnerabilities – including missing security patches, exposed network services and default or insecure authentication in place in infrastructure devices.
External vulnerability scanning secures the perimeter of your network from external threats, such as cyber criminals seeking to exploit or disrupt your internet facing infrastructure. Our state-of-the-art external vulnerability scanner can assist in strengthening and bolstering your external networks, which are most prone to attack due to their ease of access.
The AppCheck Vulnerability Analysis Engine provides detailed rationale behind each finding including a custom narrative to explain the detection methodology, verbose technical detail, and proof of concept evidence through safe exploitation.
AppCheck is a software security vendor based in the UK, offering a leading security scanning platform that automates the discovery of security flaws within organisations websites, applications, network, and cloud infrastructure. AppCheck are authorized by the Common Vulnerabilities and Exposures (CVE) Program as a CVE Numbering Authority (CNA).
As always, if you require any more information on this topic or want to see what unexpected vulnerabilities AppCheck can pick up in your website and applications then please contact us: info@localhost