Trust boundaries are a concept that is used in cybersecurity, especially security architecture and threat modelling. It describes efforts to establish a logical framework for grouping and managing the control of access to data or systems based upon data sensitivity or data classification levels, in order to manage risk. Within recent years, paradigms such as micro-segmentation and zero trust have built upon the concept of trust boundaries to offer models for increased data security in response to the challenges presented by increasingly complex and porous data networks within organisations.
In this blog post we look at what trust boundaries are, how they are commonly utilised, and what simple processes teams can take in order to begin the process of implementing trust boundaries in order to better manage cybersecurity risk.
Trust describes the willingness of one party to become vulnerable to another. Trust is extended by the trustor to the trustee on the presumption that the trustee will act in ways that will benefit the trustor. A basic example is the “trust game” where one person falls backwards, trusting that the other will catch them and prevent them from coming to harm.
Within computational science, trust is an important concept: computer systems maintain a state based on data that can be created, modified, read, and deleted in what are known as “CRUD” operations. Determining who can perform these operations requires computing systems to define who can be trusted to act appropriately to maintain that data in a faithful state, and who cannot be trusted. Trust normally involves a judgement as to both the measure of belief that the trustee can be relied upon to act benevolently towards the data, as well as an assessment of their competence or qualification to do so.
As the trustor cannot guarantee in advance the precise actions of the trustee (or their outcome), the trustor can only extend trust based upon beliefs as to the motivations of the trustee, dependent on their characteristics. This means that trust is always slightly uncertain and there is always some risk of failure or harm to the trustor if the trustee does not behave as expected.
In social sciences, a distinction is made between generalized trust (also known as social trust), which is the extension of trust to a relatively large circle of unfamiliar others, and particularized trust, which is contingent on a specific situation or a specific relationship. Within web application security, for example, there is a generalized trust extended to all potential users, that they will access the website for legitimate purposes and consume a proportionate amount of resources (e.g., not perform a denial-of-service attack). There is also particularized trust extended to much smaller groups, such as the ability to perform updates to the website.
It is this “particularized” form of trust – where trust to perform specific operations is extended to a finite and defined group – which is typically referenced in cybersecurity. Particularized trust is defined whenever there are some securable objects such as a set of files, records, or services, to which a generalized trust cannot safely be extended, and access must be restricted in some way.
The set of operations over values of trust determines the result of those operations produced and is defined within an access control model or framework that typically presents some mapping between objects (the item to be accessed) and subjects (the persons or systems trusted with access to the objects). Different forms of access control are commonly implemented, with the specific model used depending upon security requirements, underlying system design, and the nature of the subjects and objects involved (e.g., subjects may be either human actors, or computer systems). Examples of different access control types that define trust relationships include “Discretionary Access Control (DAC),” “Mandatory Access Control (MAC”) and “Role Based Access Control (RBAC).”
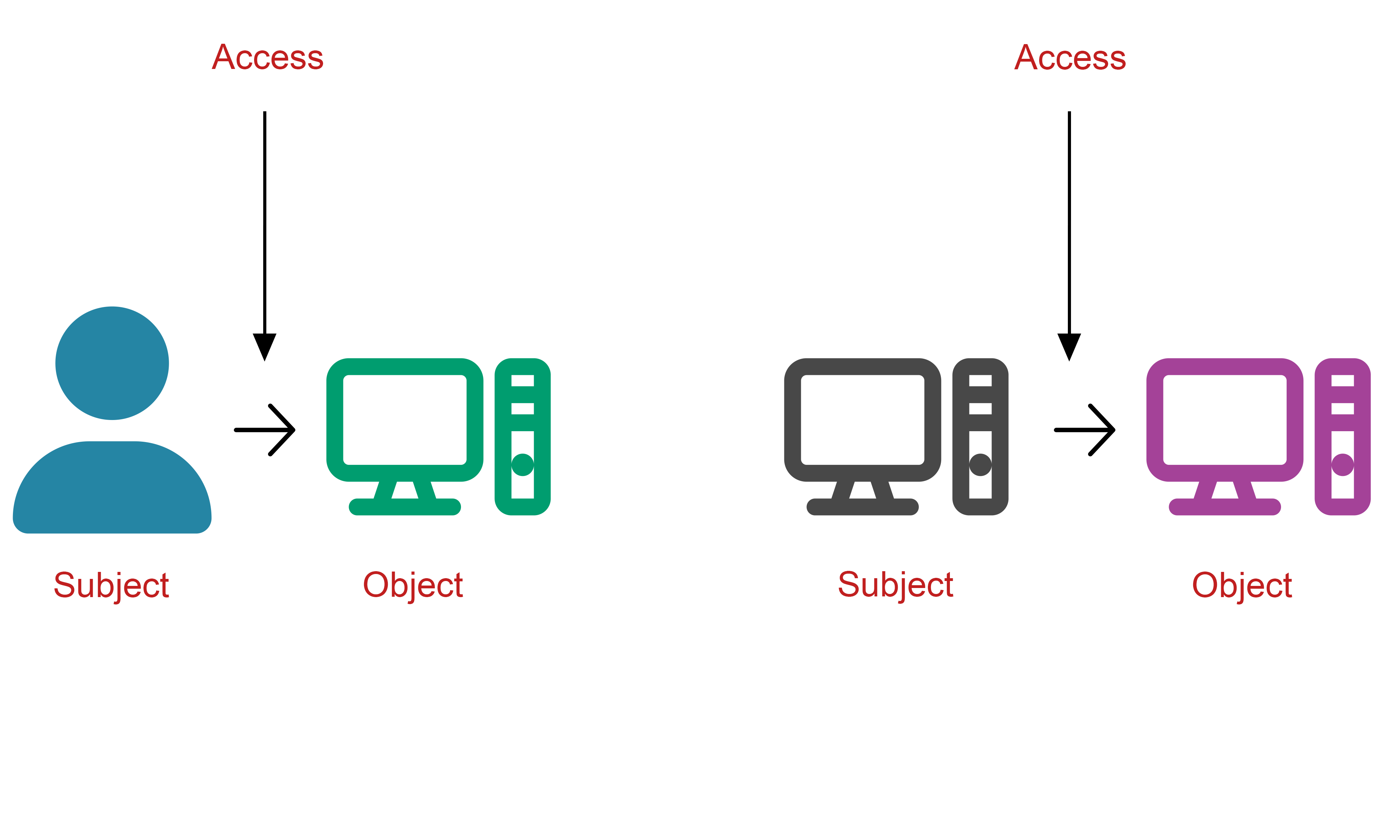
It would be possible to define trust relationships in a colossal 3D matrix such that every single atomic item of data (each object) has a defined trust relationship for each access type (create, update, access, delete) by every single potential requesting subject. However, even a relatively small set of subjects and objects would quickly become impossible to manage using this approach as it scaled.
Instead, it is more typical to assign like objects into groups or “bins.” This can be performed logically by placing “like with like,” for example defining a data classification system and grouping all “sensitive” items in one resource sphere. Alternatively, a simple self-defining “bin” or resource sphere is simply a given IT system or service which manages its own data. Within each such zone, however it is defined, the contained components trust each other and are not required to question each other’s integrity.
Each bin or each resource sphere has an edge or surface that represents its trust boundary. The trust boundary is a watershed representing a boundary such that, on either side of it, data (and subjects) have differing (or discretely) defined levels of trust. Any boundary where data may flow or be passed between two different resource spheres (such as two different systems) is typically a trust boundary. Unlike items within a resource sphere, trust is not assumed, and each trust boundary represents an attack surface: trust relationships between different resource spheres have to be explicitly defined one way or another.
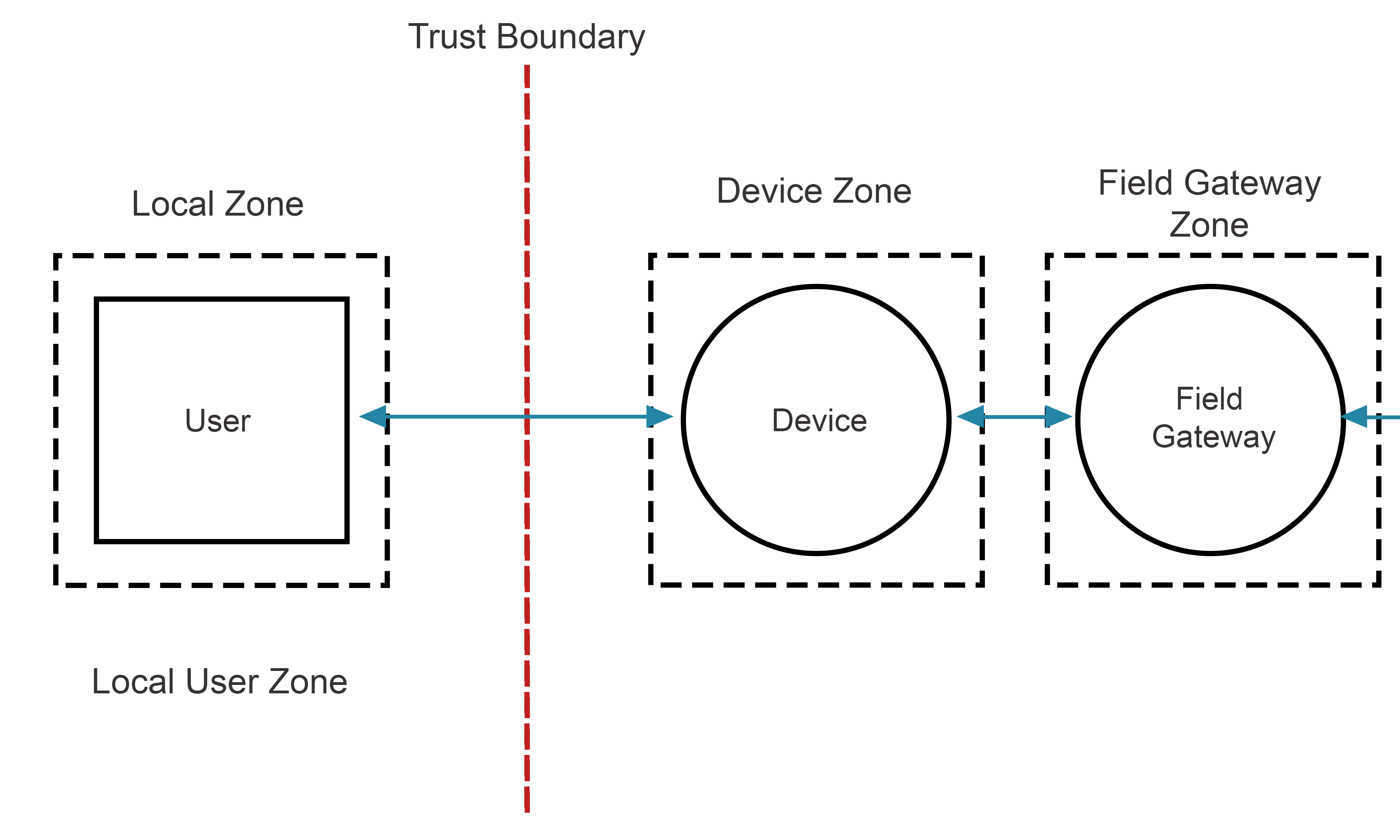
Even if the terminology is new to you, the concept of resource spheres and trust boundaries will almost certainly be familiar and intuitive. We understand that we put locks on the front doors of our houses or office buildings, but not on every internal door within them, for example, or that we have to enter a password to log on to our computer, but not re-enter it every time we perform a different action whilst using it.
Within cybersecurity, trust boundaries are used within areas such as threat modelling, where the trust boundaries (and data flows across these boundaries) of a given network, system, application, or service are explicitly mapped out in order to identify specific threats to the resource. The concept of the trust boundary can be used to direct consideration to specific points within logical data flows where access control of some form may be required in order to restrict access to the resource to trusted subjects only so as to protect it from harm.
Resource spheres can be defined upon various boundaries, such as the type of environment (production or staging), the data sensitivity, the application type of the tier/role of the systems in question.
A nearly universal example of trust boundaries is the case of the basic separation of the public internet from the internal corporate network at the physical and logical levels using a firewall and router. In a very simple configuration, traffic within the internal network may transit freely across the network, but traffic sourced from the public internet is restricted or prevented from entering the network. This trust boundary is typically referred to as the network perimeter.
More broadly, network segmentation as a technique within computer networking involves splitting a computer network into multiple subnetworks, each being termed a network segment. The aim of such segmentation or zoning is to prevent an attacker from gaining unauthorized access to a network or else limiting further movement across the network in the event that a single system is compromised in what are known as lateral or pivot attacks. It relies on defining and enforcing an access control policy on who and what is permitted to cross the trust boundary between defined zones. One common example that is relatively simple to implement is to define network zones (and hence trust boundaries) based on the so-called three-tier architecture commonly used within web applications, splitting web servers, databases servers and application servers (as well as end-user devices) each into their own segment.
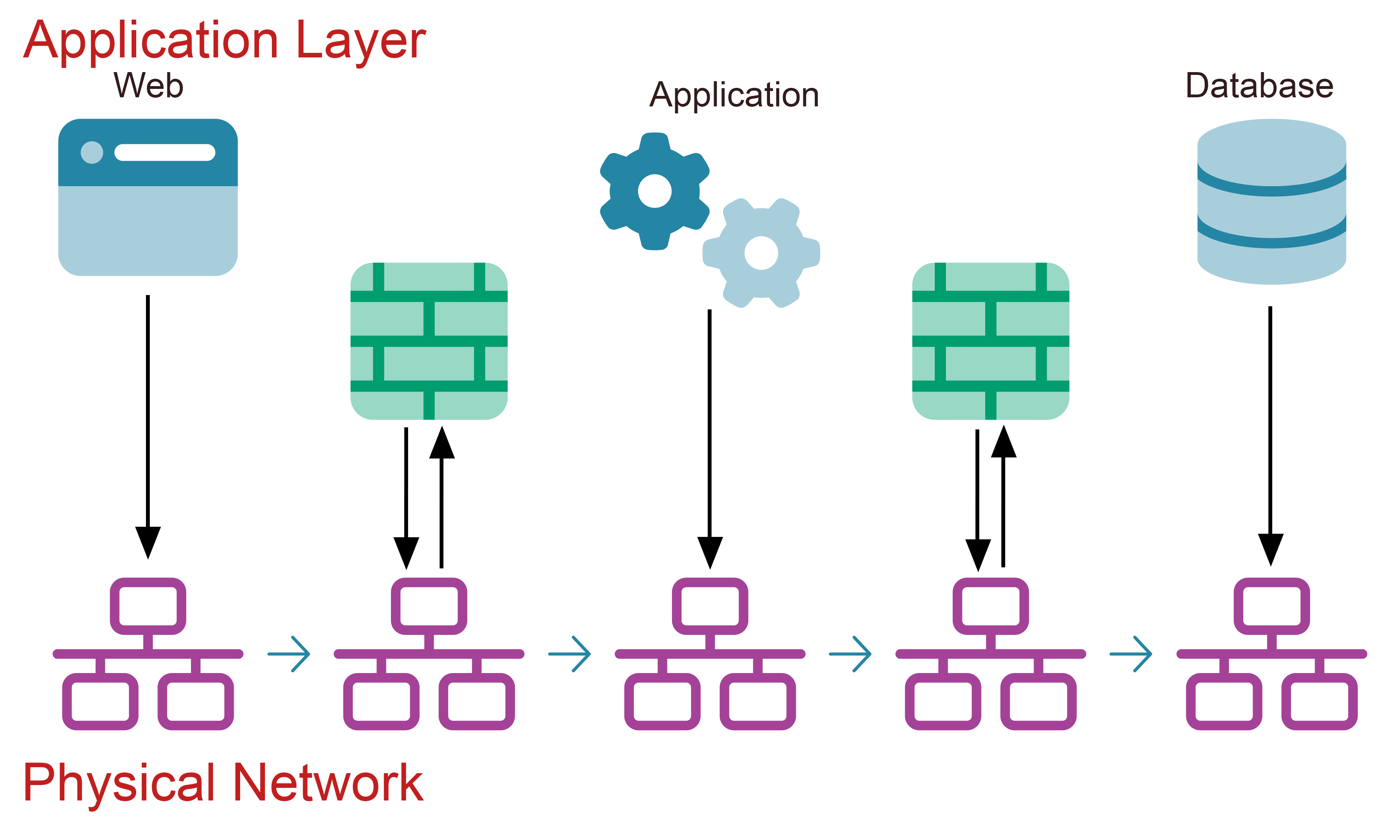
However, far from just restricting movement by attackers, effective use of trust zones with enforced access control across trust boundaries can also be used to provide granular definitions of trust between multiple groups of authorised users. By creating network segments containing only resources specific to given users, you can create an environment that is based on the security principle of least privilege: the idea that each user should have access to only those resources required to perform their role, and no further. The use of trust zones and trust boundaries within networking is sometimes termed an overlay network in which logical access control effectively splits a network that is physically and logically connected at lower layers of the network stack.
More advanced and highly specific trust configurations are possible by defining trust zones not on the basis of network segments containing groups of similar assets, but by decisions taken about traffic at the application layer. So-called micro-segmentation involves defining data flows known as workloads and using these to apply an overlay of a defined zone to all system elements used within that workload, even if discrete elements exist within different segments at the network layer. Micro-segmentation therefore uses the same underlying principles of trust boundaries but applies them in a far more granular level that is able to reflect real-world access requirements. This precision can take substantial investment in time to accurately model and requires a highly detailed understanding of application dependencies and data flows within a given environment. However, it permits highly sophisticated detection of malicious behaviour, and more rapid remediation if detected.
Micro-segmentation can further be extended to apply what is known as a zero-trust security model (also known as Zero Trust Network Architecture or ZTNA or perimeter-less security). This involves an approach of “always verify”: any access request from a subject to a given object is untrusted (denied) by default, even if they are connected to a permissioned network at an underlying layer. In contrast to a traditional network, where simply plugging in an ethernet cable is often good enough to get you up and running, on a zero-trust network you would be physically connected, but unable to access any services whatsoever until both you (and your device) were granted access (provisioned).
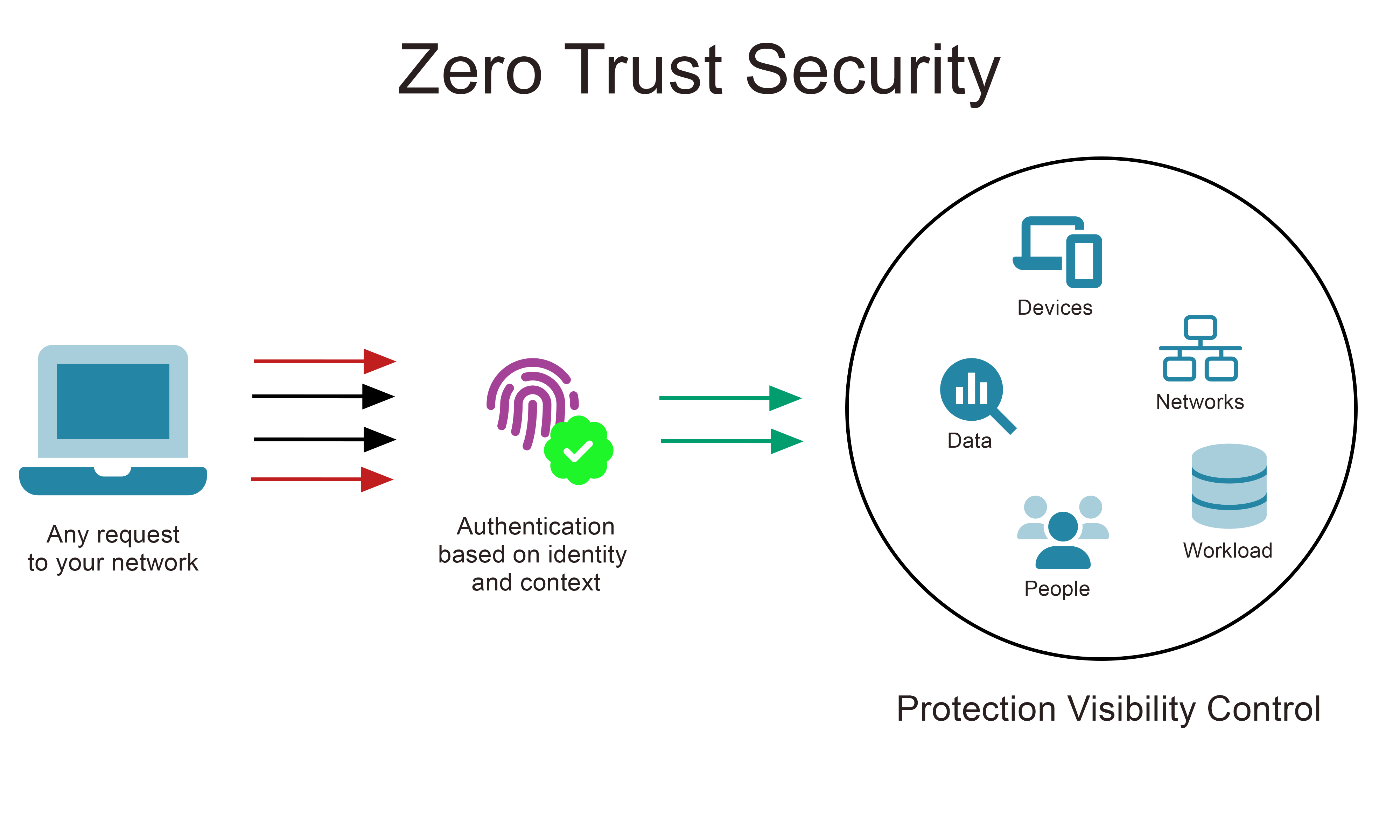
Trust boundaries rely on an assessment as to whether the subject is trusted to access the object in question. Different access control models can be used, but they all rely on an underlying mechanism that is used to provide identity verification (proof of claimed identity) via authentication. They may also in some system-to-system access control involve policy compliance assessment in which the subject device has to meet requirements such as “health” (e.g., being fully up to date with patches and screened by antivirus controls) before being granted access.
Trust boundaries are a principle or concept only, rather than a prescriptive measure that can be applied. However, defining trust boundaries can be performed within more general modelling or mapping of an organisational network or environment. This is incredibly useful to use as the basis for either formal threat modelling in order to manage risk most appropriately, or simply to highlight existing vulnerabilities in the form of control gaps and excessively broad attack surfaces.
Trust boundaries can be most simply implemented initially on the basis of simple network segmentation. A common simple example is ensuring that wireless access points are connected to a discrete network segment separate from wired corporate network segments. Another simple starting point for implementing basic trust boundaries is separating data centre networks along the lines of the three-tier architecture model, in which web, application and database servers are placed on different network segments, with access control applied across the network boundaries via firewalling: this can help to restrict attacker access to databases in the event that a web server (which is more directly exposed to threat) is compromised, for example.
Whether you choose to apply measures such as network segmentation or formal threat modelling, knowledge of trust boundaries remains a useful concept to keep in mind in any considerations of security questions.
AppCheck can help you with providing assurance in your entire organisation’s security footprint, by detecting vulnerabilities and enabling organizations to remediate them before attackers are able to exploit them. AppCheck performs comprehensive checks for a massive range of web application and infrastructure vulnerabilities – including missing security patches, exposed network services and default or insecure authentication in place in infrastructure devices.
External vulnerability scanning secures the perimeter of your network from external threats, such as cyber criminals seeking to exploit or disrupt your internet facing infrastructure. Our state-of-the-art external vulnerability scanner can assist in strengthening and bolstering your external networks, which are most-prone to attack due to their ease of access.
The AppCheck Vulnerability Analysis Engine provides detailed rationale behind each finding including a custom narrative to explain the detection methodology, verbose technical detail, and proof of concept evidence through safe exploitation.
AppCheck is a software security vendor based in the UK, offering a leading security scanning platform that automates the discovery of security flaws within organisations websites, applications, network, and cloud infrastructure. AppCheck are authorized by the Common Vulnerabilities and Exposures (CVE) Program as a CVE Numbering Authority (CNA)
As always, if you require any more information on this topic or want to see what unexpected vulnerabilities AppCheck can pick up in your website and applications then please contact us: info@localhost