Open-Source Intelligence (OSINT) describes the practice of collecting data from publicly available sources, with the aim of collating, processing, and analysing it into curated data sets order that can be used to extract intelligence used to inform decision making. The process involves the initial gathering data from sources (potentially including publications, broadcast media, and Internet sources), through data selection and extraction, into informed processing and analysis. OSINT is a generic process that can be used by various actors: it can help governments to gather vital information to inform national security activities; but it can equally be used maliciously by threat actors on the Internet, to assist with a targeted attack against a commercial organisation.
This blog post aims to introduce a few of the key OSINT techniques, look at who makes use of OSINT, explore how OSINT can be used in the cyber security space to aid in the enumeration phase of a web application security assessment.
As with the military techniques on which they are modelled, cyber attacks (whether authorised penetration testing / vulnerability scanning activities, or unauthorised hacks by cybercriminals) are not executed randomly and devoid of context. Rather, the attack itself is typically the culminating point in a practiced sequence of steps that constitute a standard methodology or lifecycle of actions. Although the exact terminology and sequence can vary, most attacks begin with a sequence of phases involving planning, target selection, information gathering and reconnaissance which together are termed “intelligence” or “intelligence gathering”.
Intelligence refers collectively to the sequenced collection, categorisation, processing, and analysis of gathered data. There is a single continuum from raw “data”, through collated/bundled ”information”, to processed “intelligence”: “Data” are a typically large number of discrete individual observations, facts, statistics or records that are typically relatively raw in that they may contain outliers and errors; “Information” describes the collective bundling and bringing together of various data into a useful collection; and “intelligence” describes the processing of the information in such a way that it delivers a predictive narrative that enables decision-making, reasoning or calculation. There are a wide range of methods and techniques that can be employed to perform this process, but they all carry the same purpose, which is to collate raw data relating to a specific context and to then make reasoned deductions from it that enable targeted action.
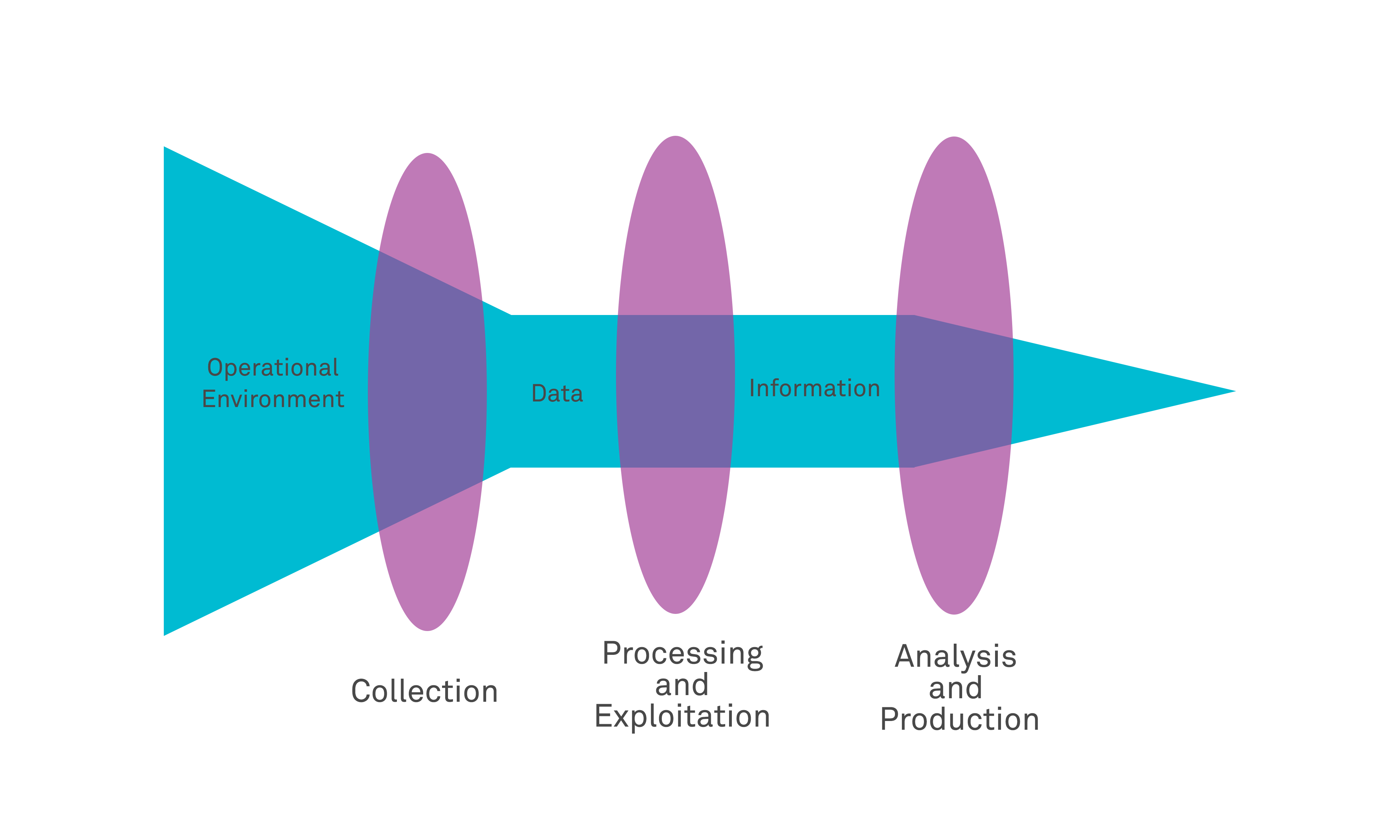
Intelligence within civilian, military intelligence agencies and law enforcement bodies is historically formed primarily from the combination of a collection of inputs from several intelligence gathering disciplines, such as HUMINT (human intelligence), IMINT (imagery intelligence), ELINT (electronic intelligence), SIGINT (Signals Intelligence).
OSINT is a portmanteau formed from “Open source” and “Intelligence”. “Open-Source” referred originally to a specific software development practice under which software or code was explicitly and deliberately made publicly available so that anyone is free to use, modify, and re-distribute it without being subject to any licensing restrictions by the original authors. The definition of open source has since evolved to include any data source that is publicly available for any party to access. Whilst this new definition is not limited solely to Internet-based data sources, for the purposes of this article and in the wider context of cyber security, “data source” will refer to data that is overtly, publicly, and freely available to access online.
If we are to talk about OSINT in the setting of the cyber security and information security world, then it refers to the creation of actionable intelligence derived from data sets that have been collected from public sources accessible via the Internet. It can also refer to the act of gathering data to produce actionable intelligence. Data sources used in this context can range within the entire cyberspace, from deliberately public information found in search engine results, through semi-public information on social media, to intentionally private information that has been published via data leaks.
Historical information, trust relationships and network information gathered through OSINT methods can provide powerful insights for both “white hat” security professionals and penetration testers as well as “black hat” cybercriminals and hackers into their targeted environments and applications. For example, major search engines such as Google and Bing regularly crawl and index websites and applications. If at some point in the past a web application component failed and returned verbose technical information as part of an HTTP response, or if a configuration file was exposed or a directory indexing returned its contents, a record of that returned content may be available even if the issue has since been remediated on the site or web application in question.
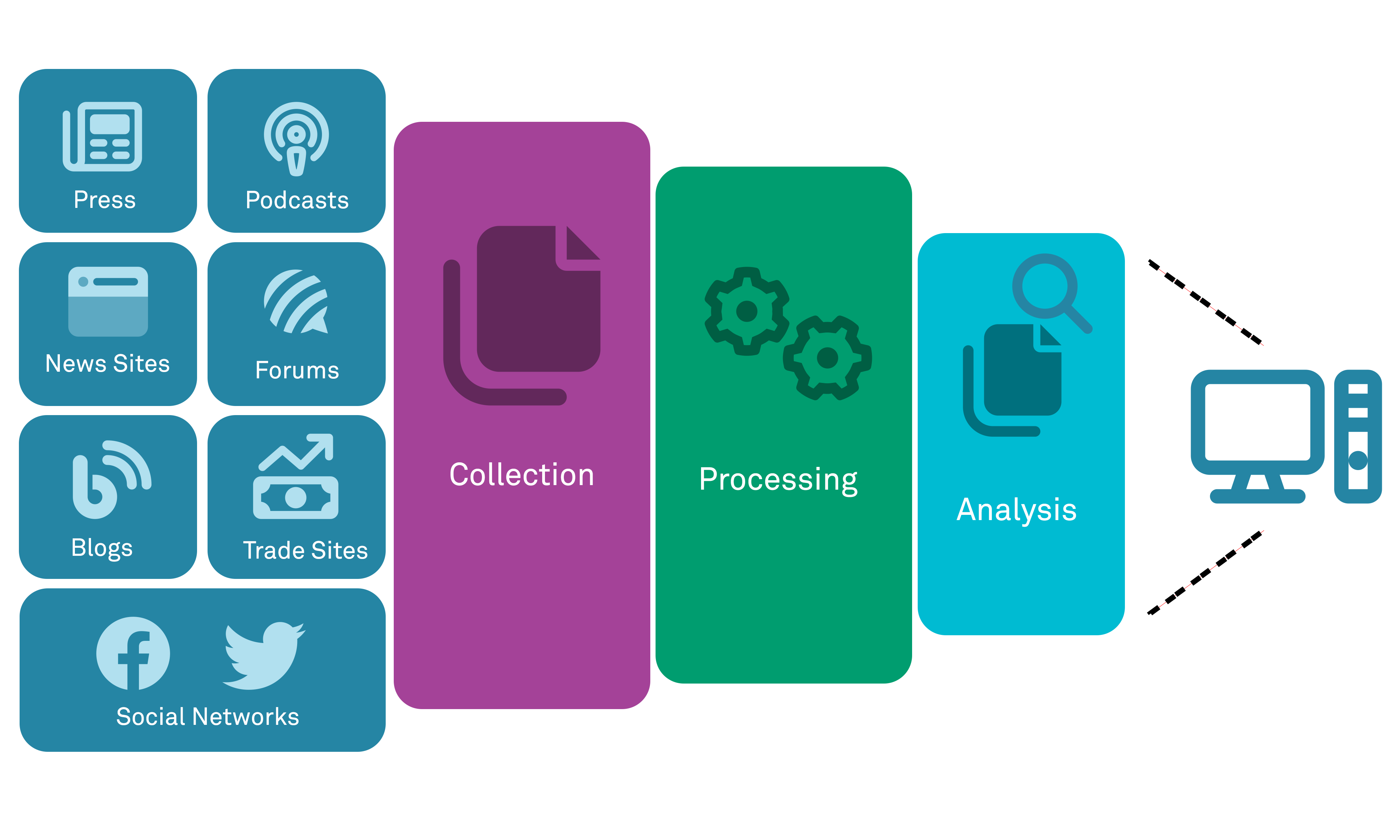
OSINT has been leveraged for a long time, even prior to the Internet, with the term first being used by the United States Central Intelligence Agency (CIA) in the early 1980s. However, arguably the concept (if not the exact term) is much older than this, being used throughout history in realms such as journalism and espionage. The modern use of OSINT gained significant momentum however with the rise of the digital domain for information storage, and the boom of social media that led to dramatic increases in the amount of personal information freely available online.
Intelligence gathering is an invaluable asset to any organisation, but it is possible categorise three main groups who utilise these techniques:
Intelligence gathering arguably originated within national governments and their agents and agencies, and governments and law enforcement bodies typically remain the largest consumer of open-source intelligence. The use of intelligence can be vital for a country’s national security, with uses in counterterrorism, the military targeted operations, and domestic and foreign policy decisions.
The full extent of the capabilities and techniques employed by such groups is something that is typically not available to the public domain. However, in 2013, the world got a look behind the curtain via Edward Snowden, a former United States National Security Agency (NSA) computer intelligence consultant. He leaked classified information that included details of global surveillance programs, including a range of OSINT techniques and tools.
Large enterprises and other businesses can use OSINT to investigate new markets, monitor competitors’ activities, avoid loss, plan marketing activities, and make informed business risk decisions. Businesses also use OSINT for defensive purposes in the cyber security space. Similar to the use cases identified in the following section, OSINT can help businesses create a threat intelligence strategy and in turn – when combined with information from internal data sources – formulate an effective cyber-risk management policy that helps them to protect their financial interests, reputation, and customer base.
OSINT is used extensively by so-called “black-hats” (criminals who break into computer networks with malicious intent) as well as their counterpart “white hats” (security professionals working in a contracted, regulated and authorised manner on behalf of an organisation) in order to gather intelligence prior to the start of an engagement against a target. Information gathered during this stage is vital to a successful attack. Both “black-hat” criminals and “white hat” security professionals use similar techniques for data gathering and information processing, with the major difference being the intended use for the intelligence produced.
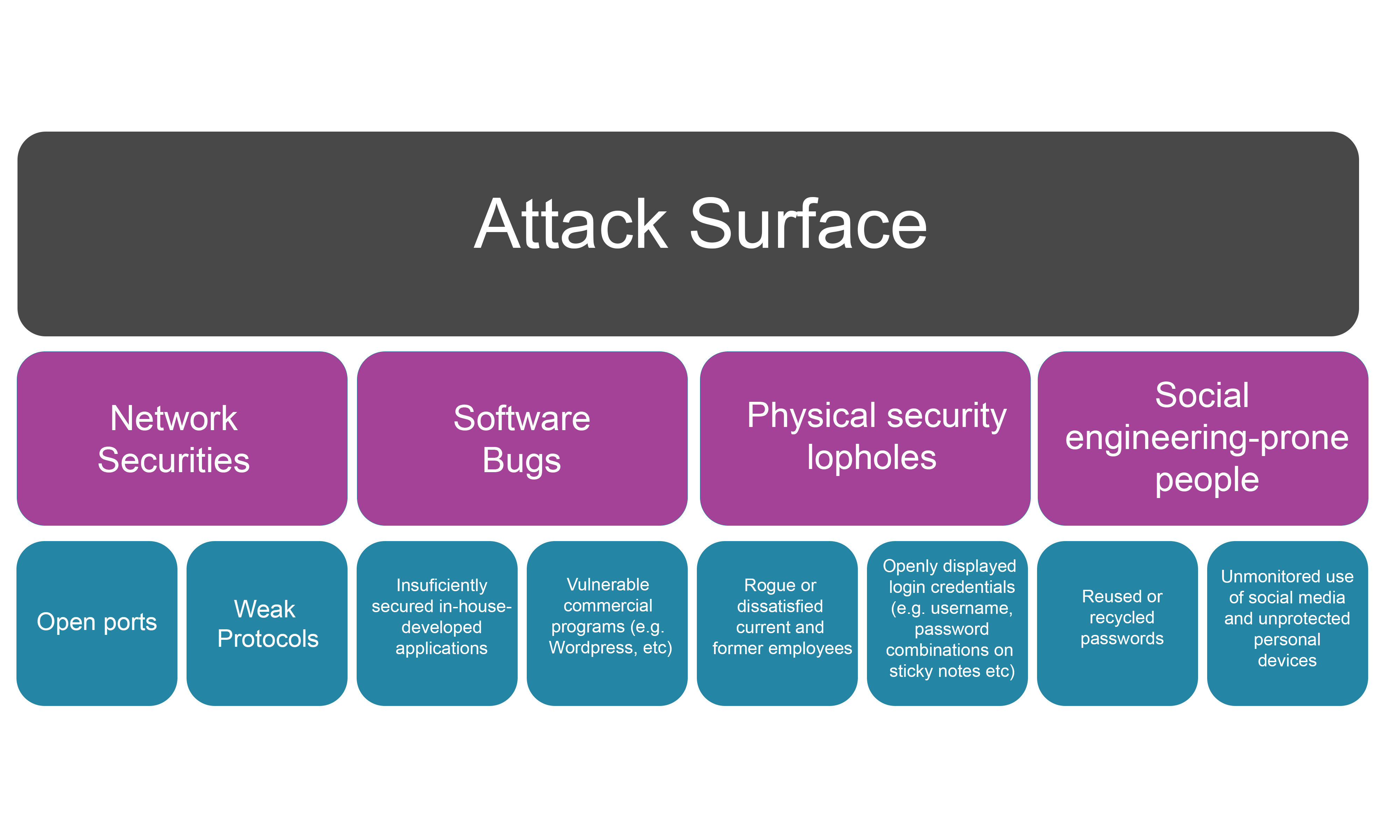
OSINT techniques are used by security professionals for threat intelligence gathering, allowing security teams to prevent or mitigate cyberattacks. OSINT may specifically be used to allow security teams to produce (or verify) the logical mapping of an organisation’s attack surface – the number of all possible points, or attack vectors (typically on the external infrastructure boundary of the organisation) where an unauthorized user can access a system and extract data via one or more potential attack vectors.
Techniques used may involve gathering information about a target’s domain name space; the details of who provides their DNS services; or IP address ranges along with any open ports or services which might be running. This data can is combined to map out a target’s attack surface, listing the technology in use or identifying where vital pieces of data are held within an organisation.
Whilst we often think of hackers directly attacking targets using the latest zero-day or exploit, which leverages novel and unexpected attack vectors, OSINT techniques can simplify the attack process by simply identifying existing vulnerable attack vectors.
In addition to “hard” technical attack vectors, it is important to realise that the softest point in an organisation’s security may be its employees and simply performing a search on a social media site such as LinkedIn could for example provide a list of email addresses for employees of a given organisation, which could enable an attacker to carry out a targeted spear phishing attack.
There is a range of freely accessible information online that can be found using traditional search engines and browsing of certain websites. The ad-hoc harvesting of data from these sources to produce collated data sets can be considered Open-Source intelligence gathering, but it is not that effective and lacks a structured methodology: the main issue with this technique is the amount of raw data that is presented to the investigator. Intelligence gathering is more effective if it is conducted in order to deliver on a clear goal and with a specific target defined in advance. The target and classification of information that an investigator is pursuing will dictate the requirements, methodology and tooling that is needed to filter through the mass of public data.
OSINT techniques can be split into two major categories that involve different types of contact with a target.

Often referred to as passive reconnaissance, this is the most used form of intelligence gathering. Passive data gathering is the act of collecting openly available data from a third-party data source such as a search engine or threat intelligence website. Typically, OSINT gathering methods use passive collection because the main aim of OSINT gathering is to collect information about the target via publicly available data sources without having to directly engage with a target. Passive reconnaissance allows any investigator to safely gather information without a need to directly converse with a target in a way that may warn the target that they are the focus of an attack or expose the attacker to detection.
An example of this approach may be using advanced searching on GitHub to discover source code for a given organisation and establish what technology stack is in use on their external web servers. No data is sent to the web server, but an investigator can proceed with crafting a list of potential attacks based off the information that was gathered.
The benefit of this approach is that it allows the investigator to swiftly gather data about a target and more importantly will never alert a target of an ongoing investigation. However, the disadvantage of this approach is that without careful processing and filtering of the data, it can result in a data set that is too broad and unfocused and overloads the investigator with data that is high in volume but low in quality: it can be plagued with false positives and misleading or inaccurate data outliers that undermine efforts to produce effective intelligence via analysis. This can be due to information not being up-to-date or the original data collection method used by a third-party being flawed at the time of collection. A significant amount of analysis is required to derive actional intelligence from the gathered data.
In comparison, active OSINT requires a level of interaction with the target in order to gather data. Unlike passive information gathering that relies on publicly available information, active OSINT gathering involves direct probing or communication (for example with employees via social engineering, or with a target’s infrastructure via active network probing). The gathering of data via these active measures comes at a higher risk to the attacker/investigator of detection by the target. It can however result in more highly focused, up-to-date and in-depth data than that available via purely passive techniques.
The main drawback of active reconnaissance is that direct interaction with the target and their infrastructure has a chance of detection, either my suspicious employees targeted by social engineering measures, or via active network probing leading to the triggering of any intrusion detection and preventions systems that the organisation may operate to screen its infrastructure. If the target of the investigator’s activities is alerted, the organisation may be able to prevent further active reconnaissance from taking place, or even hardening the target against attack if the detection of the attacker encourages the organisation’s own security team to investigate, discover and remediate any potential shortcomings in the security of the systems targeted by the attacker. Set against this, the advantages of active forms of reconnaissance can include the ability to gather more focused and higher quality data that produces superior intelligence and hence more informed and effective attack strategies.
OSINT data can be considered any data that is related to a target that can be found online. However, for further clarity some examples of commonly accessible information are listed below:
As OSINT is such a varied topic there is no end to the tools that have been produced to extract data from a wide range of sources. Below includes our list of resources which would be invaluable in carrying out a review of an organisation’s external attack surface- many of which have been adopted into the AppCheck vulnerability scanner.
It should be noted that this is not an exhaustive list and these resources could be used for other OSINT investigations outside of attack surface enumeration and asset discovery. If the reader is interested in what tools and resources are available online, they should check out the OSINT Framework – https://osintframework.com/. The OSINT Framework is a curated list of free tools and resources with the intention of helping people conducting OSINT investigations.
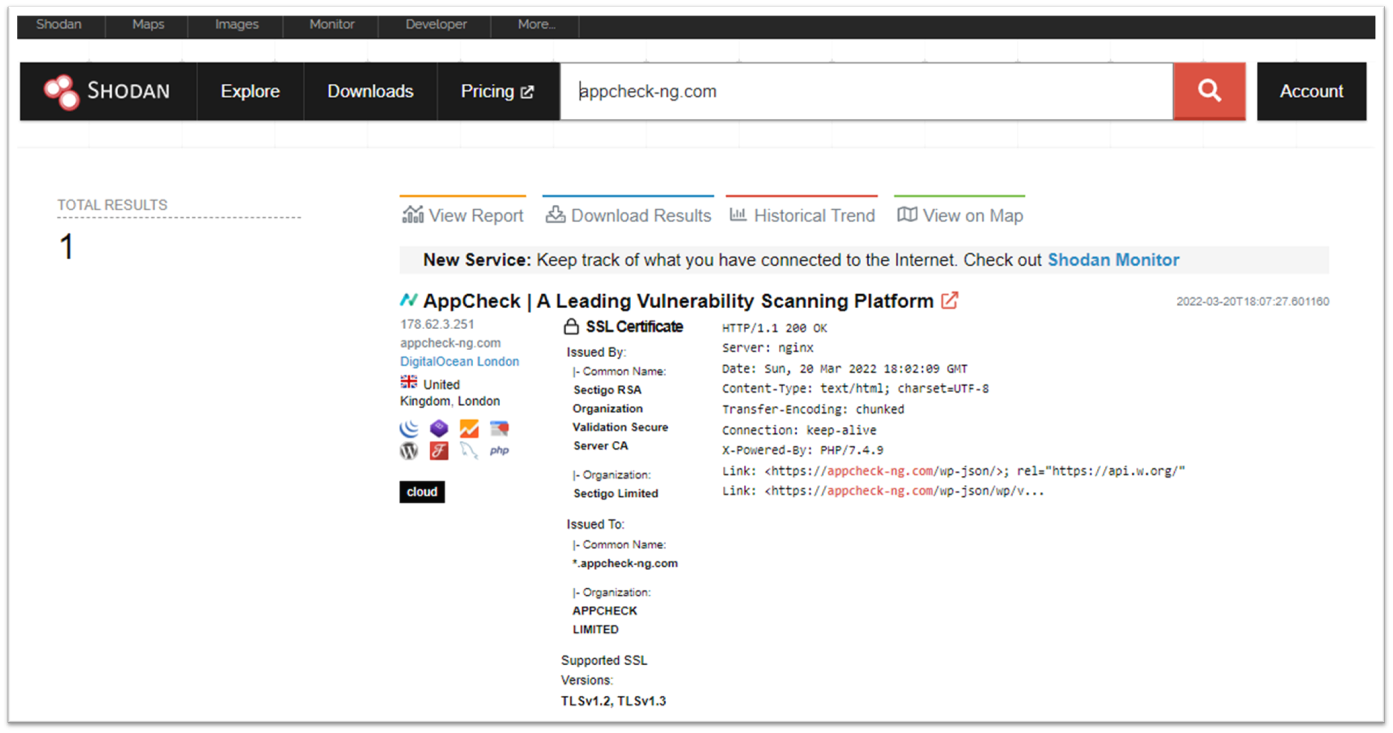
The below screenshot shows how effective passive OSINT gathering can be when using the Shodan security API and website. In a single query (using the AppCheck website as the example), without touching the target’s network, the operator has managed to discover an IP address indicating a hosting provider, open ports, which certificate authority signed the target SSL/TLS certificate, the full technology stack in use on the backend (along with versioning) and an approximate location of where the server is hosted.
The vulnerability scanning landscape has evolved in recent years to include OSINT techniques. The use of OSINT is key in identifying new websites, domains, or services. Reliance on the operator of the vulnerability scanner to insert the correct asset to scan can be flawed. Certainly, in the case of corporations with thousands of websites to their name, ensuring each website is scanned on a regular basis, along with maintaining an accurate list of sites to scan, can be an endless process which is likely plagued by inaccurate data and false positives.
Asset-orientated scanning, or threat monitoring (if you are coming from a Threat Intelligence background), is actively being introduced into the vulnerability assessment world. An asset can be classified as a domain, IP address or any online digital resource. Setting an asset as the source of a scan, which is followed by automated OSINT gathering has many advantages. This allows platforms to continually discover and monitor new assets related to an organisation. Instead of scanning a single site on a weekly basis, it is now possible to trigger relevant and timely scans based on changes to an asset, supply chain or new emerging threat. In the event a new exploit is released for a particular technology, automated vulnerability scanners are already aware (due to the OSINT data gathered) of the list of websites that are potentially affected, and a swift remediation plan with appropriate patching, can be formed.
AppCheck uses multiple OSINT data sources to gather information that can be seeded into the AppCheck web application vulnerability scanner and assessment process. This is conducted at the start of an assessment, during the discovery phase. The scanner consults multiple open-source intelligence databases to learn as much about the target system as possible. For example, hostnames registered to the target IP address, web components indexed by search engines, and historical network data. Data that is in scope for the scan is then seeded into the scan configuration.
Whilst our crawling engine does an excellent job of enumerating the visible attack surface, it can sometimes be the hidden components that are the Achilles’ heel. Temporary components such as micro-sites and marketing landing pages can become forgotten and unmaintained. These no-longer linked components may hide a critical security flaw and therefore it is important we test every component an attacker may target. AppCheck queries search engines such as Google and other online indexing services to gather a list of URLs both past and present to factor into the attack discovery phase.
The OSINT community is continually evolving and is expected to become a permanent fixture and widely accepted skillset in the infosec industry. The availability of open-source data sets and the rise of cyber threats are likely to increase the demand. As more public data sets are made available, we likely we will see artificial intelligence and machine learning being utilised for analysis. Soon we can expect OSINT to be utilised by many more organisations and individuals, with data harvesting likely becoming commonplace, be more prevalent and publicly accessible.
AppCheck is a software security vendor based in the UK, offering a leading security scanning platform that automates the discovery of security flaws within organisations websites, applications, network, and cloud infrastructure. AppCheck are authorized by the Common Vulnerabilities and Exposures (CVE) Program as a CVE Numbering Authority (CNA).
As always, if you require any more information on this topic or want to see what unexpected vulnerabilities AppCheck can pick up in your website and applications then please get in contact with us: info@localhost.