Customers new to the AppCheck platform can often be surprised at the number of vulnerabilities that AppCheck highlights relating to transport encryption offered on their services – unencrypted (plaintext) services, web applications with vulnerable cipher suites, encryption libraries containing exploitable flaws, registration forms that email users passwords in clear text. The list of checks that AppCheck performs is extensive, and on a website that has not previously been covered by regular vulnerability scanning, the extent of encryption issues can be surprising.
When organisations look to restrict access to data to authorised individuals only, the most commonly applied technical control is access control in the form of checks for identification, authentication and authorisation before access to the resource is granted. However, sometimes the data or resource has to reside on an unprotected medium such that access control cannot be guaranteed to restrict access, or else the credentials for access need to be sent over a network or other channel. Typically this can involve either:
1. the storage of the data on a medium such as a disk such that side-channel access (access other than through the planned access control methods) is possible in some circumstances; or
2. the transmission of the data across a medium that is judged to be insecure or to which access cannot be restricted, such as a network such as the open internet.
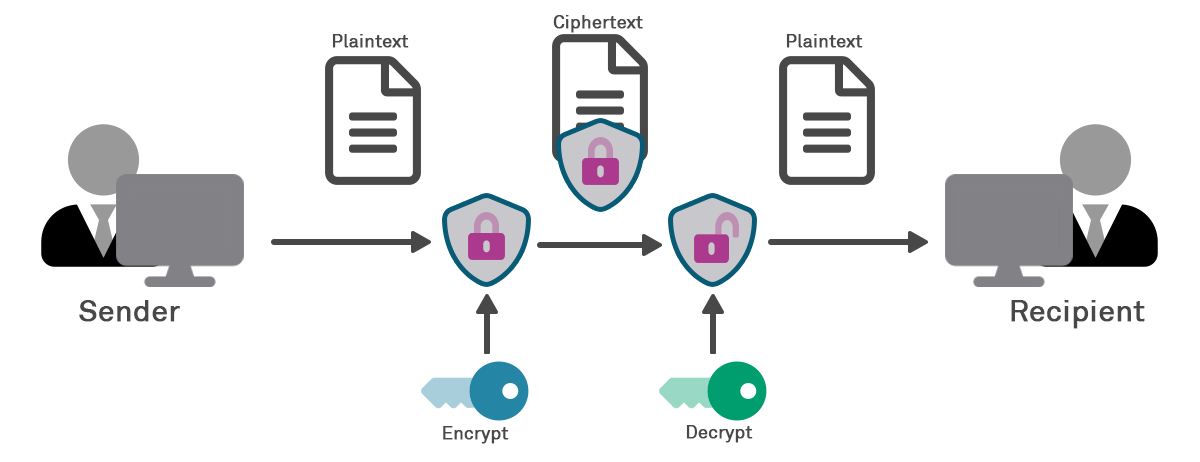
In these circumstances, it has become standard for organisations to use encryption – a transformation of the information or data such that:
1. The data is transformed from a random state via encoding into apparent nonsense that is unintelligible once encoded, known as ciphertext;
2. The unintelligible data form can be accessed by, but not comprehended by, unauthorised parties who may access or intercept it; and
3. The unintelligible data can be reverse-encoded or decoded back into a legible form by authorised parties, using a secret – typically a key.
Various forms of encryption have been developed over the last century to become established as a near-ubiquitous underpinning of guarantees of data confidentiality, integrity and authenticity. So far, so obvious. But in this article, we’ll look at what can go wrong with encryption and some of the common pitfalls that are seen in attempts to apply encryption to the protection of organisations’ data.
Organisations and teams will often deliberately consider the proposed use of encryption for an endpoint or service, only to reject the proposal – on the grounds that it is computationally expensive, or that the data is not sufficiently sensitive to warrant protection, or that the system in question is sufficiently screened by existing controls such as network segmentation. In our experience, this is a decision that almost universally comes to be a cause of regret. Systems that may start off containing only public data can morph and grow in scope over time. Data classifications and protection measures applied to specific systems and/or data sets when they are initially set up are not always re-reviewed periodically and decisions not to encrypt often no longer remains appropriate over time. Whilst there are exceptions, as a rule of thumb in almost every case, if you can encrypt – do.
An interesting variant of failing to encrypt a web service is when organisations do encrypt a web endpoint using HTTPS, but attackers are able to intercept traffic between clients and the web service, offering the service via HTTP to clients, and connecting to the back-end legitimate web service via HTTPS, using a Man In The Middle (MITM) attack. This can be prevented against for web services using the HSTS (Strict Transport Security) Policy – it allows web servers to declare that web browsers (or other complying user agents) should automatically interact with it using only HTTPS connections, which provide Transport Layer Security (TLS/SSL), unlike the insecure HTTP used alone.
The HSTS Policy is communicated by the server to the user agent via an HTTPS response header field named “Strict-Transport-Security” that specifies a period of time during which the user agent should only access the server in a secure fashion. Websites using HSTS often do not accept clear text HTTP, either by rejecting connections over HTTP or systematically redirecting users to HTTPS. The consequence of this is that a user-agent not capable of doing TLS will not be able to connect to the site.
Assuming that as an organisation we decide to encrypt our web service – next up we need to call our encryption function and assign a level of encryption using a standard library or configuration setting. In modern cryptographic systems and libraries, it is common to be offered a number of different ciphers – a range of standard algorithms for performing encryption or decryption – so that users can select the most appropriate for their purposes depending on desired level of security, speed of encryption, etc. For example, a system may permit an argument to be passed in to the function encrypt() to indicate the desired encryption cipher, such as AES:
encrypt(“my plaintext here”, “AES”);
Likewise, a web server such as Apache may contain a configuration directive specifying that SSL should be used (the below code is example only and may not be strictly accurate):
LoadModule ssl_module modules/mod_ssl.so
SSLCipherSuite ALL:!aNULL:RC4+RSA:+HIGH:+MEDIUM:+LOW:+EXP:+eNULL
SSLEngine on
Depending on the library used it is possible to select (either explicitly or implicitly) the null cipher, effectively calling an encryption function but choosing to make the ciphertext (encoded text) identical to the plaintext (original text), a “noop” transformation.
It is possible that either:
1. The null cipher might be the default or implicit cipher selected when an encryption function is called without a cipher passed in as a parameter; or
2. The null cipher may have been explicitly selected in application code for testing, debugging, or authentication-only communication but then left in the production release.
In both cases, it is possible to write code, or configure a webserver, such that it can appear as through encryption is implemented, and hence data being encrypted, when in fact it is not.
Assuming we’ve managed to avoid the pitfalls of not implementing encryption at all, and implementing encryption with a null cipher, then we’re calling a cryptographic function or algorithm of some sort, and our encrypted data (ciphertext) looks different to our plaintext. But have we chosen the right type of algorithm, known as a cryptographic primitive? There is remarkably frequent confusion as to when it is appropriate to use a hashing cryptographic primitive and when it is appropriate to use an encrypting cryptographic primitive. This error specifically occurs most often relating to the storage of passwords at rest (rather than encryption of data for transmission).
The key difference between hashing and encryption is that encryption produces a ciphertext that is recoverable into the original plaintext via decryption; whereas cryptographic hashing produces a hash or message digest using a one-way function, and the plaintext cannot be recovered.
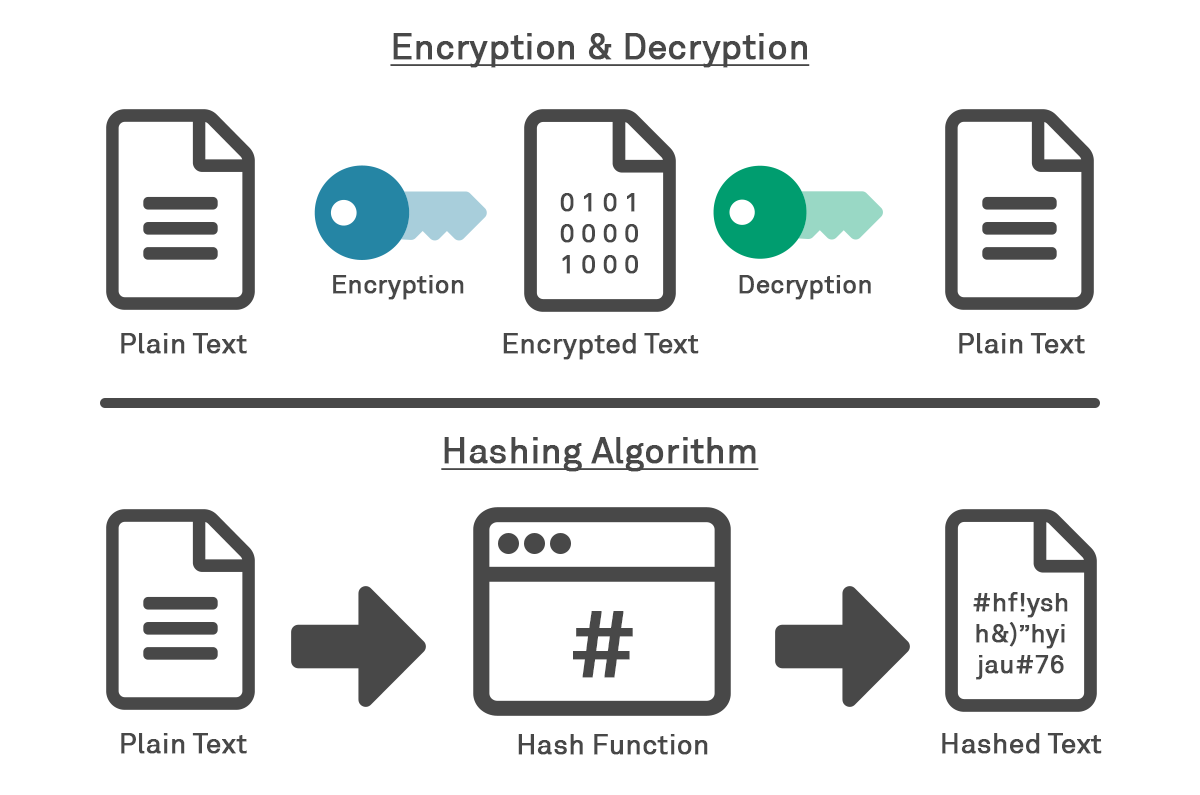
If you get the wrong type then:
1. In the case where you meant to select a hashing algorithm for storing a password but you selected an encryption algorithm, then anyone with access to the key can access your password, including both system administrators of the system in question and anyone who breaches the system; and
2. In the case where you meant to select an encryption algorithm for archiving data for later retrieval but you selected a hashing function instead, then your data is lost and cannot be recovered from its stored form.
Neither scenario is a great one to have to explain to your colleagues, line manager, customers or shareholders.
The next three errors in our list all relate to the selection of a suitable cryptographic algorithm and the errors in judgment that are possible during this selection. In the first instance, its possible to select an algorithm that is so inappropriate, naive or outdated that it has no place in modern cryptographic usage and provides only a naive “obfuscation” of the data rather than true encryption. That is, it produces ciphertext that can be trivially broken, sometimes even by someone with a bit of free time and a pen and paper.
Examples of such schemes include “ROT-13” (rotation-13), an unkeyed “algorithm” in which there is no secret key input. Because there is no secret key input, the transformation of plaintext into ciphertext is identical for each instance – that is, “a” always encrypts to “n”. In fact, under ROT-13 the encryption operation consists of a single round of simply replacing each letter by one 13 places further along in the alphabet. Another unkeyed example is the use of XOR addition with a null key – that is, simply “flipping” each bit in the plaintext to its opposite to generate the ciphertext: “101000” becomes “010111”.
If it seems far-fetched that organisations would use these techniques, there are documented instances logged as CVEs of companies doing exactly this to protect their sensitive data.
Although encryption does protect data from being read by unauthorized parties, the plaintext is nevertheless reversible or recoverable from the transmitted or stored ciphertext, by design. The cryptographic key held by authorized users makes this decryption operation fast for users in possession of the key, but decryption is still possible by an attacker without knowledge of the key who is able to invest significant time and resources into a brute force attack. In effect, attackers guess each successive key from the available key-space (the set of all possible keys), applying each in turn to the ciphertext, and seeing if any produces a likely candidate for the plaintext (i.e. a readable plaintext).
With a key-size of 64 bits, the key-space size for an example algorithm would be 2^64. That means that an attacker would have to calculate over 18 quintillion different keys to check the whole key-space, rising to 1.3 duodecillion for a 128bit key. Its going to take an attacker some considerable time. However, a legacy 16-bit key may only take 65,000 guesses to break, something that is absolutely trivial for a modern processor.
An example of an unsuitable aged algorithm is the Data Encryption Standard (DES) symmetric-key algorithm – its short key length of 56 bits makes it too insecure for modern applications. There are many other reasons why old algorithms are not as secure as modern ones besides key-space size, but in general “newer is better”.
The third possible mistake in selecting a cryptographic algorithm is to select an algorithm that is “broken”. An algorithm being “broken” has a specific meaning in that they were believed to be mathematically sound when published and introduced, but have since had one or more mathematical techniques discovered that can be used against them. These techniques are “shortcuts” that have been discovered to exploit weaknesses in the algorithm in order to provide an attacker with a method of calculating a key in a faster average time that it would take using the “brute force” approach of checking every possible key in the key-space.
One example is the so-called “Bar mitzvah attack” published against the RC4 cipher based on an “invariance weakness” in the algorithm . The weakness was published at a time when it was the most popular stream cipher in use in the world and led to a scramble to switch to alternative algorithms.
Sometimes the customer isn’t always right. Some services such as SSL/TLS negotiation offer a set of so-called “fallback options” for cipher selection. What this means is that the server publishes a list of its supported ciphers part of a connection handshake with a client, in order of most preferred to least preferred. The client compares this to its own supported ciphers and an agreement is reached. Negotiation is supposed to ensure that the most secure cipher that is mutually supported is selected. However if there is a misconfiguration or code bug, then this negotiation process may not select the strongest algorithm that is available to both parties, leading to an algorithm downgrade. This can permit attackers to more readily decrypt transmitted data during a Man In The Middle Attack.
OK, so we’ve remembered to encrypt our web service endpoint, we’ve ensured that we’ve selected a sound, modern algorithm, and we’ve disabled negotiation of older, weaker algorithms – or ensured that such downgrades are performed correctly. Are we all set? Not even close, unfortunately. The next few mistakes that can be made and which we’ll look at all involve the improper use of a perfectly sound algorithm, in a way that makes it insecure. Let’s take a look at the first type of “improper usage”:
Cryptographic algorithms will frequently us an initialization vector (IV) , nonce or starting variable (SV) as an input. These are used to provide variance, in other words to ensure that a plaintext “apple” does not always encrypt to the string “U8djj” when encrypted using a specific secret key since such static mappings can be used in cryptanalysis by an attacker to break ciphertext through techniques such as character frequency analysis.
It is important that this additional variable input is a secret and is not known to an attacker, in order for the generated ciphertext to be proofed against cryptanalysis that permits disclosure in part or full of the plaintext or information about it by an attacker. This is typically best assured that the initialisation vector is selected randomly. Where this is not done, partial or full access to the plaintext may be possible by an attacker analysing the transmitted ciphertext.
Even when we remember to provide an initialisation vector to our cryptographic algorithm, its still possible to do so insecurely in that the initialisation vector itself is guessable by an attacker. This can happen in a few different ways:
1. When the nonce (“number used once) is not in fact “used once” but continues to be re-used, perhaps indefinitely on a global or per-client basis;
2. When the “address space” of possible random values for the IV is too small (so an attacker can try each in turn); or
3. When the random entropy source provided to the algorithm for generation of random IVs is finite, becomes exhausted and so it has fallen back on less-random “pseudo-random” values that be more easily predicted by an attacker.
One variant of “IV reuse” is “key re-use”. When a key is repeatedly used to encrypt data, various weaknesses are introduced. Not least of these is that if an attacker is eventually able to crack a key, he will be able to decrypt and have access to every single message historically sent using that key which he has intercepted and recorded until he was able to crack the key.
Because of this danger, most keys used for data transmission are not actually encrypting keys but “key creation keys” or “key selection keys”, in that they are used solely to share a secret key between client and server to use for a short-lived communication. On the next connection from the same client, the key will not be used but a new session key created. This is known as “Perfect forward secrecy (PFS)” and means that an encryption system automatically and frequently changes the keys it uses to encrypt and decrypt information, such that if the latest key is compromised, it exposes only a small portion of the client’s sensitive data – historically transmitted data cannot be decrypted even if the latest key was broken since earlier keys would have been used to encrypt earlier data.
We’re starting to near the end of our list of encryption “gotchas” but there are still a few more ways to consider in which encryption can go wrong. The next is something that you’re unlikely to have considered if you’ve not studied cryptography in detail – randomness is essential to deliver secure encryption, but it is impossible for computers to generate since they are deterministic machines. That means that whenever a computer is initialised in the same way, it will behave in exactly the same way.
The impact of this is that in order to find a random number for use in encryption algorithm, a computer will generally need to “look outside itself”; that is it will need to rely on some kind of external source for random numbers, such as fan noise, atmospheric noise or radio waves. Unfortunately, in all these variants (and more) the external sources of randomness can be either observed as inputs, or – worse – influenced. So-called “side channel attacks” have been demonstrated in which attackers can influence the “random number” used as an input to the algorithm, and hence leverage this to predict and break the cipher.
Various techniques can be used to address this, including the use of an amplifier to boost the amplitude of fluctuations in the signal, high prevision measurements and the selection of least-significant decimal places in recorded values. For example, taking a reading of a frequency strength as
4.111894332
and then selecting the least significant digit – in this instance “2”. It would be incredibly hard for an attacker to influence or predict a signal input with this level of precision. More esoteric solutions include dedicated hardware Random Number Generators (RNGs) that physically connect to a computer system or network and generate randomness from sources as varied as radioactive decay, lava lamps, webcams with the dust-cap on the lens, and photon beam splitters making use of quantum effects.
Many of these techniques may not be practical for most organisations, but ensuring that a true-random data source is in place is definitely recommended.
A novel alternative to trying to decrypt the contents of a captured ciphertext via breaking the key using brute force or an algorithmic weakness is the cryptanalysis of its metadata, or “things known about the ciphertext”. For example, a message’s length is a form of metadata that can still leak sensitive information about the message. The well-known CRIME attack against HTTPS is a side-channel attack that relies on information leakage via the length of encrypted content.
In these attacks, an attacker looks for a system usage (such as cookies) in which a payload combines both a plaintext the contents of which are not known to them, along with a variable that is known to them. By altering the variable content and observing changes in the size of the compressed and encrypted ciphertext, an attacker can infer information about the secret plaintext. For example, when the size of the compressed content is reduced, it can be inferred that it is probable that some part of the injected content matches some part of the injected variable under the attacker’s control. Through trial and error, the plaintext can be recovered by repeating this process. Padding a message’s payload before encrypting it can help obscure the clear-text’s true length, at the cost of increasing the ciphertext’s size and introducing or increasing bandwidth overhead.
If an attacker is sufficiently motivated and resourced, and if the stakes are sufficiently high, then traffic analysis may be useful to an attacker, even where the encryption cannot be broken. Traffic analysis is a broad class of techniques that often employs message lengths to infer sensitive implementation about traffic flows by aggregating information about a large number of messages. That is, you can encrypt data, but you still have to send it, and an attack can observe who is sending how much data to who. An attacker observing that two companies were suddenly exchanging large volumes of encrypted data maybe able to infer, for example, that a corporate merger is about to occur, which they can leverage to their financial advantage. This is certainly a niche risk and unlikely to be of direct concern to most smaller organisations.
Even the best encryption system can be broken if keys are mis-managed. Rather than breaking encryption systems that are properly considered and implemented using strong algorithms, an attacker may instead seek to gain possession of a copy of the key, via bribery of a disaffected employee, compromise of the key management or storage system itself, or judicious use of a wrench.
We can’t help you against opponents armed with tools, utensils and the contents of a well-stocked mechanic’s cabinet. But we can help you with providing assurance in your web application’s security footprint. AppCheck performs comprehensive checks for a massive range of web application vulnerabilities from first principle to detect vulnerabilities – including cryptographic weaknesses – in in-house application code. AppCheck also draws on checks for known deserialisation exploits in vendor code from a large database of known and published CVEs. The AppCheck Vulnerability Analysis Engine provides detailed rationale behind each finding including a custom narrative to explain the detection methodology, verbose technical detail and proof of concept evidence through safe exploitation.
As always, if you require any more information on this topic or want to see what unexpected vulnerabilities AppCheck can pick up in your website and applications then please get in contact with us: info@localhost