HTTP Parameter Pollution occurs when a client sends multiple HTTP parameters with the same name to a web application server. Since an application can only accept one value for each parameter, it has to apply some logic as to what value to accept for the parameter in such a scenario. The presence of duplicated parameters may produce an anomalous or unexpected behaviour in an application if one element within the application or application stack resolves, collapses or interprets the multiple values into a final value differently than a second, downstream element does. HTTP parameter pollution does not always cause an issue on the server, especially if the webserver is static or operating a single-language/framework application stack. However, in more dynamic of complex web applications, parameter pollution is likely to produce application errors and inconsistent behaviour. These can lead to exploitable security vulnerabilities if the differential value interpretation can be leveraged by an attacker in a number of ways, including bypass input validation to permit injection attacks.
In this blog post, we investigate how and why HTTP parameter pollution is possible at all, how it can potentially be exploited to undermine web application security, and how it can be guarded against by developers, system architects and others.
In an HTTP transaction, clients (users) send requests to web application servers by sending requests for content. These requests contain several elements but foremost among them is the request URL (Uniform Resource Locator). The URL, more commonly known as a “web address,” specifies the location of a resource (such as a web page) on the internet. A URL consists of five primary parts: the scheme, subdomain, top-level domain, second-level domain, and subdirectory:
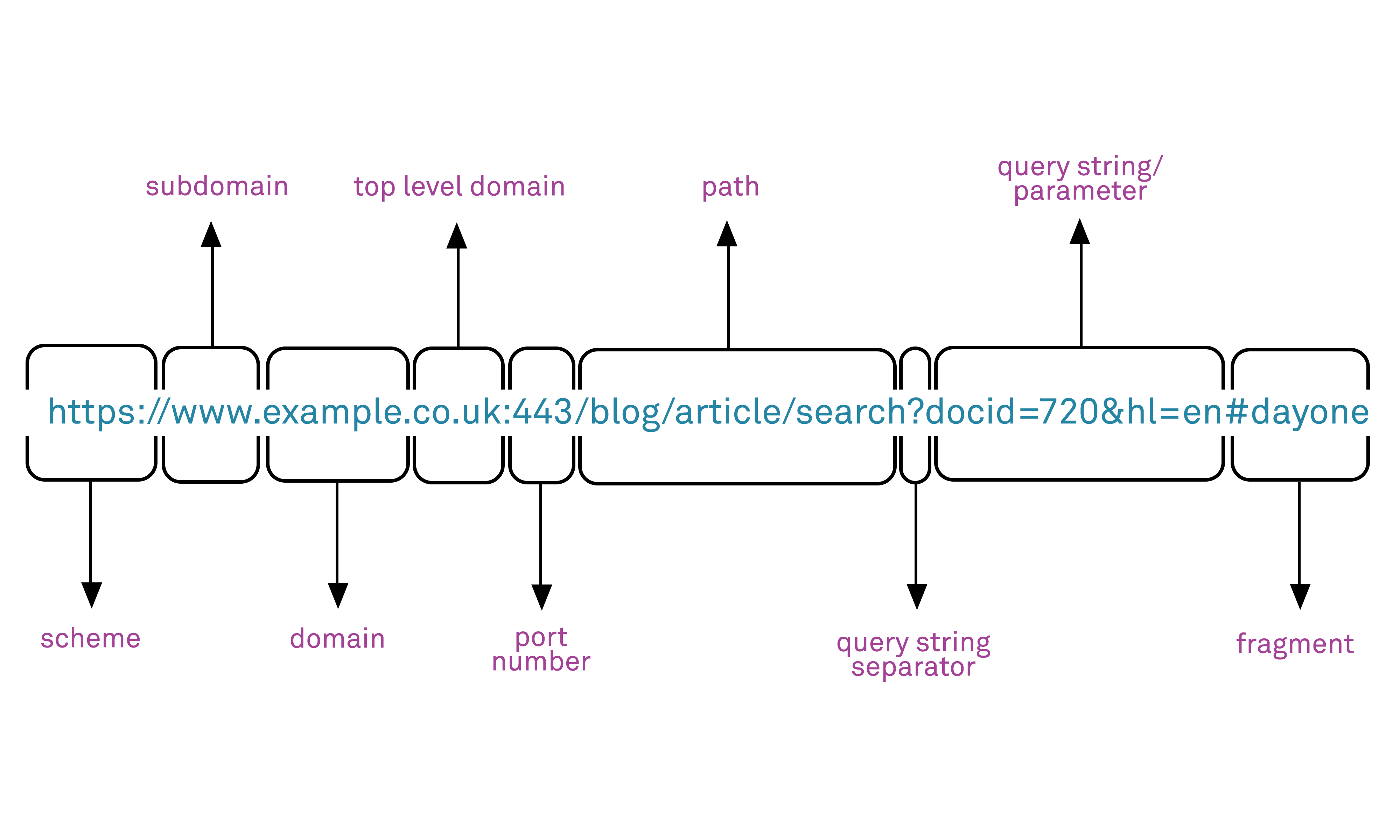
In addition to the URL, an HTTP request contains several other elements including an HTTP verb that defines the type of request that is being made, including GET, PUT, POST, DELETE and PATCH. The majority of web requests use either GET or POST methods.
A query string is optional in that not all HTTP requests will contain a query string. They are typically used to transmit dynamic data to the web server, such as the transmission of values entered by the client in an HTML form on a webpage.
In a GET request, the URL may include a query string/parameter separator followed by a value, in a “key-value pair”. Each query string is made up of a parameter and a value joined by the equals (=) sign. In case of multiple parameters, query strings are joined using the ampersand (“&”) or semicolon (“;”) signs:
?type=hat&color=blue
In an HTTP POST request, the parameters are communicated as POST variables stored as key-value pairs within the request body, but the principle is the same:
POST /path/file.php HTTP/1.0
Content-Type: application/x-www-form-urlencoded
Content-Length: 32
type=hat&colour=blue
The parameter can be a number, a plaintext string, an encrypted value, or any other form of data that can be represented as text within the given encoding scheme.
The behaviour and operation of various web technologies is outlined by the Internet Engineering Task Force (IETF) in a series of technical standards known as Requests for Comments (RFCs), intended to establish common standards that ensure consistent behaviour and inter-compatibility across products and technologies from competing vendors and products. However, in contrast to the approach taken by bodies such as the International Standards Organisation (ISO), RFC documents are not authored by formal bodies within the IETF but can be submitted by any IETF member. They are therefore published on an adhoc basis and subject to evolution, overlap and variable quality and detail over time.
The RFCs defining query strings, for example, suggests only that they are used for “non-hierarchical data” (RFC3986) and to provide a “string of information to be interpreted by the resource” (RFC2396), which is not terribly specific and has led to some common anti-patterns or ill-advised usages, such as their use in storing and transmitting session tokens.
A web server can handle a Hypertext Transfer Protocol (HTTP) request either by in the most native case simply reading (and returning to the requesting client) a file from its file system based on the URL path or – as in most modern web applications – by executing code to handle the request using logic that is specific to the type of resource. In this second case, the query string received by the web application will be available to that logic for use in its processing – parameters are typically used therefore not to designate the resource being acted upon (since the path portion of the URL is used for that) but to pass in some additional data to the web server to provide additional data, or context that suggests modification as to how the request should be processed.
Loosely speaking, these parameters may be described as either active or specific in that they modify the returned resource directly, or passive or general in that they provide some broader context or data unrelated to the specific resource in question and where the addition of the query string does not change the way the page is shown to the user.
An active parameter may be used in a dynamic web application for example to filter the content returned from a given resource – ?colour=blue for example might be used on the /hats path or resource within an e-commerce site to only return a list of blue hats.
In the passive or general case, the parameter may simply send additional data that provides some additional context or information for the server – one common usage is to append a unique string to the URL that permits tracking of the user for marketing purposes, permitting multiple HTTP requests to be associated with one another (in a similar way to HTTP cookies) across HTTP’s natural stateless protocol that executes individual requests without any link or association to prior requests:
<a href=”index.php?tracking=d0a43cf2a2b7″>click this link</a>
HTTP allows the submission of the same parameter more than once within a single HTTP request, yet the relevant RFCs do not explicitly state how multiple instances of the same parameter should be handled. This means that any submission of the same parameter more than once with the intent of achieving a specific malicious act, is considered to be HTTP parameter pollution – despite being permitted within the relevant standard (RFC) documents.
It may seem confusing at first as to why this behaviour would even be supported, but in our example:
?colour=blue&colour=red
Depending on the deployed application stack and how the application has been developed, the value of the parameter `colour` received on the sever side can be evaluated in different ways. If the application’s developer is not aware of the problem, the presence of duplicated parameters may change the application’s behaviour from its intended one and that can be potentially exploited as an attack vector by a malicious party.
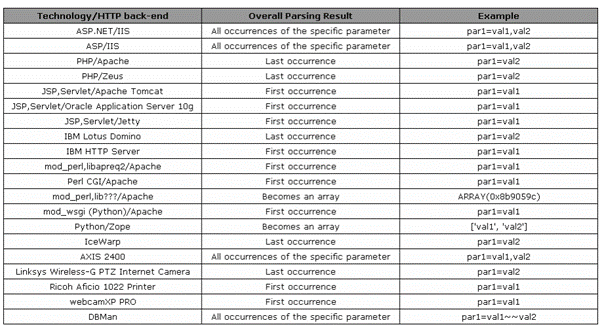
As stated above, HTTP allows the submission of the same parameter more than once. The behaviour of the query parameters will be defined by the technology stack on the receiving web server – they can either accept colour=blue&colour=red, colour=blue, red or both. Some web technologies parse the first or the last occurrence of the parameter, some concatenate all the inputs and others will create an array of parameters. The following table shows just some of the variety between languages, technologies, and frameworks:
By itself, HTTP parameter pollution is not inherently dangerous despite the name. It is turned into an exploitable vulnerability only when the receiving application stack contains multiple elements that evaluate the received query string independently and in turn, and each of which resolves and evaluates the multiple values for the parameter the query string differently to the other.
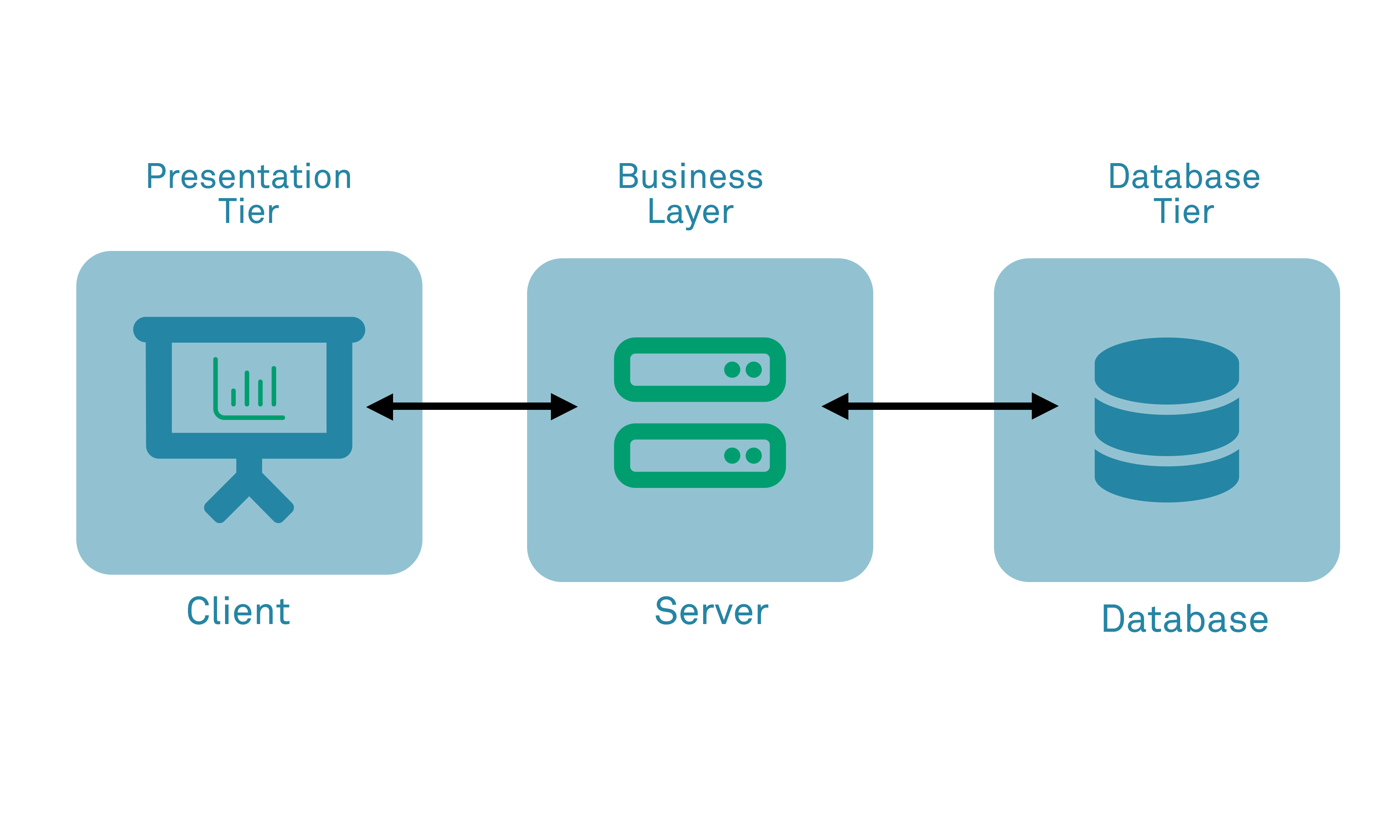
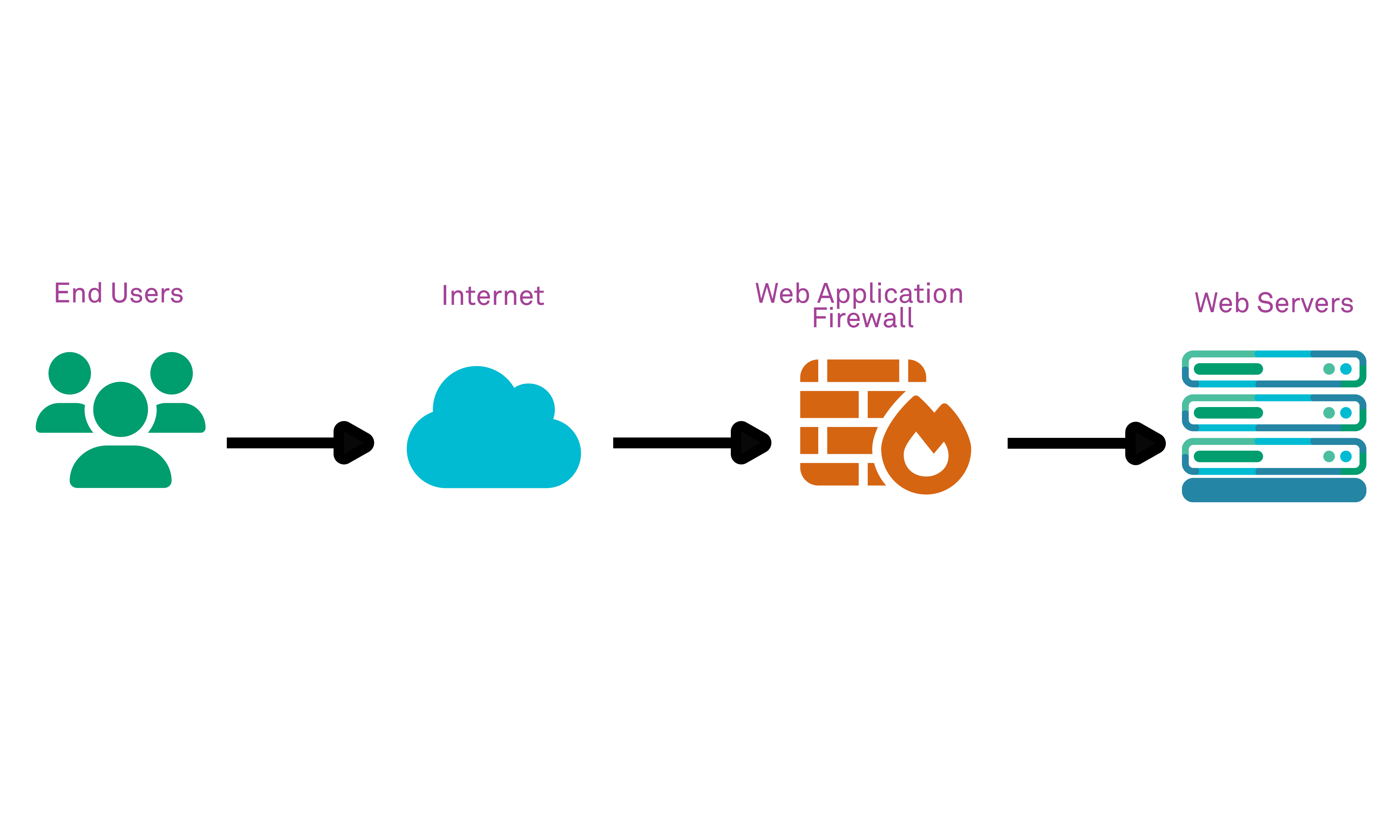
This typically occurs when a web application stack consists of multiple discrete components, such as in a tiered architecture, or when screened by a Web Application Firewall (WAF) that evaluates and parses the received URL in order to make a security decision on whether to permit or deny the request. In both cases, there must be multiple elements that evaluate a URL in turn, each applying its own logic:
Tiered web application:
Web application firewall (screened web application):
In both variants, an exploit relies upon “smuggling” a malicious parameter value into a downstream element of the stack: the first (typically benign) value of the parameter is evaluated by the first (upstream) components, and the second (malign) value skips evaluation or processing by this element, and is evaluated only once it reaches a second, screened element in the stack.
There are three primary ways in which this differential evaluation of parameters can potentially be exploited by a malicious attacker to modify the intended application behaviour in a malicious way not envisaged by the application developer:
In the first form, the attacker sends the same parameter twice with different values, both of which are individually benign or permitted, but one component within the stack evaluates the first value, and a second component evaluates the second. For example, imagine an online banking application sent the following path and query string to initiate a bank transfer:
/transfer?amount=1&amount=5000
In our theoretical example, the first value is evaluated by the logic controlling deduction of funds from the user’s own bank account, but due to being processed by a separate process running a different language and framework, the second value is used by a second part of the application to control the quantity deposited in a target account. By using highly divergent values, an attack could transfer £5000 into a second account that they own, at a “cost” of only £1 deducted from their first account.
The second variant depends upon the fact that some web applications are structured in a tiered manner often within that is called a service-oriented architecture: rather than have a single web application server receive, process and return responses, in order to process and serve a response to a request, data is sent between multiple internal servers in a chain in order to process the request and generate a response. The exact implementation varies but a typical conceptual model is based upon a 3-tier model with separate layers responsible for “presentation”, “business logic” and “data handling”.
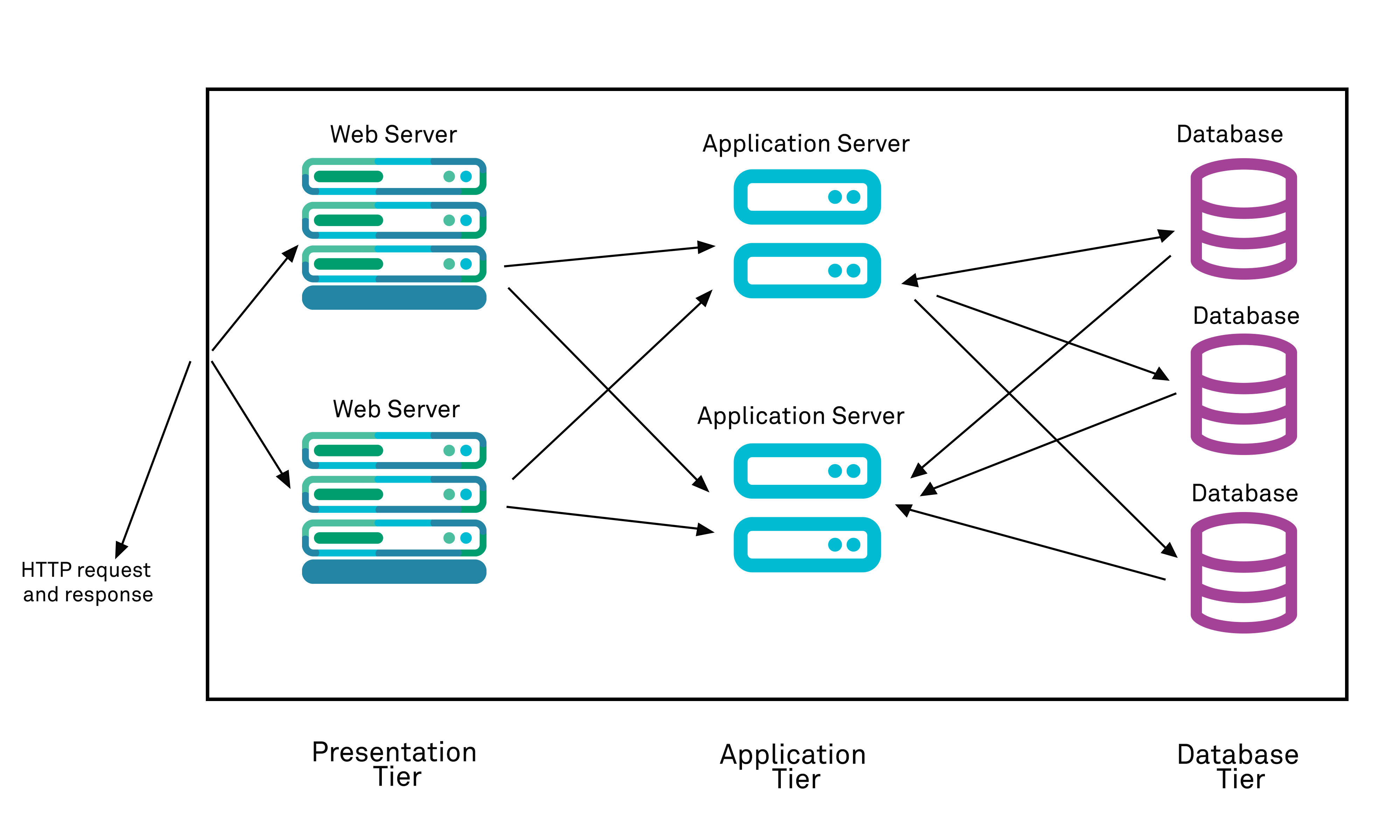
If we imagine that a request is received by an application stack such as this, then in some instances the web server tier may parse and evaluate a request received from a client, before making a blocking or in-line request to an application server further back in the stack. Critically, the web server may re-use or re-package the request parameters when making its own call to the application server, adding its own additional parameters.
For example, say that a customer sends a request to an online banking app to transfer £1000 to a recipient account “Attacker” that they operate with the query string:
?deposit=1000&recipient=Attacker
The web server may, in our theoretical example, append the “from” account to withdraw the funds from by appending the sender ID based upon the ID of the authenticated user sending the request, and then send this on to the backend application server for processing as so:
?deposit=1000&recipient=Attacker&sender=Attacker
The “sender” parameter is not intended to be present in the initial response from the client (since it is appended by the web server based on the authenticated session). An attacker may attempt to append the “sender” anyway in order for the funds to be sourced from the account of an uninvolved victim:
?deposit=1000&recipient=Attacker&sender=Victim
but finds that the web application server simply strips out the “sender” parameter if it receives it in a request. However, depending on the code, framework or language used, it may not be prepared for multiple instances of the parameter being present and strip only the first instance. An attacker could therefore send the following string to the webserver:
?deposit=1000&recipient=Attacker&sender=Victim&sender=Victim
and the webserver would strip the first instance of the “sender” parameter but include the second instance to the backend application server – the attacker has injected a parameter that should not be available to them for manipulation: in this instance, they can transfer money to themselves from a victim’s account.
In order to avoid injection attacks (in which an attacker sends special characters within an HTTP request – often within query string parameters – it is common practice for web applications to protect themselves by performing an evaluation of input data prior to parsing under business logic, in order to detect, remove or neutralize injected special characters, thwarting the attack. This logic can be performed either within the webserver code itself, within a third-party framework or library called by the code, or external and prior to the webserver entirely, on a dedicated layer-7 screening device such as a Web Application Firewall (WAF) or Application Delivery Controller (ADC). A given implementation may choose to either reject requests containing special characters, to filter out special characters, or to simply encode the data so special characters are rendered inactive when interpreted by the business logic.
However, as we have seen, when receiving multiple values for a parameter, different systems evaluate the multiple parameter values in different ways. This third form of HTTP parameter pollution exploit relies on this fact to send both a benign and a malign value payload: the first (benign) value is evaluated by the screening code or device, the request accepted as safe, and then passed on to a second, downstream element which evaluates the second (malign) parameter and falls victim to its injected payload. For example:
?colour=blue&colour=<script>/*+MALICIOUS_PAYLOAD+*/</script>
In a slightly more sophisticated variant, in which a system is known to concatenate the value of multiple parameter values which are the same (such as ASP.NET/IIS) then an attacker can split the malicious payload between the two (or more) values – since each parameter value contains only part of the payload (and potentially as little as a single character) it may bypass a screening security mechanism, with the payload only becoming complete and “active” when concatenated further downstream.
There are a number of methods that can be used to protect against HTTP parameter pollution. Rather than selecting just one, it is advised to ensure that all of them are used in concert.
In order to prevent against injection variants of HPP (and injection attacks in general), it is strongly advised to perform input validation on any data. Input validation can be either positive (allowing only characters listed on a given “allow list”) or negative (disallowing input from a “blacklist” of forbidden characters). In general, the positive form is safest, since it does not rely on ensuring that every single unsafe character possible is included, and it also permits further narrowing of permitted input to only that required by the given input element – for example a parser handling input for a phone number may only permit the numbers 0-9 and no other character. It is important in general (though not specific to HTTP parameter pollution attacks) to remember that all data passed in should be considered potentially unsafe – not only data received via direct HTTP request input, but data sourced from databases or other data sources.
If available within a given language, library, or framework, then it is recommended to use structured mechanisms that enforce the separation between data and command in a built-in and known-safe manner. These mechanisms can help to ensure that any unsafe characters are not evaluated as code (and hence permitting an injection attack) through a combination of either quoting or escaping. If a parameterized method is not available, it is possible to escape special characters explicitly within application code using the specific escape syntax for the language or interpreter in question.
In addition to performing input validation on any data received (in order to not fall victim to injection attacks), it is equally important for application code to ensure that it doesn’t inadvertently enable an injection attack by “poisoning” other functions or systems by sending them malicious data that they are unknowingly handling. This involves ensuring that data is always explicitly encoded into the appropriate safe format whenever it is passed across a language or interpretation boundary, such as when generating HTML content for output to a client in an HTTP response.
Canonicalisation (sometimes also called standardisation or normalisation) is the process of converting data that involves more than one representation into a standard-approved format. Within the context of HTTP parameter pollution, this means that your application stack should decide at a single point, and early on in the request processing, what value a given HTTP parameter has, rather than permitting it to be evaluated independently at different points in the application stack. This prevents the differential evaluation that allows HTTP parameter pollution attacks to be successful.
If using a WAF or multiple discrete devices or technologies within an application stack, then it is worth explicitly checking in the documentation how the device or technology in question handles processing multiple values for a single HTTP parameter and ensuring where possible that there is consistent interpretation throughout the stack.
In addition to functional testing, it is worth considering adding unit or integration tests within the application code to test how they handle unexpected edge cases, including receiving multiple values for a given parameter.
Finally, despite best efforts, some HTTP parameter pollution vulnerabilities may still be present in a given web application. Modern web applications are highly complex and involve multiple systems and components, using different devices and languages from different vendors. Although individual elements can be tested using unit or integration testing, some vulnerabilities may only be introduced (and hence visible) at the environmental level (i.e., within a production instance only) due to unique environmental configuration. A final line of defense, therefore, is to use a vulnerability scanner such as AppCheck to scan for and check a production instance of an application against HTTP parameter pollution and other vulnerabilities.
AppCheck helps you with providing assurance in your entire organisation’s security footprint. AppCheck performs comprehensive checks for a massive range of web application vulnerabilities – including injection vulnerabilities – from first principle to detect vulnerabilities in in-house application code.
The AppCheck web application vulnerability scanner has a full native understanding of web application logic, including Single Page Applications (SPAs), and renders and evaluates them in the exact same way as a user web browser does.
The AppCheck Vulnerability Analysis Engine provides detailed rationale behind each finding including a custom narrative to explain the detection methodology, verbose technical detail, and proof of concept evidence through safe exploitation.
AppCheck is a software security vendor based in the UK, offering a leading security scanning platform that automates the discovery of security flaws within organisations websites, applications, network, and cloud infrastructure. AppCheck are authorized by the Common Vulnerabilities and Exposures (CVE) Program as a CVE Numbering Authority (CNA).
As always, if you require any more information on this topic or want to see what unexpected vulnerabilities AppCheck can pick up in your website and applications then please get in contact with us: info@localhost