Deserialisation vulnerabilities were introduced to the OWASP Top 10 in 2017, nudging out Cross-Site Request Forgery (CSRF), based on the increasing prevalence and impact of deserialisation attacks reported in an industry survey. But what are deserialisation vulnerabilities, how do they occur, why did the threat from them suddenly increase in recent years, and what can be done to protect your organisation from this vulnerability?
In this article, we’ll do a deep dive into each of these areas. However while deserialisation vulnerabilities are often summed up with pat definitions such as “failure to sanitise objects during deserialisation where the objects have been extracted from user input” these explanations are somewhat circular and refer to the lack of a specific mitigation strategy in code rather than describing the vulnerability in a useful way. It is worth stepping through a general refresher on data handling that puts deserialisation vulnerabilities in context before we look into the vulnerability in detail.
It is possible to handle data as primitive data types such as integers and strings. A primitive data type specifies the size and type of variable values, and it has no additional methods. Primitive data types will typically have a one-to-one correspondence with objects in the computer’s memory, and computer instruction sets may even contain optimised instructions for handling these data types natively – they are about as “universal” as you can get.
Basic code may only need primitive data types such as strings (“john”) for operation. However often richer data structures are needed, in which data holds more contextual meaning. This can include both data types in which objectives have properties of their own that needs to be addressable and parseable, as well as richer object types that have their own methods.
For example, say that we wish to assign a property to john that can be uniquely assigned, queried and addressed – such as his hair colour. Strings do not permit this, which would be the correct form to describe john’s hair colour?
“john’s hair is red”
or
“john has red hair”
or even
“red is the colour of john’s hair”
All of these are valid strings, and can be parsed by humans, but are no use within computer code as a way or providing unambiguous reference.
The solution to this is the creation in coding languages of composite or non-primitive data types – either built-in types within the language (e.g an Array) or user-defined Objects/classes (e.g a “John”).
That is, “john” can be handled as an Object within the code – “john” can have attributes written to it and read from it, or actions performed on it:
john.hair.colour = “red” john.destroy()
This may all seem very obvious at this point, but bear with us – we’re going to look next at where serialisation enters the picture.
Complex modern computers systems are highly distributed and networked. As different physical or logical components communicate with each other inter-system or intra-system and share information (such as moving data between services, storing data, etc), the native binary format that is used internally within a language to represent these non-primitive objects becomes impossible since it is not uniformly interpreted or represented across different system and language boundaries – for example a PHP array or object or other complex data structure cannot be transported or stored or otherwise used outside of a running PHP script. The contents of Objects may however need to be transmitted across and supported by various technologies and services including:
• Remote- and inter-process communication (RPC/IPC);
• Wire protocols, web services, and message brokers;
• Caching/Persistence services; and
• Databases, cache servers, and file systems
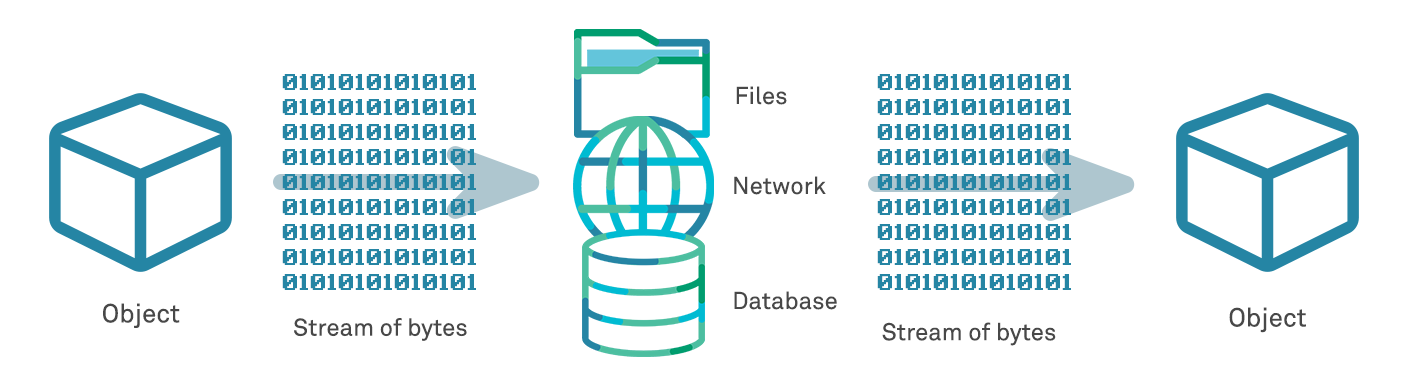
Since a language-native object (non-primitive) cannot be transferred directly between these different contexts, it therefore has to be converted into something else first. Essentially this involves translating the object structure into a “lower common denominator” that can be handled by systems and languages other than its source (native) language. The solution is a process known as serialisation.
Serialisation allows a language to covert a native object (a stream of bytes) into a primitive data type that can be understood natively by any receiving system. This typically involves the conversion of the object into a string (ASCII characters) or a binary format.
For example, our object “John” can be serialised by exhaustively extracting all its properties and listing them in a string formed of a structured data format representation, such as JSON (below), MessagePack, BSON, XML, or YAML:
{"john": { "age": "28", "height": "174", "hair": "red" }
Alternatively the same information is serialised Java to a largely non human readable binary format, which if base64 encoded appears as (it is useful to note that all serialised Java objects start with rO0 when base64 encoded, or ACED when hex encoded):
rO0ABXNyAARKb2huLQBtoeHfvhQCAANJAANhZ2VJAAZoZWlnaHRMAARoYWlydAASTGphdmEvbGFuZy9TdHJpbmc7eHAAAAAcAAAArnQAA3JlZA==
Or in PHP the same information is serialised as:
O:4:"John":3:{s:3:"age";i:28;s:6:"height";i:174;s:4:"hair";s:3:"red";}
This process may be referred to with a different name depending on the language, for example in PHP and Java it is “serialisation”, however in Python it is called “pickling” and in Ruby and Go it is called “marshalling”.
Deserialisation, in which vulnerabilities can be introduced, is simply the reverse process of the serialisation outlined above – that is, converting a serialised data string back into an object that can be manipulated, stored and acted on by the receiving application or system.
So what exactly can go wrong during this process? Where’s the risk?
When deserialisation occurs, a native Object is created. The ways in which this process can be exploited can take several different forms, so there are multiple attack angles that the hostile intruder can take. Lets take a look at five of the most common variants, and look at how the expected application behaviour can be subverted by an attacker.
The simplest form of attack that an attacker can perform is where they leave the submitted data structure unchanged from that the receiving application is expecting, but tamper with the content by simply changing some of the values. This can be as simple as changing one value for another in the serialised data. The actual exploit here can vary, but one trivial example may be if the receiving application fails to validate values, relying on client-side validation. In the event that an attacker submits the serialised input themselves directly using a command line tool, rather than making use of the official client, then the server may accept the data without question. For example, all an attacker would have to do is to see that the data submitted was in the form:
{"order": { "items": "1", "total": "9.98", "products": {"itemId": "12234","price": "9.98" }}
and to instead manually submit:
{"order": { "items": "1", "total": "0.01", "products": {"itemId": "12234","price": "9.98" }}
to receive their order for almost free.
Alternatively changing the data type of a value may result in unexpected evaluation, for examle PHP’s loose comparison (==) between strings and integers means that 9 is equal to “9 at the start of any string” and 0 is equal to “Any string without a leading number.” This behaviour may be unanticipated by the developer, particularly in combination with deserialisation, and allow the attacker to undermine the application.
A specific sub-case of the above is where the attacker is able to set a property in the submitted serialised data string which is considered to be a “trusted field” that is not designed to be set based on user input during object creation. A classic example is if an object has an “isAdmin” property.
If an attacker simply sets the value for “isAdmin” to true in the serialised data:
{"john": { "age": "28", "isAdmin": true}}
and the code faithfully represents this value in the created native Object during serialisation, then the attacker has successfully escalated their privileges on the target system. Most languages support a form of “masking” using the transient keyword or similar to indicate that a given property of an object should not be updated based on the user-provided input during deserialisation.
A third and slightly more obscure variation of untrusted input or injection attack during serialisation relies on the fact that Objects can have dependencies during their creation, and these dependencies can be injected, just as other properties of the Object can during deserialisation.
Dependency injection itself is not a vulnerability but rather a technique whereby one object supplies the dependencies of another object during its creation, such as a property that determines what service the Object will use. The “injection” refers to the passing of a dependency (a service) into the object. That is, rather than passing in a primitive such as a string as an object property, we pass in another Object or Class.
The potential exploit of this behaviour comes when a developer has not considered that that a malicious attacker may seek to replace the expected dependency with an unexpected one, or fails to validate that the Object injected is from a white-listed and trusted set. One often quoted example might be an “EncryptionAlgorithmInterface” on an Object – if the code defaults to and expects “AES256” to be used, but supports all valid options then an attacker can set the property to “None” in their submitted data, which the code faithfully uses to build an object that sends data in clear-text that an attacker can then potentially read since it is not protected.
Rather than submitting valid yet malicious input, an alternative is for the attacker to simply input data that is “out of context” for the receiving code – either outside the expected range, type, length for the property, seeking to exploit any weakness in the receiving deserialiser . For example, the attacker could attempt to set a property in the serialised data to a string of 10,000 “Z” characters, or a deeply recursive set of brace “{“ characters, to try and exploit weaknesses in the receiving service in how it responds to anomalous input. A receiving service may crash, run out of memory, or perform an unexpected operation in response to such input.
Depending on how the receiving service reacts, it could perform unexpected information disclosure back to the attacker in the form of error output, or even suffer an overflow attack, overwriting other data in memory or storage.
Perhaps the most serious variant however is the possibility remote code execution (RCE) on the receiving endpoint. The consequences are potentially more severe than other variants, and the underlying attack may be least likely to have been considered as possible by developers, and least protected against.
It is important to note that the expected serialised object can be replaced with one of a completely different class which will still be deserialised (hence this vulnerability is also known as “object injection”). This different class can be any of the massive number of deserialisable classes or methods which are supported by modern web applications either directly, from their dependencies or a library’s dependencies. Additionally a series of invocations of these classes can often be chained together, eventually deserialising in a manner that is beneficial to the attacker. Although the unexpected class may cause an exception in the application, by that point the deserialisation has occurred and the attack has likely already been successfully completed.
Unlike other vulnerability types, the attacker is not introducing classes or methods, they only pass data composed of serialised instances of objects available to the application, the chain of which when deserialised results in remote code execution. This “gadget chain” is made up of one or more of the classes and methods already available to the application, the first of which will automatically execute during the deserialisation process (e.g. a PHP object with a __wakeup() method or a Java object with a readObject() method), which starts the chain of calls which eventually leads to the last in the chain which is able to execute the arbitrary code or commands.
Deserialisation vulnerabilities are, largely, a case of “Welcome to the new boss, same as the old boss”. While the techniques and payloads are specific to serialised data transmission formats used in the massive growth of dynamic web applications and Single Page Applications (SPAs) for server communication, the fundamental vulnerabilities are conceptually similar to those seen in web applications for over a decade, relating to untrusted data handling. The risk is greater simply because of a lack of awareness among developers as to safe and best practices for handling data during deserialisation.
The risks are significant – injecting hostile serialised objects into a request can effectively get a server, as we have seen, to run malicious code that may in some cases allow the attacker to gain access to the webserver. A recent example of this vulnerability was the Apache Struts vulnerability (CVE-2017-9805) that led to the Equifax data breach involving the theft of records included personal data relating to approximately 12.3 million individuals, and which led to them facing up to $700million in regulatory fines.
So how best to protect yourself against deserialisation vulnerabilities? The following approaches can be combined to mitigate this vulnerability:
This is the most robust and only truly effective defence, particularly against the remote code execution variant.
In general, it is safer to make use of language-agnostic formats such as JSON as opposed to native binary formats, since these will generally have relatively “safe” methods for deserialisation provided in your chosen language, such as json_decode (PHP). This is not in itself a complete mitigation, but rather a best practice that builds on top of other mitigations included below.
As with all user-provided input, the potential exists for the input provided to be tampered with since it is under user control. Various checks can be performed on user input from “positive” tests such as permitting individual properties to be from within a permitted white-list only, to less effective “negative” tests that reject input that lies outside defined permitted types, ranges, bounds and limits.
Note that this method protects against logic flaws which may be exploited by malicious data, but does not protect against the remote code execution achieved during the deserialisation process.
This measure is not effective for client-server systems in which you need functionally for the user to be able to provide free-form input to your service. However, if you are sending a serialised object between two trusted systems that you control in a server-server fashion, or else want to send data to and store an object on a client for later retrieval and to ensure the object has not been modified then you can add functionality to perform an integrity check on received data. This is typically done using a checksum using a strongly collision-resistant hash function, or by making use of digital signature techniques.
A simple or Cyclic Redundancy Check is sufficient if the sole purpose is to detect accidental changes/errors in the payload introduced in communication channel, but as the attacker could set a valid value for their malicious input a more appropriate method is to append the output of a cyrptographic hash function known as a HMAC (Hash-Based Message Authentication Code) to the data payload as a “data tag” that is calculated from the payload values.
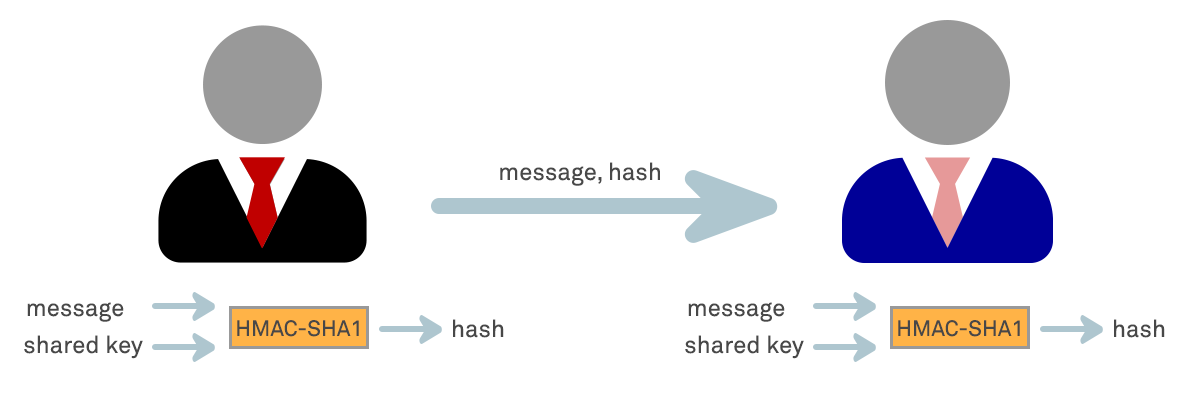
Under this protection measure, the sender of a message runs it through an HMAC algorithm such as SHA-256 to produce a HMAC data tag. The original message and the HMAC tag are then sent to the receiver. The receiver in turn runs the message portion of the transmission through the same HMAC algorithm using the same key, producing a second HMAC data tag. The receiver then compares the first MAC tag received in the transmission to the second generated MAC tag. If they are identical, the receiver can safely assume that the message was not altered or tampered with.
Payload without HMAC:
{"john": { "age": "28", "isAdmin": false}}
With HMAC:
{"john": { "age": "28", "isAdmin": false}, “hmac”: “4bcb287e284f8c21e87e14ba2dc40b16”}
It is critical that this validation is performed before the data is deserialised, since many deserialisation attacks occur during the deserialisation process itself.
In many languages the transient keyword or similar gives a developer some control over the serialisation process in that it permits the developer to mark some object properties to be excluded from population via user input at the time of object creation. If there are data members of an object that should never be controlled by end users during deserialisation or exposed to users during serialisation (such as the “isAdmin” property for a user), then they should be declared using the transient keyword or equivalent.
For example:
public class Foo implements Serializable
{
private String saveMe;
private transient String dontSaveMe;
private transient String password;
//...
}
If possible object specific serialisation methods should be implemented rather than relying on generic serialisation, this allows complete control of the properties are exposed to potentially malicious input.
Isolating and running code that deserialises data in a low privilege environment wherever possible ensures that if an attacker is successful in performing a code injection attack, that the impact is minimised.
AppCheck performs comprehensive checks for a massive range of web application vulnerabilities from first principle to detect vulnerability – including deserialisation vulnerabilities – in in-house application code. AppCheck also draws on checks for known deserialisation exploits in vendor code from a large database of known and published CVEs. The AppCheck Vulnerability Analysis Engine provides detailed rationale behind each finding including a custom narrative to explain the detection methodology, verbose technical detail and proof of concept evidence through safe exploitation.
As always, if you require any more information on this topic or want to see what unexpected vulnerabilities AppCheck can pick up in your website and applications then please get in touch.