In this guide, we’re exploring everything you need to know about single page applications (SPAs), including what they are, why they’re popular and the risks involved with using them.
Single page applications are single pages on which most information remains constant, while smaller pieces of data update to match user intent. For example, when checking your emails, the header and sidebar generally remain constant as you alter between your inbox, spam and sent folders. In this way, single page applications avoid sending unnecessary information to your browser and make load times much quicker.
Examples of single page applications include Netflix, PayPal, Google Maps, and Gmail.
Before we dive into a run-through of Single Page Applications, it is worth spending a moment just refreshing some basic concepts of the underlying principles that hold true for all web applications, whether single-page (SPA) or not. The information in this section is fairly basic so feel free to skip it if you are confident that you understand the technical underpinnings for web applications, or refer back to this section as needed later.
All web applications make use of the HTTP Protocol, which was originally published in v0.9 way back in 1991. It has been extended significantly in later versions but remains fundamentally unchanged in its basic operation.
HTTP operates according to a Request-Response model for the delivery of resources across a network. That is, a remote client (typically a user’s web browser) submits an HTTP request message to a server. The server, which contains data or resources that the client wishes to retrieve or access, performs some action internally (such as retrieving a resource from storage, or modifying and updating a file) and returns a response message to the client. The message may contain metadata only (such as an instruction to the client that the resource is unavailable or has moved) or a combination of metadata along with a returned resource, such as a file.
Requests are idempotent in that there is no expectation or necessity for either the client or server to store any information about the request after disconnection. Although there are mechanisms and techniques for both server and client to maintain internal state tracking trust relationships etc., this is again not a necessity for basic HTTP operation.
HTTP can be used for the transport of files of various types, both plain-text and binary. However, by far the most dominant usage ever since the early days of v0.9 of the protocol has been the use of HyperText Markup Language or HTML. HTML is used to describe the content of a single document, expressing – increasingly in concert with other resource types including scripts and markup languages such as CSS etc. – how that content should be ordered, displayed and formatted.
In HTML documents, tags define the start and end of elements such as headings, paragraphs, lists, character highlighting and links to other resources. Most HTML elements are identified in a document as a start tag, which gives the element name and attributes, followed by the content, followed by the end tag, for example:
<h1>This is a header</h1>
Since tags were originally designed to indicate element types (e.g “header”) rather than to indicate specific design or presentation intentions, it is possible when rendering a webpage for browsers to interpret tags with some subjectivity, which in the “browser wars” of the 1990s led to a need to standardise how elements were addressed and interpreted for display. The principle standardisation was handled by the World Wide Web Consortium (W3C) between 1998 and 2004, developing a recommendation in 2004 known as the Document Object Model (DOM) – a cross-platform and language-independent interface for HTML. Development of this standard has since been taken over by Web Hypertext Application Technology Working Group (WHATWG) which publishes it as a living standard, with W3C publishing stable snapshots of that standard.
The DOM treats an HTML document as a tree structure wherein each node is an object representing a part of the document. Each branch of the tree ends in a node, and each node contains objects. For example, given the following HTML code:
<TABLE> <ROWS> <TR> <TD>John</TD> <TD>Peter</TD> </TR> </ROWS> </TABLE>
then the following could be used to address or access the node “Peter”:
document.table.rows.tr[0].td[1]
Web browsers rely on layout engines such as Gecko, Webkit, and Blink to parse HTML into a DOM in a standardised manner.
Traditional web applications have a very tight coupling between the HTTP protocol and the way the user interacts with the application. In a totally static web application, the server contains a number of fixed resources, such as image files and HTML documents, with a fixed and unchanging content. Individual files are requested by clients and returned by the server. Each click of a link in a browser has a one-to-one correspondence to a HTTP GET or POST request followed by a new page being rendered from the server’s response. The web browser acts largely as a dumb terminal for remote display of content, and the server as a simple index and storage system for the data.
When the client receives an HTML document from the server, it renders it to the screen using an internal model similar to the DOM. The nodes of every document are organized in a tree structure, called the DOM tree, with the topmost node named as “Document object”.
Static web pages are simple, but not awfully powerful. You certainly could not build a modern web application in them, since they lack any ability to modify content dynamically based on user input. A basic functionality of most modern web applications is to have user-specific context, an example being at its simplest the display of the user’s name in a sidebar when they login. This is not possible using a completely static webpage. Instead, what is needed is a templating engine on the server, consisting of:
A server-side dynamic web page is therefore any web page whose construction is controlled by an application server processing server-side scripts. In server-side scripting, parameters determine how the assembly of every new web page proceeds, including the setting up of more client-side processing.
However, even server-side dynamic pages that follow the fundamental “one click, one request-response” cycle fails to live up to contemporary consumer expectations for a user interface – they fail to deliver on the instant feedback from desktop GUI applications that users are accustomed to.
The solution was increasingly to move the processing of data, and especially the templating engine, to the client side, where it can be executed locally by a client-side scripting language such as JavaScript. A client-side dynamic web page processes the web page using scripting running in the browser as it loads. JavaScript and other scripting languages determine the way the HTML in the received page is parsed into the DOM that represents the loaded web page. The same client-side techniques can then dynamically update or change the DOM in the same way. In this model, the web browser retrieves a template from the server (with unpopulated placeholder such as “[user]” still intact), and then processes the code embedded in the page (typically written in JavaScript) and displays the final rendered page containing the populated template to the user.
DOM methods allow programmatic access to the document tree by client-side script, permitting the client-side script to update the structure, style or content of a document locally in the browser. The DOM acts as an interface between JavaScript and the document itself, allowing the JavaScript to:
This is best explained using a simple example. In the following HTML there is some embedded JavaScript that will execute client-side when an event is fired:
<!DOCTYPE html> <html> <body> <h1 onclick="this.innerHTML = 'Ooops!'">Click on this text!</h1> </body> </html>
In this example, there is a Header displaying:
Click On This Text!
Because there is an “onClick” event assigned to the header, when we click on the Header, the DOM fires an onClick event on the document.body.h1[0] node within the DOM, and the text changes to:
Ooops!
We now have all we need to describe what a Single Page Application (SPA) is and how it works. So without further ado…
Essentially a SPA is a client-side dynamic web application that makes a full HTML page load initially but thereafter responds to all DOM events initiated by actions such as clicking on links by dynamically rewriting the current web page, rather than the default method in a traditional “multi-page” web application of the browser loading entire new pages.
It’s important to note that while the full page does not reload at any point in the process, and nor does the page control transfer to another page, the page may trigger requests for additional resources from the webserver. The difference is that these are treated as subsidiary resources, in the same way that a traditional webpage may instruct the browser to fetch additional resources that it needs to render as components within it (such as images, CSS files, etc). The functionality is delivered typically by JavaScript frameworks like AngularJS, Ember.js, Meteor.js, and Knockout.js.
Requests are typically made to a server-side API endpoint and do not return HTML but raw data as XML or JSON. When raw data is returned, often a client-side JavaScript process is used to translate the raw data into HTML, which is then used to update a partial area of the DOM.
The goal of SPAs is to offer faster transitions on user interactions and to make the web application feel more like a native application that is running locally on the device – in many senses, it is a local application, albeit one that is loaded from the internet rather than from local disk when it is launched. In operation, a SPA closely mimics the behaviour of a desktop application. The loaded page URL does not change when you navigate around the website, the SPA will store data locally in the browser cache, and will typically continue to function even while the host on which it is being browsed is offline – at least until it requires loading an additional resource. In essence, SPAs have the equivalent of a server-side templating engine running in your browser, removing the server processing component and reducing the server to a static resource server in some respects (this is not strictly true, since some logic must be contained server-side as we will see shortly).
In order to consider some of the challenges that Single Page Applications present for web application scanners, it is worth taking a look at how traditional DAST (Dynamic Application Security Testing) tools such as vulnerability scanners typically work.
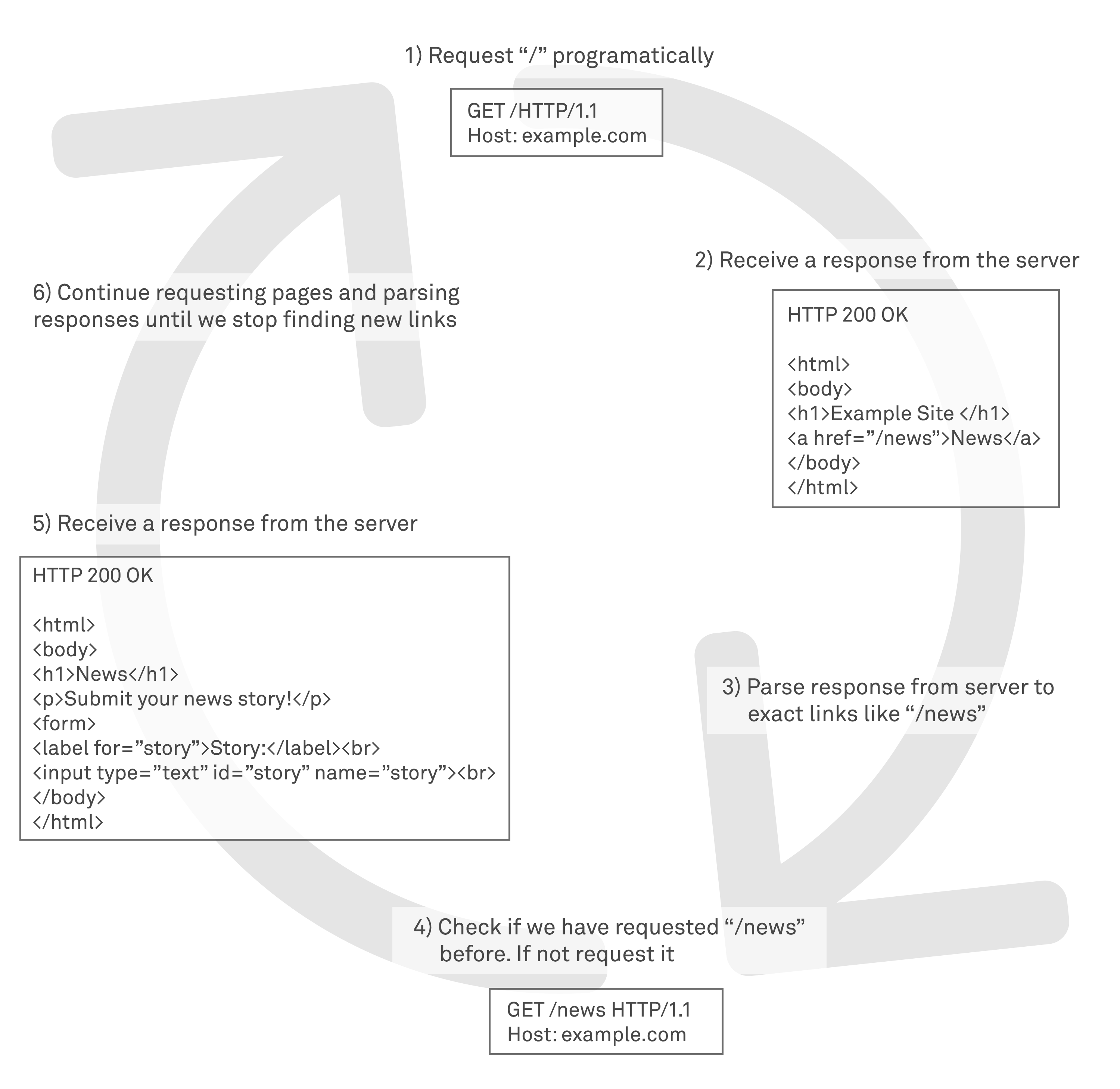
The basic process that the majority of web application DAST scanners follow is to:
The reality is a little more complex than this, but as a basic model it captures the process conceptually.
Because Single Page Applications have evolved from the stateless page-redraw model that browsers were originally designed for, some new challenges have emerged both in areas such as search engine indexing and – specific to our consideration in this article – security scanning. SPAs present a significant challenge to scanners because the underlying paradigms that traditional crawlers have been based on do not deal well with JavaScript-rich applications. We will look at several of the issues below:
In a traditional web application, as we have seen, returned HTML resources can be parsed for HTML links to add to the target list for scanning. However, in an SPA there are no returned HTML resources after the initial payload. Additional data may be retrieved in XML or JSON format for example but these do not contain HTML and cannot be scraped – it does not make sense to try and scrape for “links”, since the concept of hypertext links simply is not used within SPAs – events may generate calls to server-side resources from an API but the API calls are pieced together by client-side logic.
Resources located on the server and loaded by the SPA are typically made available by an Application Programming Interface or API. These are notoriously tricky to scan because they cannot be crawled – instead they consist of a number of methods, each of which take specific parameters in order to return any valid data. A scanning engine cannot scan the server-side API accompanying a SPA without gaining specific knowledge as to the API methods, as well as (typically) successfully authenticating against the API. This information must be either pre-seeded in the scanner, or else the scanner must be able to piece it together by simulating a client-side application by rendering and executing the SPA natively as a browser would and flexing the functionality by simulating a user actions.
In a traditional web application, each request is idempotent, and each resource request requires preserving minimal state in the Webkit-based scanner. However a SPA typically consumes a greater memory footprint and makes greater demands for preservation of state. This means that SPAs are typically more memory-expensive for scanning engines. Since the client is now effectively running a full application for the target SPA, it can also be subject to memory leaks as with any application – JavaScript can even cause powerful scanning system to slow down or run out of resources.
In addition to the issues presented with crawling and scanning a SPA, SPAs present their own unique set of security risks that a scanner must be optimised to check for:
Using XSS, attackers can inject malicious client-side scripts into web applications. Single-page apps may be more susceptible to cross-site scripting (XSS) attacks than are multi-page applications, because of the greater reliance on client-side scripting for their functionality to manipulate user input. Although many frameworks include some XSS protections out of the box, there have been many instances of these being insufficient or misunderstood.
SPAs typically present data to the client via an API. If developers do not place adequate authorisation checks on what data is returned in JSON/XML requests, as well as in the initial large page load, it is easy for sensitive data to be exposed to all users. A typical such scenario is where an API relies on the client-side code to filter data intended for a particular user, which though on the surface appears to be functioning correctly in fact means that any data may be accessed by any user, and possibly without authenticating at all.
There is a temptation in SPAs to use client-side logic almost exclusively in delivery of the goal of making minimal requests to the server-side API and deliver fast application responses. However, this can lead to missing access control at the functional level and a failure to enforce proper security server-side. Since developers move features and logic off the server and out to the client, it is easy to provide a client with access to functions that they should not be permitted to use. This is similar to the data exposure vulnerability outlined above, only relating to function access – for example a set of code for all functions may be returned and then a check made for if the user is an admin client-side before the SPA decides whether to display administrative functionality. However, if this check is not paired with appropriate server-side checks, then a malicious user with sufficient technical ability can “unmask” the administrative functionality client-side and gain access to functions that they should not be permitted to.
In order to effectively scan a Single Page Application, a DAST scanner must be able to navigate the client-side application in a reliable and repeatable manner to allow discovery of all areas of the application and interception of all requests that the application sends to remote servers (e.g. API requests).
AppCheck has developed a custom framework to accomplish this by harnessing the power afforded by modern browsers.
A “headless” browser (i.e. no interface is visible to the user) is used which can be programmatically controlled and all events within the browser (either DOM events or requests to remote servers) can be monitored and manipulated by the crawler.
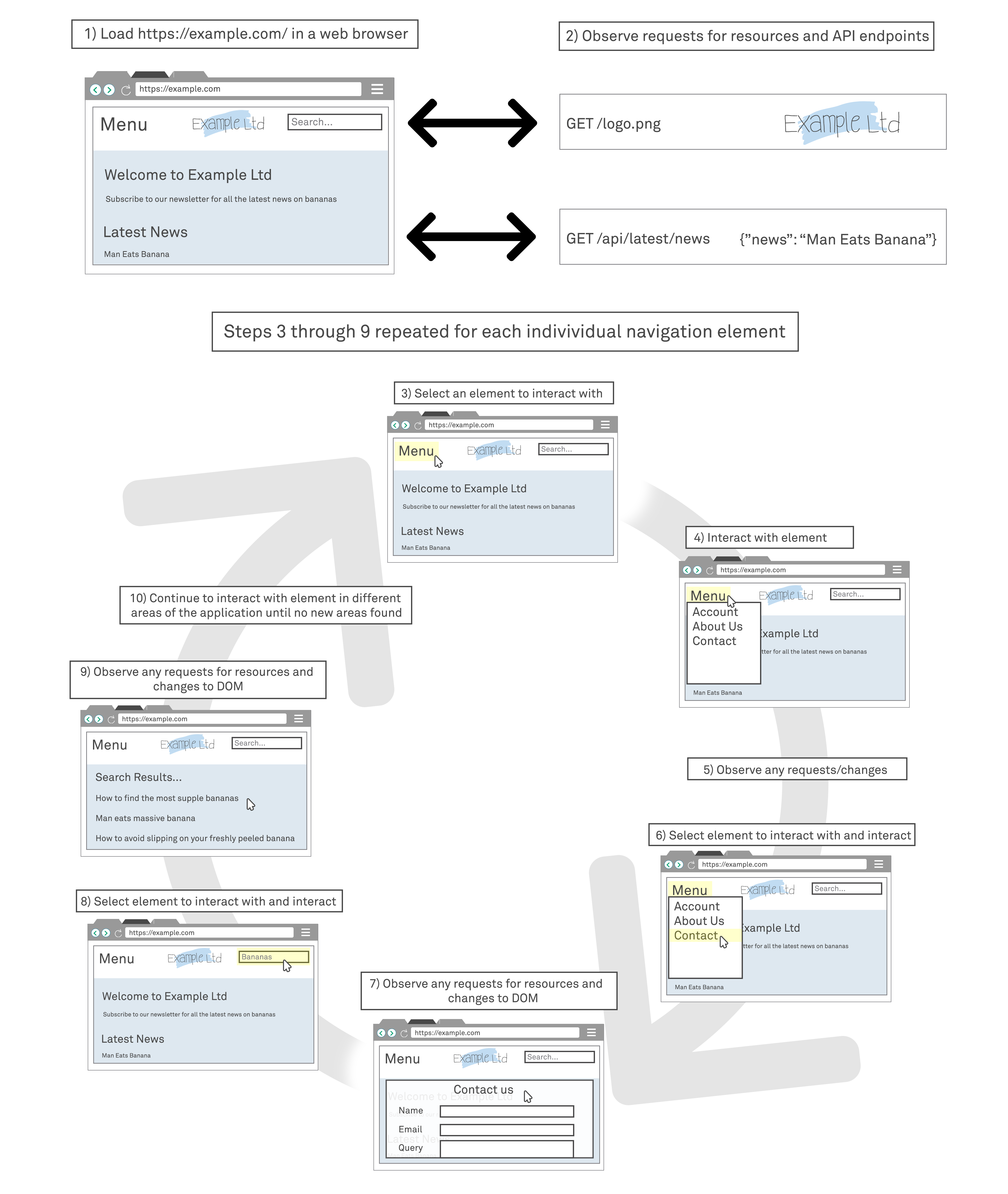
The application is first loaded within the browser and given time to load all its components and initialise itself.
The crawler then identifies all elements which are visible to the user within the rendered view, particularly those that appear to be navigation or user input components.
A visible component is selected for exploration and an interaction event triggered; to the client-side application this is indistinguishable from a user interacting with the application.
The crawler waits for any events that may have been triggered by the interaction to complete and then inspects the rendered page again to identify any new components which have been exposed following the interaction. For example, the first interaction may have been to hover over a menu item which exposed a sub-menu with further navigation options; or submitting a form to a “search” component may expose a results page and links to other areas for the application.
This process of selecting a component within the rendered view, interacting with it within the browser, observing changes, and selecting another component from the ensuing page, is repeated until all components at every step of the flow have been pursued.
[click for larger image]
[click for larger image]
Once the crawler has a comprehensive list of areas within the application, requests made to remote systems, and the flow of interactions required to trigger the application components, the scanner can proceed to test these targets for vulnerabilities.
It is the ability to inspect and interact with the application within a browser in the same manner as a user, which sets the crawling of SPAs apart from the traditional method of crawling a web application by parsing the resources returned by the server.
AppCheck has also developed a lightweight and user-focused scripting language, dubbed GoScript, which can be used to direct the scanner’s interaction with the application within the headless browser. This can be used to complete complex authentication processes which may be required to access the application, and to facilitate scanning of a specific area or user journey within the application.
You can view the scanner in action on the below two videos:
AppCheck Single Page Application Crawler vs OWASP Juice Shop
AppCheck Single Page Application Crawler vs Microsoft Word
AppCheck helps you with providing assurance in your entire organisation’s security footprint.
AppCheck performs comprehensive checks for a massive range of web application vulnerabilities from first principle to detect vulnerabilities in in-house application code. AppCheck also draws on checks for known infrastructure vulnerabilities in vendor devices and code from a large database of known and published CVEs. The AppCheck Vulnerability Analysis Engine provides detailed rationale behind each finding including a custom narrative to explain the detection methodology, verbose technical detail and proof of concept evidence through safe exploitation.
AppCheck are a software security vendor based in the UK, offering a leading security scanning platform that automates the discovery of security flaws within organisations websites, applications, network, and cloud infrastructure. AppCheck are authorized by the Common Vulnerabilities and Exposures (CVE) Program as a CVE Numbering Authority (CNA).
As always, if you require any more information on this topic or want to see what unexpected vulnerabilities AppCheck can pick up in your website and applications then please get in contact with us: info@localhost