Session Hijacking refers to a collection of methods that can variously be attempted by attackers in order to compromise the confidentiality of a web user’s HTTP session token. If successful, an attacker is able to appropriate and assume the target user’s digital identity for a given website (or domain), bypassing authentication controls and gaining access to their account. Once an attacker has adopted another user’s identity, they can typically perform any action that the user has permissions to perform – the impact can vary depending on the web application that has been compromised but an attacker may choose to exfiltrate confidential data, commit financial fraud, or deny access to the legitimate user by changing account access credentials.
In this blog post, we look at how exactly session hijacking works in practice, the underlying mechanics of session management that permit it to occur, how attackers may choose to exploit the weakness when it is discovered, and how website users and site administrators can best safeguard themselves and their organisations against the exploit.
In general usage, a “session” describes any period of time or meeting arranged for or devoted to a particular activity – we’re all familiar with “gym sessions”, “planning sessions” or maybe even “drinking sessions”.
Within the context of web application terminology, as is often the case, a “session” partially conforms to this same broad meaning, albeit with some exceptions as well as variations between different “session” types: a web session is a “meeting” or sequence of communications between a client (remote user) and a server (web application), consisting of a sequence of network HTTP request and response transactions over time. However, due to a variety of ways in which sessions may be implemented at a technical level, the individual transactions may or may not be contiguous, or clustered closely in a discrete time period – and a single user may be able to establish multiple, concurrent sessions with a given server.
A web session assigns a sequence of browser requests as being part of a single “conversation”, but which requests a client chooses to assign to a given session is ultimately under their control, due to the mechanism used for managing sessions, as we shall see shortly. Typically, however, a web session is a mechanism delivered by web servers to provide a means for correlating and contextualising multiple discrete interactions (such as webpage requests) from a given client into a single, ongoing and logical narrative. This can then be used by the server to deliver complex transactional flows that require the context of previous state and transaction history in order to deliver functionality – an example might be a shopping cart application, where “checkout” can, logically, only follow from early actions such as “add to basket” for one or more products.
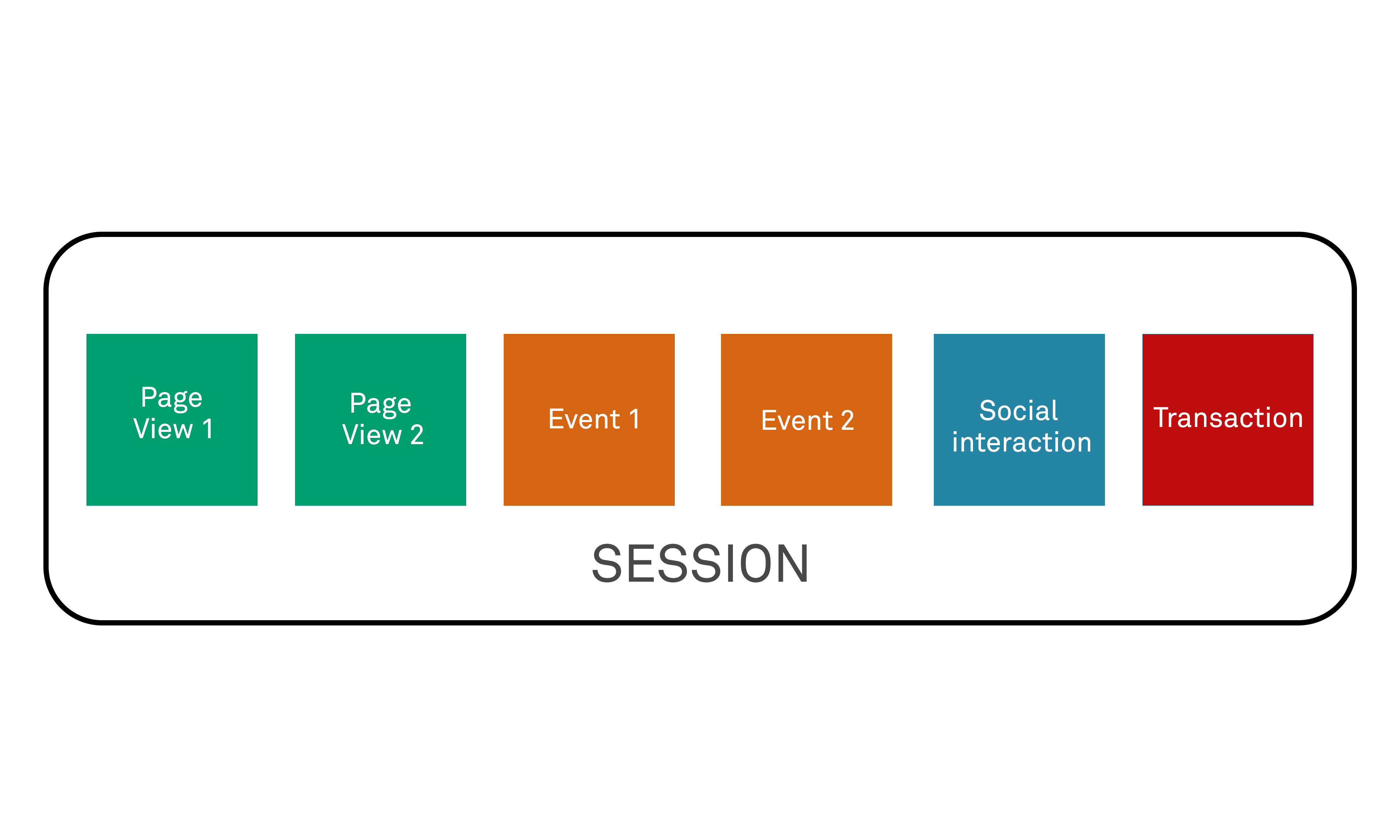
For the sake of illustration, imagine that web servers were to operate with no concept of “sessions”. A given user may visit a website and click “login” and receive the HTML code for the login page in return. They may complete the login form and send their credentials to the server, which the server may authenticate and then send them the “login success” page. So far so good! However, let’s imagine now that after some time the user clicks on a link to show account history. The server receives a request to say, “show me account history”. When the user earlier clicked on “login” and received the HTML representing the login form in return, the server was following a simple control flow and was acting essentially in a context-free manner – it would have returned the same login form in response to any login request from any remote client. However, in the case of “show me account history”, then clearly the server needs to know *whose* account history to return. It may have issued 5 responses for requests for login pages in the last hour, or 50, or 50,000 – and it doesn’t know which of the now logged-in users wants to see their request history because there is no context.
Sessions, therefore, deliver what we would consider fairly fundamental behaviour for the modern internet – the ability to establish and track a remote client’s unique identity in such a way that that identity (and any associated data that the server chooses to store and associate with it) can be applied to every future interaction with that user.
The best example by analogy is if you imagine attending a concert – your identity may be checked by checking your driving license or similar as well as proof of ticket purchase, and you are then issued “credentials” specific to that event, such as a lanyard. You’ve been authenticated (once) when first queuing up for entry but you can now leave and re-join the venue at will, presenting your lanyard as a “token” or proxy for your identity, without having to re-establish your identity all over again.
You may at this point be wondering why the explicit use of “sessions” is required at all and wondering why on earth a web server cannot simply natively understand the transaction history of a given client that it is communicating with. The reason for this is that the HTTP (HyperText Transport) protocol that underpins the entire web is essentially stateless – even though the protocols that it itself is supported by further down the network stack (such as Transmission Control Protocol or TCP) themselves make use of the state to implement measures such as flow control. By stateless, we mean that HTTP is by design on a simple request-response model, in which each request-response message pair between client and server represents an independent transaction that cannot be tied to any other transaction that may have occurred previously.
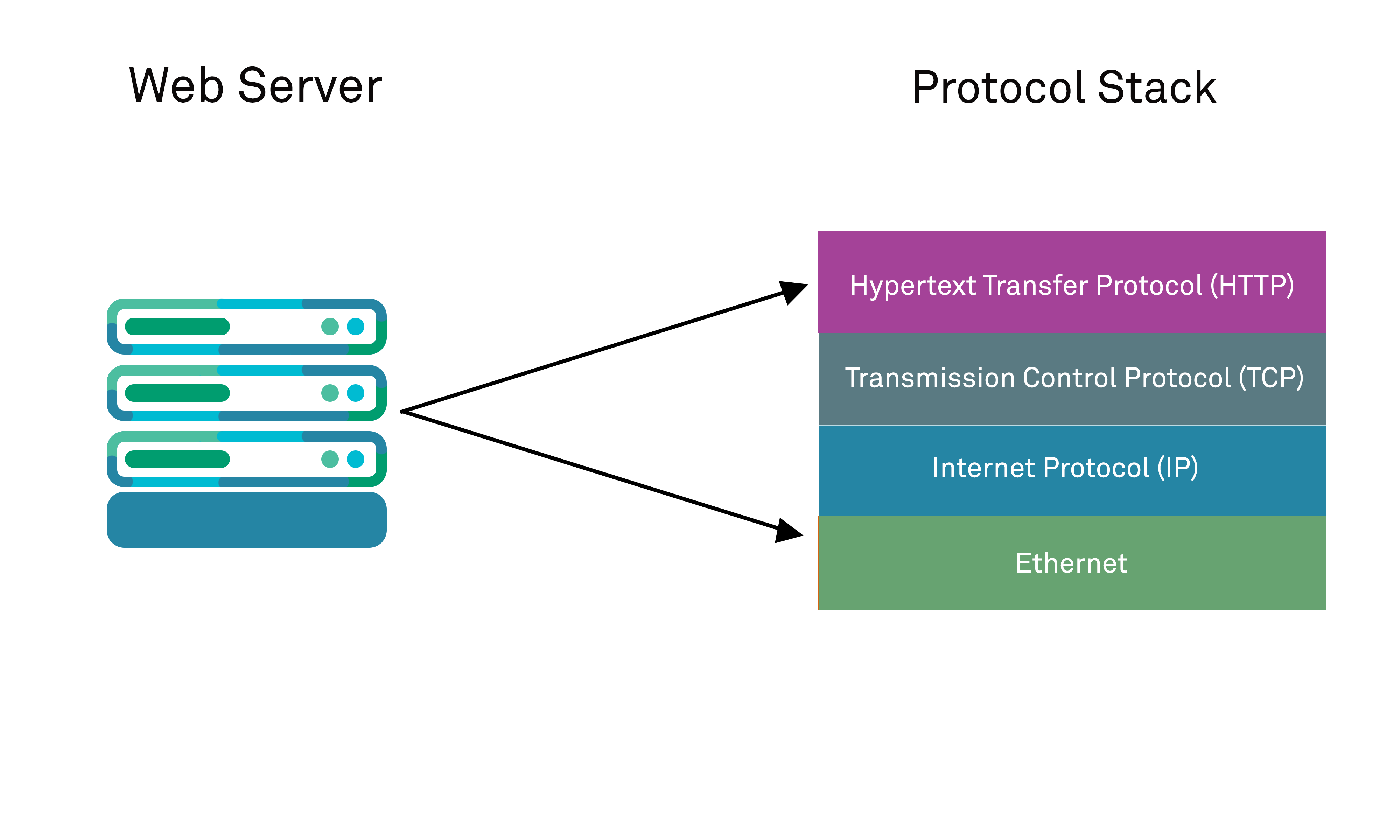
An individual request from a client has no other context by default under HTTP than the information that it contains within it as data in either the message body (the payload being transmitted) or its accompanying metadata in the request’s associated message headers (such as the encoding format being used for the data, its data length, etc).
Under HTTP, a browser simply uses HTTP to send a request to a server and accepts the data returned by the server in response, at which point the transaction is “closed” and considered complete.
In order to provide context between multiple discrete requests from a client, web developers, therefore, need to implement some additional mechanism for providing a persistent state for a given user. In the early days of the internet, various methodologies were used, including in some implementations the preservation of state via client-side data storage. However, over time there has been a convergence upon a single technical solution across nearly all application platforms – the establishment of a unique session identifier on the server (known as a session ID or session token) that is assigned at session creation time and transmitted to the user. It is then used by both parties as a shared secret – any request received by the server that is accompanied by the session ID can be safely assumed by the server to have originated with the client that the token was issued to.
The vulnerabilities that exist in session management mechanisms largely fall into one of three categories:
We will take a look at each of these in turn below, after looking at the underlying mechanisms that support tokens’ usage and which can potentially be subverted by an attacker.
The exact mechanism that a server uses to generate a session token will vary by individual implementation, but the key requirements are that the token issues for a session:
Numerous methods are used by various web application platforms for performing the client-side storage and the transmission of session tokens between client and server. The most common solution is HTTP “Cookies” which we shall look at shortly, but other technologies and methodologies are sometimes seen for both the client-side storage of the session variable, as well as the transmission of the variable to the server – these include the use of JSON web tokens, the embedding of a session variable within other HTTP headers, within URL/query strings hidden form fields, within the body of the HTTP request itself, and even via the window.name DOM property. Perhaps the most common of these “alternative” methods is the use of URL rewriting in which the session ID is transmitted as part of the URL itself (typically as a key-value pair within the URL’s query string) – for every request that the server received from a client it checks the session ID provided in the query string, verifies it, and then re-uses it in its response, typically encoding the session ID explicitly and dynamically into every hyper-link/URL within the returned HTML document sent back to the requesting user. However, this method is prone to a number of security issues and is generally advised against.
For the remainder of this article, since it is not possible to cover every single potential session token mechanism, we shall focus on the “HTTP Cookie” model, which incorporates both a solution for client-side session token storage, as well as a mechanism for communication or transmission of the session ID between the server and client.
An HTTP cookie is a small piece of data that is issued by and therefore associated with or attributed to a specific website (technically a specific domain), and which is stored on the user’s computer by the user’s web browser. Cookies exist as what is known as attribute-value pairs in the format “[attribute]=[value]”, and encoded for transfer between client and server as below:
Session-id=jcDvOW0u…
These are then stored in the browser (client) and server alike as these name/value pairs. It makes use of two HTTP headers (part of the metadata that a browser automatically attaches to each request sent to the server and vice versa):
Using the Set-Cookie header, a server will send the user agent a short string in an HTTP response that the user agent will then automatically return in all future HTTP requests (that are within the scope of the cookie), bundled along with the actual request data.
For our purposes here in relation to session management, then once a user has authenticated and proven their identity to the server, a server can send the user agent a “session identifier” named session-id with the value 12345. The user agent then returns the session identifier in subsequent requests as a stand-in for conducting a full re-authentication from scratch and hence maintaining an ongoing stateful connection.
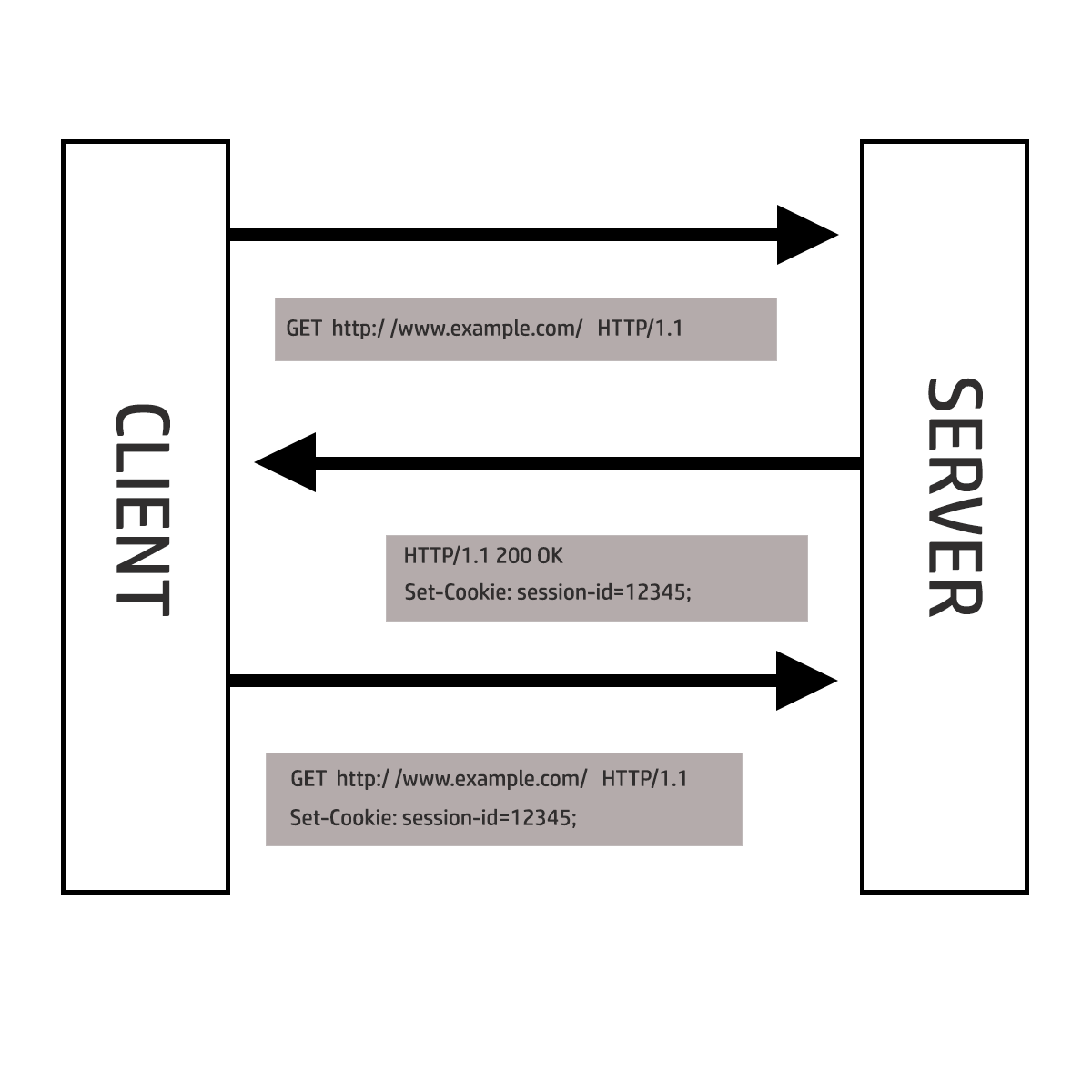
The server’s first response to a new client contains an HTTP header like the following:
Set-Cookie: ASP.NET_SessionId=mza2ji454s04cwbgwb2ttj55
Subsequent requests from the client contain this header:
Cookie: ASP.NET_SessionId=mza2ji454s04cwbgwb2ttj55
Session hijacking is the act of an attacker managing to take control of an existing (authenticated) user’s session. It can occur via the attacker either obtaining, valid session ID, or else generating a new session ID despite not being an authenticated user. In our earlier analogy of the concert venue access, it is equivalent to the attacker either managing to take a person’s lanyard and wear it themselves, or forging a new (counterfeit) lanyard that passes scrutiny by concert security. It allows an attacker to take over or “hijack” the session, assuming the identity of the user in question as far as the server is concerned.
There are four main methods used to perpetrate a session hijack. These are:
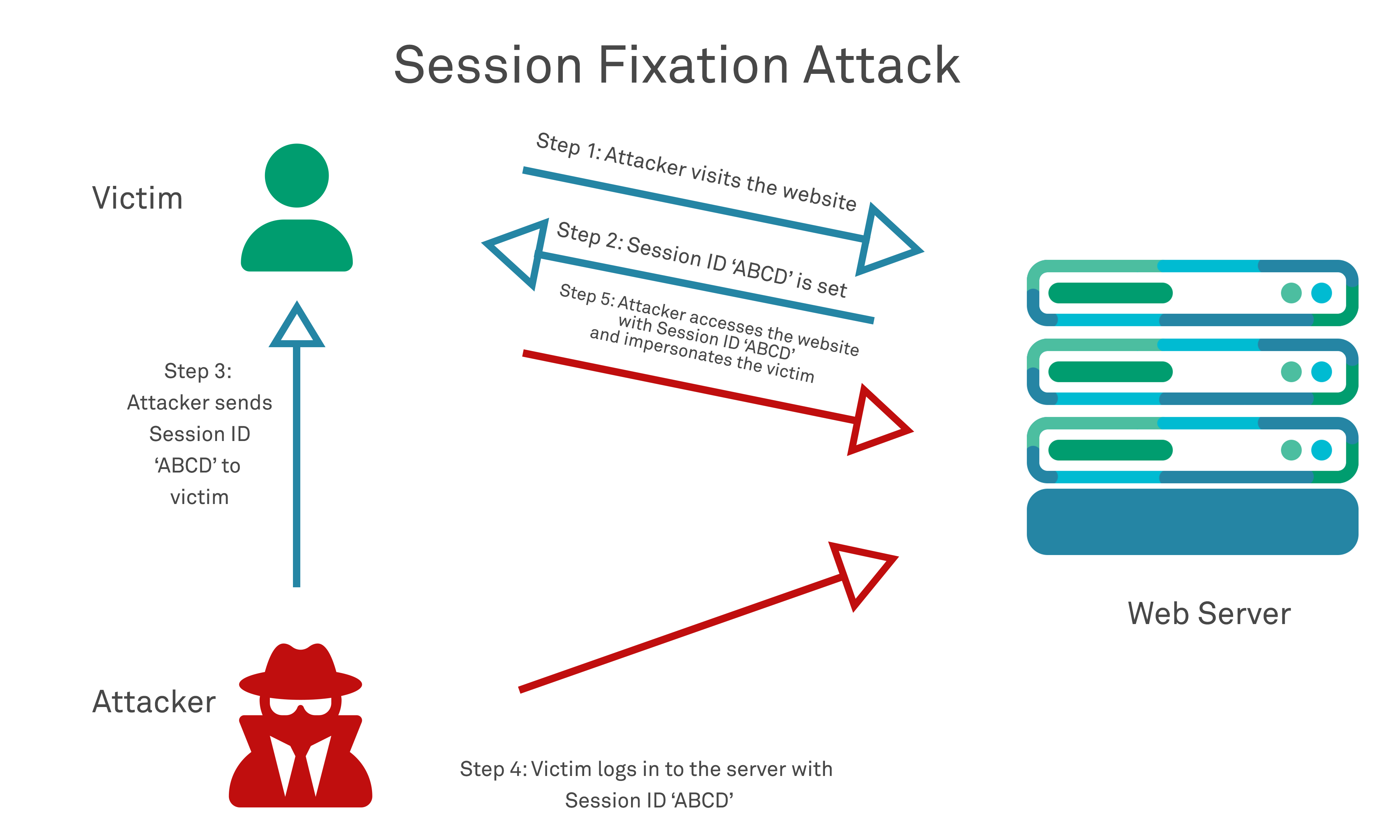
Session fixation in many ways is the opposite of how we might think of hijacking working, in that it involves the attacker giving something to their victim, rather than taking something from them. It works by an attacker generating a session ID (so that they know the value) and then tricking a legitimate website user into beginning a session with a target server using that session ID. Since the session token value is known to the attacker, then once the victim has authenticated with the server, the attacker can simply begin using the session token themselves and be dropped into an authenticated context by the server.
Session fixation attacks can be conducted by a number of means, but might typically involve sending a target user an email with a link to a website that contains a particular session id within the URL.
In a session side-jacking attack, also known as a session sniffing attack or man in the middle, an attacker who is suitably positioned on the network is able to intercept a session ID that is being transmitted across the network (such as in a “Set-Cookie” header). This can be performed by using a “packet sniffing” technique for example in order to read network traffic between the client and server and read the session ID value. It is not trivial to conduct, since the attacker must find a website that is operating in plaintext (HTTP) without the use of SSL/TLS encryption, and they must also be positioned on a shared network segment with the victim, or otherwise be in the network path between client and server – Wi-Fi hotspots such as in a coffee chain or fast food restaurant may be one potential point of presence for such an attack if they are unsecured since it is generally possible for anyone with access to the WiFi network to be able to intercept and read traffic from any other clients that are broadcasting to the same, shared wireless access point.
Session tokens can also be stolen via client-side attacks (attacks taking place within the client’s browser or broader computer system). A typical example might be the use of a Cross-Site Scripting (“XSS”) attack, in which an attacker tricks the user’s browser into executing client-side code such as JavaScript. If the code in question appears to originate with the legitimate server that the client is communicating with by loading a compromised page, then the malicious (injected) script is able to gain access to the user’s session token.
Alternatively, if an attacker is able to install malware onto a user’s computer (via e.g., a phishing scam), then they can potentially steal the entire cookie repository of the user’s browser, granting the attacker native access as that user to every single website that the user has logged into – or at least those that have an active session within the timeframe that the malware is able to operate without being detected and/or removed by the user. This is sometimes referred to as a “Man in The Browser” attack (named after the more common “Man In The Middle” attack outlined above). In variants in which the malware is specifically designed for session hijacking (as opposed to more general malware such as an all-purpose keylogger or trojan providing an attacker with backdoor host access), the malware can insert itself as a form of “hidden proxy” between the browser and the client computer’s network stack, sniffing or modifying transactions using the session token or even manipulating the DOM itself before it is passed to the client browser for parsing and rendering.
In a brute force attack, the attacker generates and submits multiple session IDs at a high volume/rate until one is found to successfully grant them access. In the distant past, sequential keys or keys drawn from a small overall key space were a typical weak point, but with modern applications and protocol versions session IDs are generally sufficiently long and cryptographically strong enough with a large enough key space to make such attacks improbable to succeed.
In a slightly more sophisticated variant, it may be possible for an attacker with sufficient contextual knowledge to reverse-engineer a valid session ID in what is known as a session prediction attack. By analysing and understanding the session ID generation process, an attacker can predict a valid session ID value that grants them access to the application. In the first step, the attacker needs to collect some valid session ID values that are used to identify authenticated users. Then, they must understand the structure of session ID, the information that is used to create it, and the encryption or hash algorithm used by application to protect it.
If a session ID was generated in a non-random manner – and especially if generated in a deterministic manner based upon a client’s username or other predictable information such as a timestamp or client IP address – then it may be possible for an attacker to calculate a valid session ID. This can either be performed via direct calculation if the session token generation algorithm is entirely deterministic or else in combination with the brute force method outlined above if the algorithm is partially deterministic in such a way that the valid key space is reduced to a manageably brute forceable size.
Session IDs are ultimately just string data, and as such are potentially susceptible to being recorded or persisted in memory or to disk server-side in various places, including in logs, caches and proxies. They are then susceptible to data leakage – since the system in question may not understand that the session token is a security variable, it may log it as part of an HTTP request in a form or system that is stored at a lower level of protection or resource sphere that an attacker may be able to access even if they cannot compromise the web server itself. An attacker who gains access to one (or potentially all) historical session IDs in this manner can reuse the valid session ID in what is known as a session replay attack.
It may also be possible for an attacker to leverage a technically unrelated vulnerability known as DNS cache poisoning in order to pivot onto a session hijacking attack. If an attacker is able to cause a DNS server to cache a fictitious DNS entry that they have themselves crafted, then this could allow the attacker to gain access to a user’s cookies. For example, an attacker could create a DNS entry on a vulnerable DNS server with an A record of “attacker.example.com” that points to the IP address of a server that is under the attacker’s control. If the attacker can then get a victim to load a resource from that server (such as a webpage, or even a static resource such as an image) then the victim’s browsers would submit all example.com cookies to the attacker’s server since it an apparently trusted sub-domain according to the DNS record.
Session hijacking typically involves an attacker managing to takeover or assume the context of an authorised client’s session on a target server. If successful, the attacker will have gained unauthorized access to any data or services that the user has permissions to access on the target service or system. They will also be able to perform any actions that the original user is authorized to do, potentially impacting the confidentiality, integrity and availability of various forms of data. Depending on the nature of the web application that the session is authorised on, this may mean that an attacker is able for example to:
Session hijacking is a particularly valuable form of exploit for attackers since unlike many forms of authentication weakness, if exploited it is typically able by its nature to bypass most multi-factor authentication protocols. Because the token that the attacker steals will have been issued by the server only after all authentication factors have been validated, the attacker is dropped into a fully trusted and authenticated context.
Encryption of the HTTP(S) connection between the client and server using SSL/TLS (preferably in combination with HTTP Strict Transport Security or HSTS) ensures that the session key cannot be captured by an attacker in a man in the middle of session sniffing attack. The “Secure” attribute for cookies containing session IDs should also be used, since it instructs the receiving user agent (browser) on the client’s PC to only return that cookie back to the origin server in subsequent requests if a secure (HTTPS) channel is being used, and not over a plaintext (unencrypted) HTTP connection.
When the cookies are being prepared by the server then they have options as to how to form the packaging cookie, as well as control over the message to place inside it. HTTP cookies, therefore, have a number of attributes or flags that can be set on them in addition to the core communicable content that they are designed to transmit (the attribute-value pair that we described above). These flags act as metadata that advises the receiving user-agent (the client browser) on various properties of the cookie that determine how the cookie and the data within it should be treated. The HttpOnly flag is one of these attributes that directs receiving user agents to prevent client-side script (such as JavaScript) from accessing the cookie data. Without this flag, cookies are treated the same as any other addressable data within the Document Object Model (DOM) in being accessible by executing JavaScript on the client side.
The HttpOnly flag is important because it is one of a number of measures that can partially mitigate the risks from Cross-Site Scripting (XSS) attacks against the client As a brief refresher, in an XSS attack, an attacker is able to inject their own malicious script code to execute on a user’s computer – if this script is able to read the contents of a cookie then it can exfiltrate (steal) any data or information it contains, such as a user’s session ID or personal information. When the HTTPOnly flag is set, conversely, then browsers that support the flag will not reveal the contents of the cookie to a third party via client-side script executed via XSS
The use of a long random number or string as the session key reduces the risk that an attacker can simply guess a valid session key through trial and error under a brute force attack. Most trusted libraries will ensure that a sufficiently strong algorithm is used.
The name used by the session ID should be unpredictable (random enough) to prevent guessing attacks, where an attacker is able to guess or predict the ID of a valid session through statistical analysis techniques or information known about the client. For this purpose, a good PRNG (Pseudo Random Number Generator) should be used and information about the client not be embedded in or used to seed the random number.
A pattern commonly seen in critical web applications such as online banking is to require explicit reauthentication from clients upon critical action. That is, some services will make secondary checks against the identity of the user if the user is requesting a critical transaction, such as withdrawing funds. This protects against various forms of session hijacking attacks including session replay attacks.
Rather than using a single token for the lifetime of a user’s session, it is recommended for the server to regenerate and re-issue a new session key after the initial authentication. The session key can either be changed either just once, immediately after authentication (which nullifies session fixation attacks since even if the attacker knows the initial session ID, it becomes useless before it can be used) or else repeatedly throughout the lifetime of the session and as frequently as upon each new request from the client under the session. This latter approach can dramatically reduce the attack window or period of time during which an attacker can make use of a session ID should they be able to capture it.
A session token is ultimately a single authentication factor, just like a password. As with passwords, session tokens can be strengthened by requiring a second factor be provided. Typically, the available factors are described as “something known” (e.g., a password), “something owned” (e.g., a hardware key), and “something you are” (e.g. a biometric signature). In the case of session tokens, a potential second factor can be provided in the form of a “browser fingerprint” – a digital key generated from information collected about a browser’s configuration, such as its version number, screen resolution, and operating system, for the purpose of identification. Assimilation of various pieces of such information into a single string constitutes a device fingerprint and can potentially form a second factor of authentication. Since it is still transmitted to the server it is not proof against all forms of attack but can help provide resistance to attack forms such as session fixation, since the browser fingerprint of the victim would not be known to an attacker.
Session replay attacks and other attack forms such as brute force session ID calculation reply on the attack window during which a session token is valid being practicably long enough to make an exploit feasible. By limiting the length of time that a session token is valid before a session token expired and a user must re-authenticate then an additional measure of security can be gained against these forms of session hijacking.
One of the basic features of the web is that of interconnections and (relatively) open access to resources. This means that a web application served to a client from one origin or domain (e.g., www.example-organisation.com) may return an HTML response containing a <script> tag instructing a client’s browser to load a resource from another domain, such as www.example-thirdparty.com, a domain that may be unrelated and owned and operated by another individual. This functionality is important in that it enables many of the common functionalities we see on modern websites and that the web depends up on.
A server that uses cookies to authenticate users can suffer security vulnerabilities because some user agents let remote parties issue HTTP requests from the user agent (e.g., via HTTP redirects or HTML forms). When issuing those requests, user agents attach cookies even if the remote party does not know the contents of the cookies, potentially letting the remote party exercise authority at an unwary server. Also known as the “Ambient Authority” problem, the user agent might supply the authorization for a resource designated by the attacker, possibly causing the server or its clients to undertake actions designated by the attacker as though they were authorized by the user.
The SameSite attribute for cookies controls how cookies are sent during these cross-domain requests. This attribute may have three values: ‘Lax’, ‘Strict’, or ‘None’. If the ‘None’ value is used, then a website may instruct user agents to perform a cross-domain POST HTTP request to another website, and the user-agent (browser) automatically adds cookies to this request. This may lead to Cross-Site-Request-Forgery (CSRF) attacks if there are no additional protections in place (such as Anti-CSRF tokens).
Lastly, it is advisable to perform a vulnerability scan of your services and endpoints to detect various forms of session hijacking attacks. Since some weaknesses may only be apparent in a production environment – due to environmental misconfiguration or other production-specific issues not apparent from code analysis alone – then additional assurance can be gained by development teams testing a web application or session hijacking weaknesses using a vulnerability scanner, in exactly the same way that a malicious attacker would look to do. Weaknesses that are found can then be remediated swiftly before they are able to be detected and exploited by attackers. In the case of integration with a continuous deployment (CI/CD) pipeline, issues can potentially be found before they are even introduced to the live environment.
AppCheck helps you with providing assurance in your entire organisation’s security footprint. AppCheck performs comprehensive checks for a massive range of web application vulnerabilities – including session hijacking weaknesses – from first principle to detect vulnerabilities in in-house application code.
The AppCheck web application vulnerability scanner has a full native understanding of web application logic, including Single Page Applications (SPAs), and renders and evaluates them in the exact same way as a user web browser does.
The AppCheck Vulnerability Analysis Engine provides a detailed rationale behind each finding including a custom narrative to explain the detection methodology, verbose technical detail, and proof of concept evidence through safe exploitation.
AppCheck is a software security vendor based in the UK, offering a leading security scanning platform that automates the discovery of security flaws within organisations websites, applications, network, and cloud infrastructure. AppCheck are authorized by the Common Vulnerabilities and Exposures (CVE) Program as a CVE Numbering Authority (CNA).
As always, if you require any more information on this topic or want to see what unexpected vulnerabilities AppCheck can pick up in your website and applications then please get in contact with us: info@localhost