A web server’s designed function is to deliver data and information to requesting clients, so on the face of it “information disclosure” can appear almost paradoxical and an odd phenomenon to class as a security vulnerability. Since it does not typically rely on sophisticated “active” attack techniques it can also attract less attention or be treated as a lower impact vulnerability that does not warrant serious attention. However, information disclosure can be both directly harmful in and of itself, as well as lay the foundation for further, more active attacks that build upon information gathered via this class of weakness.
In this blog post, we look at why information disclosure is considered to be an issue at all, how it occurs, the ways in which the information can be leveraged by attackers, and how organisations can best prevent against it.
Disclosure describes the act of revealing or uncovering information, very often deliberately. It has specific meaning within spheres such as financial regulation and the judicial system in precisely this sense of being a deliberate process or making facts and information known, in order to allow individuals and business to make appropriate and informed decisions. In these spheres, it is explicitly intended that all parties are granted equal access to the same facts in the interest of fairness.
However, within web application security, information disclosure typically relates to an almost antithetical concept: that information should be appropriately restricted, and that its disclosure to certain parties constitutes a security weakness or exploitable vulnerability.
Within cybersecurity, experts refer to the CIA Triad as being a simple high-level model of the core goals of an effective security programme. CIA as used here has nothing to do with a certain well-recognized US intelligence agency but rather is an initialism in this context that stands for Confidentiality (efforts to keep data private or secret), Integrity (maintaining a system or data set as whole or complete and immune from interference or unauthorized modiciation), and Availability (ensuring that systems are up and running and providing reliable access to resources that they are designed to).
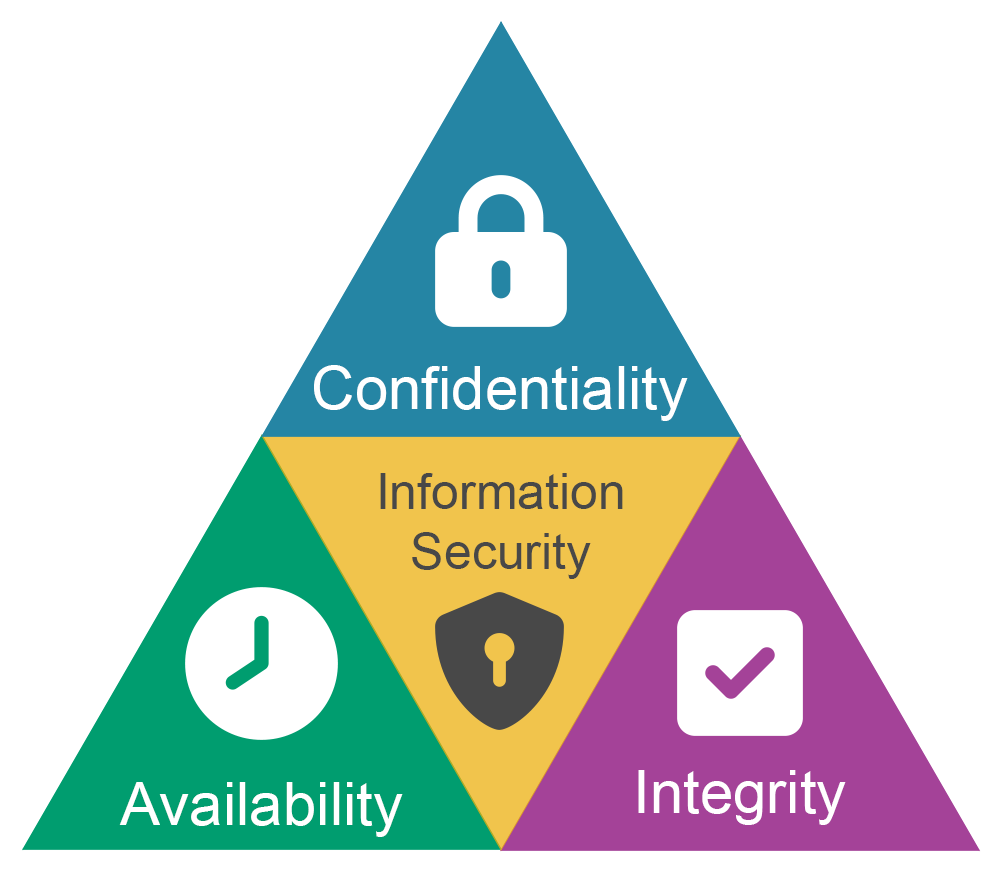
Although all three of these goals or principles are inextricably linked, information disclosure typically relates primarily to the goal of confidentiality. An information disclosure vulnerability is one that compromises the confidentiality of a data set by undermining constraints about who is intended (authorized) to access specific assets or resources. Information disclosures can represent either global or provisory failures of confidentiality. In global information disclosure vulnerabilities, information that is simply not meant to be exposed to any external audience is inadvertently published or exposed: examples here might include database passwords, for example. In instances of provisory or conditional information disclosure, a resource or data set that is intended for a given audience (either an individual or group) becomes accessible by or is otherwise obtained by a different audience. This second instance typically occurs when restrictive controls such as access control measures have architectural or implemented weaknesses: examples here might include the use of weak encryption, weak passwords, or flawed application logic.
Information disclosed to an unauthorized party may be either directly or indirectly harmful.
In instances where the information disclosure vulnerability is directly harmful, the disclosure of the information itself, even if no further compromise occurs, will typically causes irreversible and immediate harm to the organisation suffering the information disclosure. This may be either because the information disclosed has value in itself (such as the loss of customer credit card numbers), or the publication and dissemination of the information causes direct financial or reputational damage (such as regulatory fines, or loss of revenue due to loss of customer confidence following a data breach).
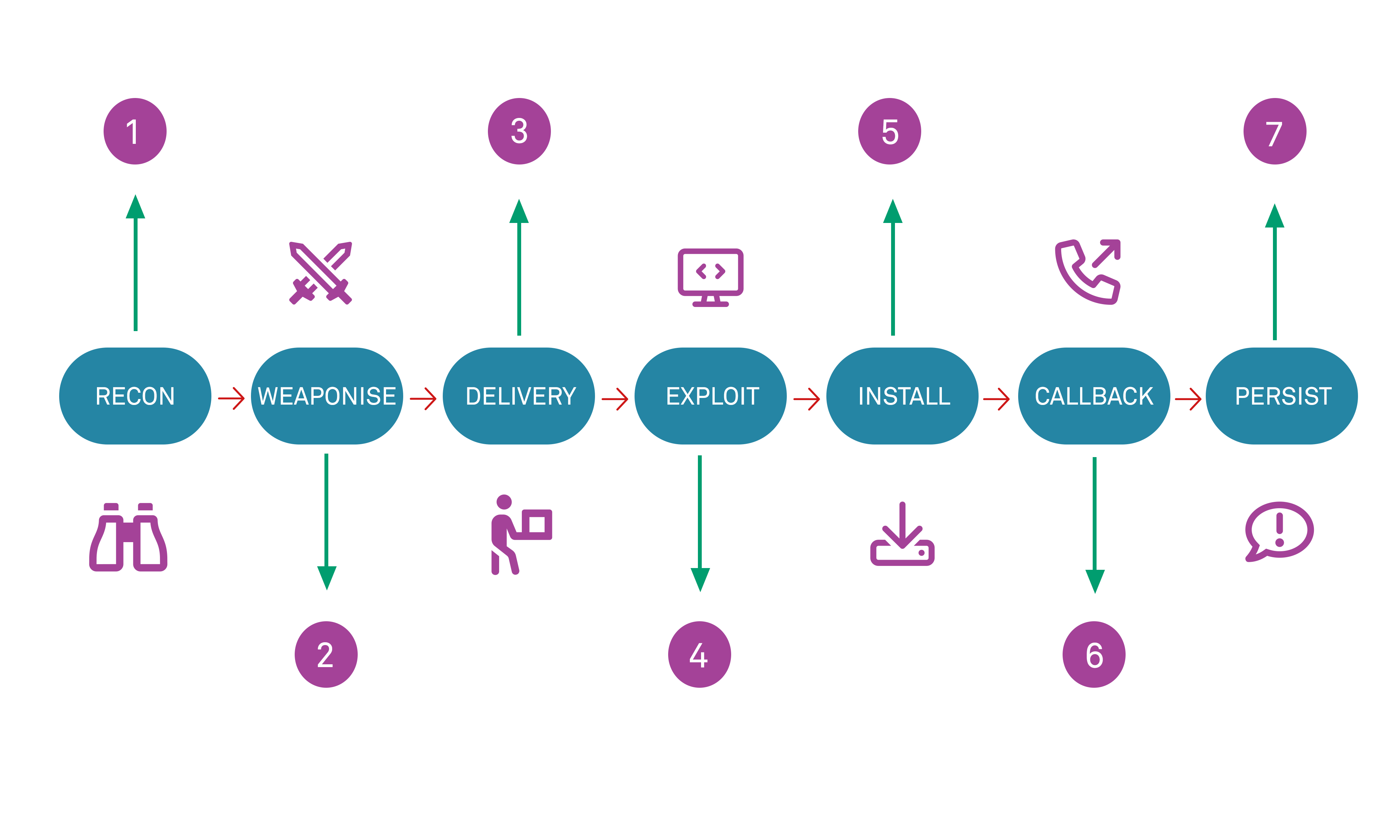
In instances where the information disclosure is indirectly harmful, the knowledge of the information in question by a third party does not necessarily cause immediate harm, but can be leveraged by an adversary in order to enable or facilitate further attacks against the organisation or its customers. This second type of information may not on the face of it appear even to represent a significant security threat, and its harm can often be underestimated by organisations. Examples of such indirect information disclosure might include the disclosure of information relating to the versions of software in use on a web application server. In this instance, the information can be used by attackers as part of a fingerprinting or intelligence-gathering phase of a multi-stage attack against an organisation, in order to potentially facilitate further attacks and exploits. For example, if the web server application software can be determined, it may be possible for an attacker to look up the vulnerabilities known to exist in that version, as published within a public CVE (Common Vulnerabilities Enumeration) database. This type of intelligence gathering is often referred to as reconnaissance. If the information has been disclosed deliberately – without an organisation understanding that its disclosure constitutes a security weakness that can be leveraged – then it may be classed as OSINT (open-source intelligence). In both instances, the gathering of such information can be used by attackers as the first of several steps in what is referred to as a cybersecurity kill chain that involves the successive application of multiple coordinated processes in sequence in order to execute and leverage a successful attack against an organisation:
The information that can be revealed is as broad as the data types that organisations handle, but some of the most common types of information disclosed, as well as why and how they may be useful to attackers is summarised in the shortlist below:
It may seem – intuitively – as though there is no real harm in knowing what operating system and application stack a web server is running. It is often said that organisations should not rely on security through obscurity (the practice of hiding information about implementations in order to try not to divulge information that can be exploited), and in areas such as cryptography the open publication of details as to exactly how an algorithm works is encouraged: this is done in order to establish the robustness of an algorithm if a weakness cannot be found in it, on the basis that the more eyes that have examined it the more likely any weaknesses that were present were to have been found.
However, web application security is a slightly different landscape in that no security benefit is conferred from providing information on what software product and version a server is: in contrast to cryptography, there is no robustness to be gained from disclosing the software stack and versions, only increased risk.
The reason for this is that when vulnerabilities are found in web application software the details are openly published – usually only after a fix has been released – to a publicly available database known as the Common Vulnerabilities Enumeration or CVE. The reason for this is to allow the (automated or manual) checking by security teams of whether security patches are available for a given system, and what security issues they address, in order to guide prioritisation of response within a vulnerability management programme.
However, this same information can be accessed by attackers: if a system openly advertises its software name and version, it is trivial for an attacker to identify any weaknesses that may exist. Rather than then attempting to exploit every vulnerability known to exist in every single web application software system – a process that is likely to be time consuming and may also trigger security systems such as Intrusion Detection Systems (IDS) or Web Application Firewall (WAF) defences, the attacker can launch instead a highly targeted and specific attack with a high chance of success.
As we saw above, some information that may be disclosed is of value to an attacker (and direct harm to an organisation) if disclosed, not because it is useful in conducting or guiding further exploits, as in the example of OS version numbers above, but because its disclosure in itself represents a loss. Instances where such data is disclosed are normally termed data breaches, and typically – though not always – relate to the deliberate exfiltration or accidental exposure of large volumes of data that relates to an organisation’s customers. This data is of highest value and most potential damage if exposed when it contains either sensitive personal data or financial information such as credit card numbers. Many types of the former information are explicitly protected under various legislative and regulatory measures such as the General Data Protection Regulation (GDPR) within the European Union, and its disclosure may trigger significant financial penalties for an organisation.
(It is worth noting that web server information disclosure is by far from the only vector by which data leaks and data breaches can occur – other vectors include phishing and social engineering attacks against staff, deliberate actions by disgruntled employees, data loss by third parties or lost portable devices (such as laptops) or physical records.)
A web server will typically provide some kind of stateful operation within a dynamic web application, permitting the registration of specific customers and individuals as authorised users. Details of each user are recorded and data such as account information and transaction history are then indexed against that user’s record. Each user’s records are then available only to that user, and no other, with access typically protected using a password or other application control measure. There is often value to an attacker in managing to compromise an account in gaining access to be able to act within the authorised context of that user and gaining access to their records. If a server’s authentication system makes use of a username/password combination for identification and authentication, then an attacker needs to know two quanta of information to gain access to the account – the user’s username, and the user’s password: if they are able to enumerate (get a list of) valid usernames on a given system, then the job of gaining unauthorised access to an account is made that much simpler for them, in that they have one of the two quanta required for authorisation (the username).
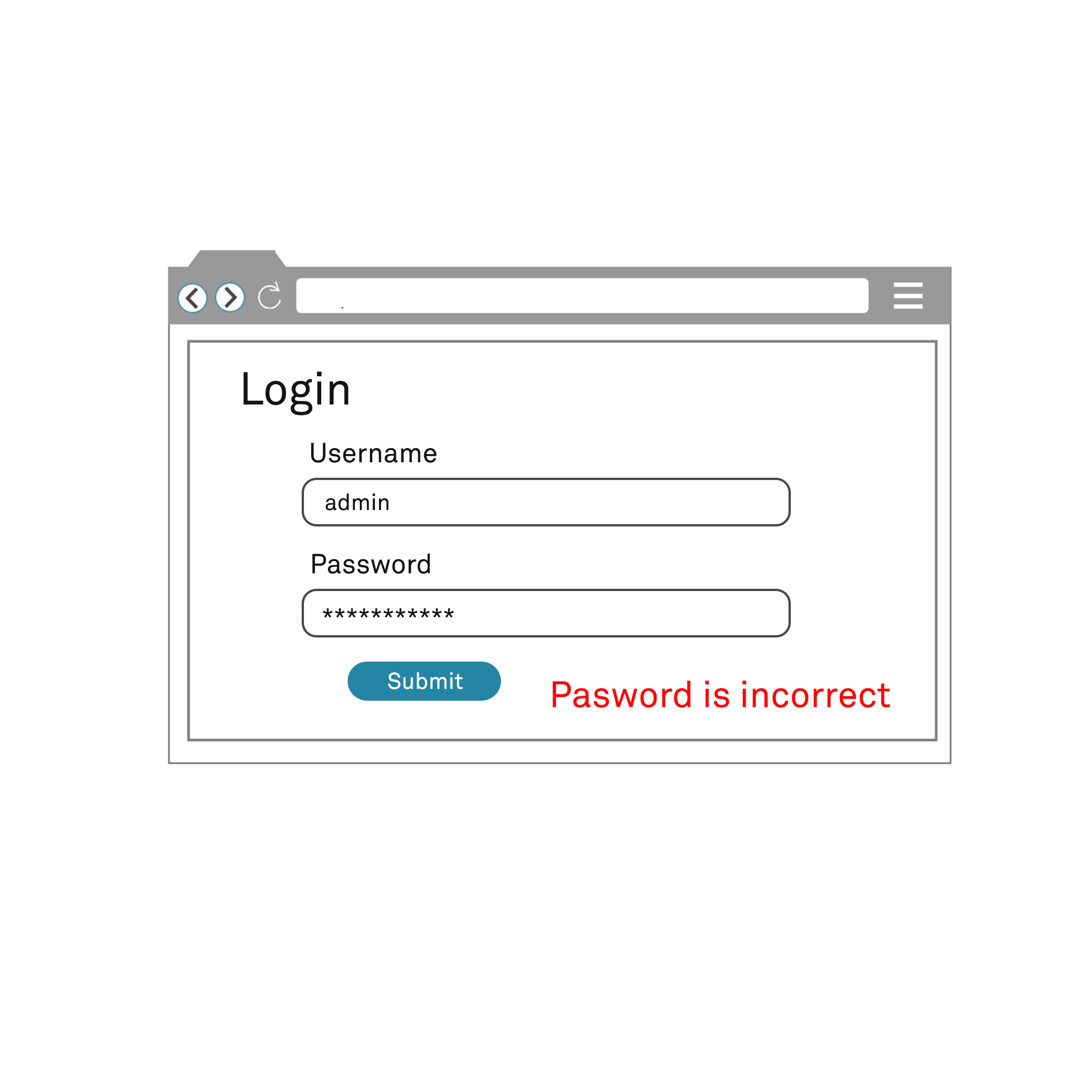
Web application servers that permit the enumeration of usernames are therefore said to be subject to username enumeration. There are many variations as to how this can occur, but a commonly seen example are login implementations that exhibit differential responses: if a system replies to a failed login attempt with “credentials invalid” as a message, then it does not disclose anything. If on the other hand it replies to a failed login attempt with a more specific message “that username does not exist”, then if the message changes to “the password you have provided is incorrect” when a given username is attempted by an attacker, the server has inadvertently disclosed to the attacker that the username provided was valid, and the server has exposed a username enumeration vulnerability that partially undermines its authentication system.
Server configuration information can be exposed either as an inherent property of the host that becomes known, or via the leak of an explicit configuration file that is used by the application server as part of its environmental configuration, containing environment-specific information such as database server IP addresses. Information exposed can include IP and endpoint addresses that are internal-only, as well as physical path information and software versions. In all these cases, the information gathered is useful to an attacker as part of their environment reconnaissance and fingerprinting, allowing them to gain knowledge that allows them to target specific attacks more effectively.
In some instances, configuration files may also include details such as database access credentials or API (Application Programming Interface) keys that permit an attacker to gain access to systems or services that they are not intended to access.
Web application servers operate by executing server-side code – code that is executed on the server in order to process HTTP requests and generate HTTP responses. This is true even for Single Page Applications (SPAs) or other systems that rely heavily on additional, client-side code execution.
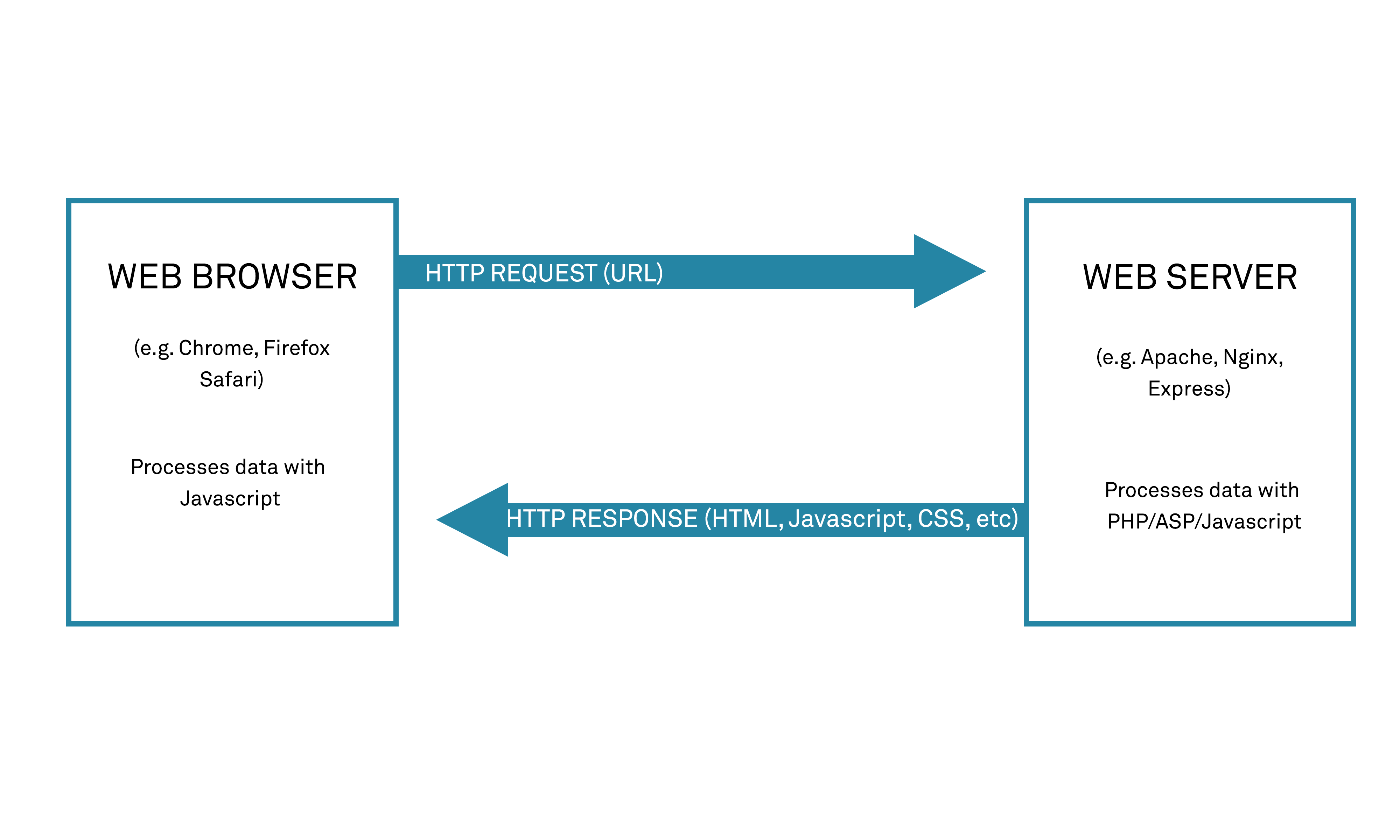
Although the results of the code are sent to the requesting client, details of the code itself are not themselves exposed.
However, in some instances, it may be possible for clients to receive a copy of the application code itself in response to a request, rather than a generated HTML response. This most typically occurs in one of three specific instances:
The dangers of source code being exposed in this way are numerous, including an attacker being able to analyse the code statically to detect weaknesses, the potential for code to include sensitive or restricted information such as passwords for database connection, or the use of comments in the source code that contain sensitive information.
Our last example of different information disclosure types relates to the accidental publication of internal organisational data, as opposed to customer data. If files such as version control systems or internal telephone lists are inadvertently exposed via a web server, then it is often possible for attackers to gain access to lists of employees. This information can be highly valuable in permitting social engineering attacks, including so-called spear-phishing attacks that target employees in positions that grant them access to resources most valued by cybercriminals.
The above are just a few of the more common types of web server information disclosure in terms of the data types revealed, and we’ll take a look below at a few of the different ways in which this information can be exposed to attackers or other external parties:
Version control repositories used to store and allow collaborative development of source code – such as “CVS” or “git” – store version-specific metadata and other details within subdirectories along with the code. If these subdirectories are uploaded directly onto a web server without filtering (as can often occur using CI/CD code deployment pipelines that are incorrectly configured) then these could become accessible by an attacker.
The information in these metadata files may include usernames, filenames and physical or virtual filepaths, host IP addresses, and detailed “diff” data about changes to source files which could reveal both employee information as well as source code snippets that were believed to have been redacted or were never intended to be made public in the first place.
A commonly seen variant of this is the .DS_Store files that are created by Apple’s Finder application in every folder to store metadata about the directory contents. If a developer inadvertently transfers this metadata to a webserver when publishing code, then it could be exposed to attackers. In 2015, a .DS_Store file that had been inadvertently published was used to gain access to an administrative portal of multinational Chinese electronics company TCL, permitting direct access by external parties to the application database.
Insecure & Default Configurations
The default configuration of many operating systems, utilities and applications is often optimised for flexibility and adaptability or ease of use, rather than security. If a standard configuration is utilised in production without efforts to reduce the attack surface via hardening of the system, then information may be inadvertently exposed that is useful to an attacker.
Perhaps the most notorious example of this is the phpinfo() function within the PHP application language used on many webservers. The official PHP documentation makes a recommendation to create a file that calls the phpinfo() function in order to test that the PHP installation was successful, and it is a common mistake to simply forget to remove this file (or else not appreciate the risks of failing to do so) and leaving it in place indefinitely. When enabled, this function exposes exceptionally detailed information about the configuration of both PHP and the underlying system itself to a publicly accessible website, including enabled modules, server filepaths, environmental variables, internal IP addresses and software versions. All this information can be used by attackers to inform specific further attacks, including directory or path traversal attacks – and certain versions even permitted Cross-Site Scripting (XSS) attacks.
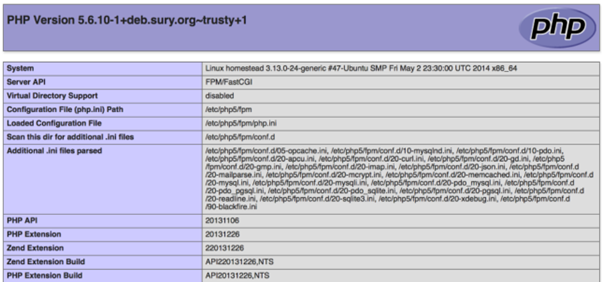
However, less extreme examples are present in many of the most common web server software packages, which may return their version numbers via a number of methods, including HTTP headers, Cookies, or HTTP metadata and source code comments.
Web application logs serve a number of purposes, in both production and development environments: in development environments specifically, they are often used to help investigate and permit the remediation of issues relating to application logic and behaviour, application performance, and other problematic application behaviours, in a process known as debugging.
Most log mechanisms in both in-house application code as well as supporting application server software permit logging to be performed at a number of configurable log levels of increasing verbosity, from “essential errors only” to “detailed information on every application function executed”. In development environments in particular, it is common to increase the verbosity of logging. This verbose logging will often not only record log output in response to a greater number of application functions, but also increase the amount of information logged for each action – often including a large amount of contextual information such as received inputs, application logic and even snippets of the relevant application code that was executed. Where the application is written in a procedural, functional or object-oriented language, these contextual code blocks can include a hierarchical or nested list of functions known as a stack trace or call stack and can provide significant information about an application.
The security implication of this is that it is often possible for attackers to access all this information about the application and gain access to large amounts of code. This is especially true if:
In order to reduce server load and client response times, it is common for a web application to implement caching at one or more layers and points in the request path. The intention is that rather than having to serve and generate a response using a (relatively resource-intensive) dynamic web application request handler, the client response – if it makes a cache “hit” by closely matching a previous request – is simply served a copy of a pre-generated response that was previously generated (and stored) in response to a previous client request: these are served by fast, static web servers that are optimised for serving such requests, and can be situated either within an organisation’s web estate, or at network edge (near the requesting client) via means of a distributed Content Distribution Network (CDN).
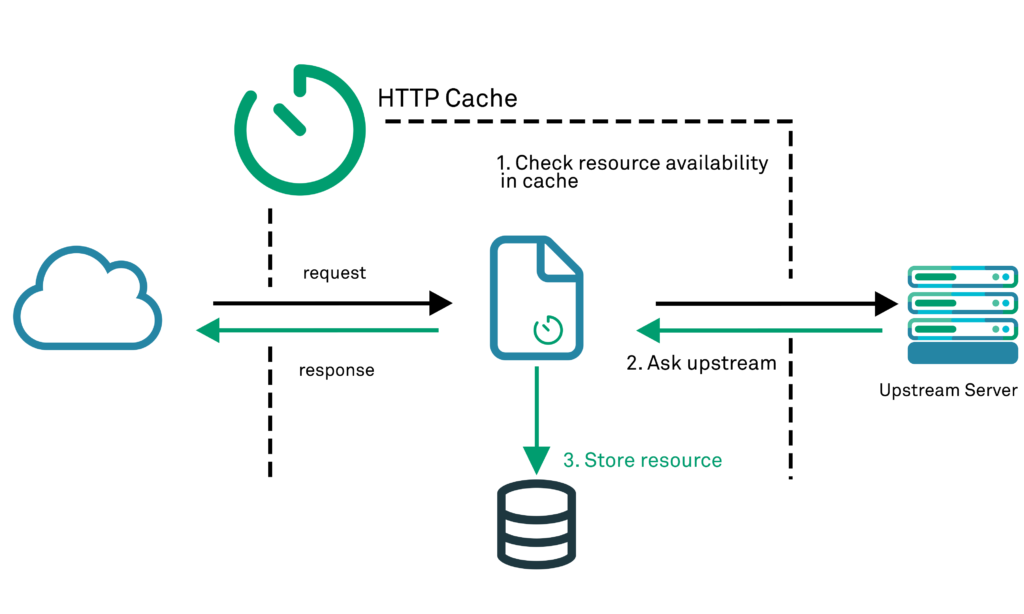
However, whilst this works well for purely static content, it can inadvertently lead to information disclosure when the content is dynamically generated. In dynamic web applications a given resource path such as “/account-history” may be contextual in that it returns dynamic information relating to the specific user making the request, and populates the response based upon the context as determined by that user’s session. A response served to one individual may therefore contain sensitive information – if a response to the URL in question is then cached and returned to a second user the sensitive information will be disclosed. This can be especially prevalent if a proxy or caching server caches responses made to HTTP requests that were made using the GET Request Method, but which contain sensitive information in their query strings.
Information disclosure as a cybersecurity term is most commonly used to describe weaknesses in which information that is useful to an attacker can be acquired passively, in that it is possible to gather it via standard HTTP requests that are undifferentiated from regular customer traffic: typical examples might include software versions being returned in HTTP headers, for example, as we saw above. However, information can also be disclosed by a system in situations where an attacker has to make active efforts in order to elicit it. The likelihood of successful exploit is lower, since an attacker’s attempts to conduct an active attack may fail, however the reward to the attacker (and hence the impact to the organisation) is often higher, since it will typically reveal access to more highly restricted information.
There are a number of forms that these active attacks can take, but perhaps the most common, and most easily exploited is simply a weak access control system for restricted resources, most commonly involving weak or missing authentication. In the case of password authentication being used to secure a resource, a number of weaknesses are possible that may allow unauthorised access to the information screened by the mechanism, including the use of weak (and easy to guess or brute force) passwords, or authentication that can be bypassed in some manner.
In a second variant, missing or weak authentication can often be exploited on an ancillary or supporting system to the one being targeted. A commonly seen example is when an organisation (or one of its contractors or outsourced development teams and agencies) opts to use a cloud system to host its source control/VCS (version control system) for its application code but fails to secure it properly. When application code is open to public access on platforms such as GitHub, an attacker can often leverage the information within it to target the primary systems that run the code.
Other commonly seen authentication and access control issues can include the inappropriate or overly broad whitelisting of IP addresses as a method of restricting access to a resource, as well as the improper handling of case sensitivity (or other logical failures) in the server-wide handler that processes request URLs, where the “/admin” path might be blacklisted for access, but an attacker that manually requests “/AdMIn” is able to bypass the check – the path resolves to the same URL, but the pattern does not match the regular expression of case statement logic being used by the access control system, for example.
In addition to databases, some webservers use simple directory-based storage for storing files provided by or requested by users and (optionally) returning them when requested. Examples might include a system that requires scanned copies of passports or driving licences to be submitted and opts to store them directly on disk within a writeable directory, rather than in a database. When using file upload (whether via HTTP or alternatives such as FTP), directory storage must define the permissions of both the hosting directory, and of each file within it. If permissions are not properly defined, then an attacker may find that they are able to either browse or request any file (even those uploaded by other users) from the commonly shared upload area or Webroot.
In a more serious variant known as directory traversal or filepath traversal an attacker may not be restricted to requesting files from the shared directory but may be able to browse the entire filesystem and return arbitrary files: if the server fails to sanitise input, then an attacker can use the “../” directive to instruct the web server to retrieve a file from one directory up in the filesystem.
Sometimes an organisation will properly secure sensitive data against direct external access, but then execute some internal process (either automated or manually) that – while it doesn’t cause the data itself to be exposed directly – nevertheless includes some information about the data: either a partial snippet of the data, a statistical analysis or other compiled summary of the data, or metadata relating to the data itself.
One of the reasons this is so common is that data gathered via web applications is incredibly useful to an organisation, in guiding or informing business decisions including marketing and sales strategies. Increasingly organisations do not simply store data, but perform some form of analysis on it, generating statistical reports, or exporting it into data warehousing solutions for processing and analysis. Since the context of each source and data classification of the original data is often lost at this stage, or not understood fully by the teams handling the data further downstream, some portion of the data can be inadvertently published or made available to a wider audience than intended.
Other systems that automatically process data for secondary functions, such as generating search indices, site navigation lists, robots.txt files, search autocomplete data and many others can also provide access to sensitive data, or information about it that is useful to attackers. A search index may for example be accessible to all and generate an openly accessible preview of indexed documents, even where the source document itself would not be accessible to an attacker if requested directly.
Dynamic web applications will often generate different HTTP responses for different clients (or to the same client at two different times) by design, as part of their function. They do so in order to provide context-specific information in the response – a simple example might be the presence of “Welcome back, [username]” text on a web application when a user logs in and returns to the homepage – if two users both request the “/”, one with see “Welcome back, Dave” and the other “Welcome back, Jill” even though they have made a request to the same URL.
This behaviour is fully expected and by design and is a fundamental underpinning of dynamic web applications. However, sometimes such differential responses can themselves disclose information that they were not intended to do, either directly, or by inference. Discrepancies can take many forms, and variations may be detectable in timing, control flow, communications such as replies or requests, or general behaviour.
Some of the more esoteric variants of this are highly technical and subtle, involving assumptions that can be made about a server’s internal state and logic based upon the time taken for a response, monitoring of fluctuating electromagnetic emanations, or performing cryptanalysis via power consumption data analysis. However, one far simpler – and more common – example is when a web application sends different responses under different circumstances to the same user (in this case an attacker), and which exposes security-relevant information about the state of the product, such as whether a particular operation was successful or not. Within login pages, for example, a web application will commonly emit differential messages in response to failed login attempts: if it replies to a failed login attempt with a specific message “that username does not exist”, but this message changes to “the password you have provided is incorrect” for a subsequent request, then the server has inadvertently disclosed to the attacker that in the second case the username provided was a valid system username.
Somewhat similar to differential responses to the same HTTP request observed within a single platform, are differential responses or behavioural discrepancies observed between different web application platforms. Whether running on a cloud platform, in-house application code, or a third-party COTS (off the shelf) application stack, every web application stack will be running slightly different software. Even where the application configuration is hardened and does not disclose anything about itself directly (such as version numbers explicitly stated in HTTP responses or other returned data or metadata), an attacker may still be able to determine the software platform and version number – and to use this information to target specific vulnerabilities.
Web application software all operates at layer 7 of the OSI model (or layer 4 of the internet protocol stack model), meaning that it implements protocols such as HTTP but also passes its data to lower layers such as Transport (data transfer) and Network (routing) layers beneath it. Both the web application software at the application layer, and the supporting network stack beneath it are implemented using different software on different operating systems and within different server environments. Each system when it is developed has to conform to certain behavioural standards and protocols in order to be able to inter-operate and communicate with other systems including requesting clients (browsers) in a predictable and compatible manner.
However, although the expected behaviour at each layer is governed by published standards known as RFCs (Requests for Comments), and there is some room for interpretation as well as poorly defined or absent specifications governing some aspects of behaviour. This ultimately means that many applications or servers will respond slightly differently and provide a pattern of behaviour in response to certain requests that essentially provides attackers with a fingerprint or footprint that they can use to establish the identity of the software being run, even where the server does not intend to explicitly disclose it.
A simple (fabricated) example might be if – for example – Apache server version 2.5 sorted HTTP headers alphabetically in responses, whether Microsoft IIS sorted the HTTP headers in reverse alphabetical order: both are valid since the order does not matter, however the subtleties in the difference of implementation allows the host system to be determined.
There are many more potential issues than we can possibly cover in a single blog post, but the last example we will mention is the potential confusion on a webserver as to whether a resource requested by a client represents a static file to return to the client, or a file containing code that should be interpreted/executed locally, and the output sent to the client. An example might be if a client requests the path http://www.example.com/admin.php from a server. The server will map or resolve this request to the file “admin.php” within its Webroot and must then determine how to service the request. Normally, when a relevant module is installed on the webserver for the language in question (in this case PHP) then the file will be passed to the PHP interpreter for execution. However, in some circumstances, the PHP file itself (the source code) that is not meant to be directly exposed is instead sent to the client, resulting in potential information disclosure.
There are a few different ways in which this can happen, including:
In all these variants, if the webserver either does not have a handler for that filetype, or else fails to recognise that it should pass the file to that handler for execution then it will typically send the contents of the file directly to the requester, rather than sending the output generated via executing that file, as was expected by the application developer.
AppCheck help you with providing assurance in your entire organisation’s security footprint. AppCheck performs comprehensive checks for a massive range of both infrastructure and web application vulnerabilities, detecting both known weaknesses published as CVEs as well as examining web application endpoints from first principle to detect vulnerabilities in in-house application code.
The AppCheck scanner will check for and detect a vast range of information disclosure issues, including those due to weak authentication, version numbering, sensitive data leaks, verbose errors, hardcoded credentials and injection vulnerabilities, all of which we examined in this blog post.
The AppCheck Vulnerability Analysis Engine provides detailed rationale behind each finding including a custom narrative to explain the detection methodology, verbose technical detail, and proof of concept evidence through safe exploitation.
AppCheck is a software security vendor based in the UK, offering a leading security scanning platform that automates the discovery of security flaws within organisations websites, applications, network, and cloud infrastructure. AppCheck are authorized by the Common Vulnerabilities and Exposures (CVE) Program as a CVE Numbering Authority (CNA).
As always, if you require any more information on this topic or want to see what unexpected vulnerabilities AppCheck can pick up in your website and applications then please get in contact with us: info@localhost